前言
用于记录刷leetcode学习各种算法的各种总结以及感想记录
比较好的leetcode刷题计划,刷完代码水平会有一个很明显的提升
-
回溯算法
-
动态规划
-
贪心算法
-
二叉树
-
图论
回溯算法
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
回溯是递归的副产品,只要有递归就会有回溯
回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
那么既然回溯法并不高效为什么还要用它呢?
一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
回溯法解决的问题都可以抽象为树形结构
溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度。
递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
一句话总结这道题的模板就是,for循环横向遍历,递归纵向遍历
组合问题
77. 组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
思路
直接的解法当然是使用for循环
但是如果n为100,k为50呢,那就50层for循环
现虽然想暴力搜索,但是用for循环嵌套连暴力都写不出来
所以回溯搜索就成为我们的选择,虽然也是暴力,但是至少可以写出来
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
result=[]#存放结果集
self.backtracking(n,k,1,[],result)
return result
def backtracking(self,n,k,startIndex,path,result):
if len(path) == k:
result.append(path[:])
return
for i in range(startIndex,n+1):
#剪枝优化 终点应该为n-(k-len(path))+1+1
path.append(i)#处理节点
self.backtracking(n,k,i+1,path,result)
path.pop()#回溯,撤销处理的节点剪枝优化
回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的
如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了
优化过程如下:
- 已经选择的元素个数:path.size();
- 所需需要的元素个数为: k - path.size();
- 列表中剩余元素(n-i) >= 所需需要的元素个数(k - path.size())
- 在集合n中至多要从该起始位置 : i <= n - (k - path.size()) + 1,开始遍历
因此只需要在for循环的终止节点修改如上即可实现
216. 组合总和 III
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
思路
思路跟上题差不多,也可抽象为n叉树,然后dfs
class Solution:
def combinationSum3(self, k: int, n: int) -> List[List[int]]:
result=[]
self.backtracking(k,n,1,[],result)
return result
def backtracking(self,k,n,sindex,path,result):
if sum(path) > n: #优化1:
return
if len(path) == k and sum(path)==n:
result.append(path[:])
for i in range(sindex,9-(k-len(path))+2):#优化2
path.append(i)
self.backtracking(k,n,i+1,path,result)
path.pop()#回溯17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
思路
首先把该问题抽象为一个树:假如给出数字234
index0: a b c
index1:def def def
index2:ghighighi ghighighi ghighighi
于是
class Solution:
def __init__(self):
self.letterMap=[
'',#0
'',#1
'abc',#2
'def',#3
'ghi',#4
'jkl',#5
'mno',#6
'pqrs',#7
'tuv',#8
'wxyz'#9
]
self.result=[]
self.s=''
def dfs(self,digits,index):
if index == len(digits):
self.result.append(self.s)
return
digit=int(digits[index])
letters=self.letterMap[digit]
for i in range(len(letters)):
self.s+=letters[i]#存储这一层的值,并进入下一层树
self.dfs(digits,index+1)
self.s=self.s[:-1] #回溯到上一步
def letterCombinations(self, digits: str) -> List[str]:
if len(digits)==0:
return self.result
self.dfs(digits,0)
return self.result39. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
思路
-
本题和77.组合 (opens new window),216.组合总和III (opens new window)的区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
-
本题搜索的过程抽象成树形结构:
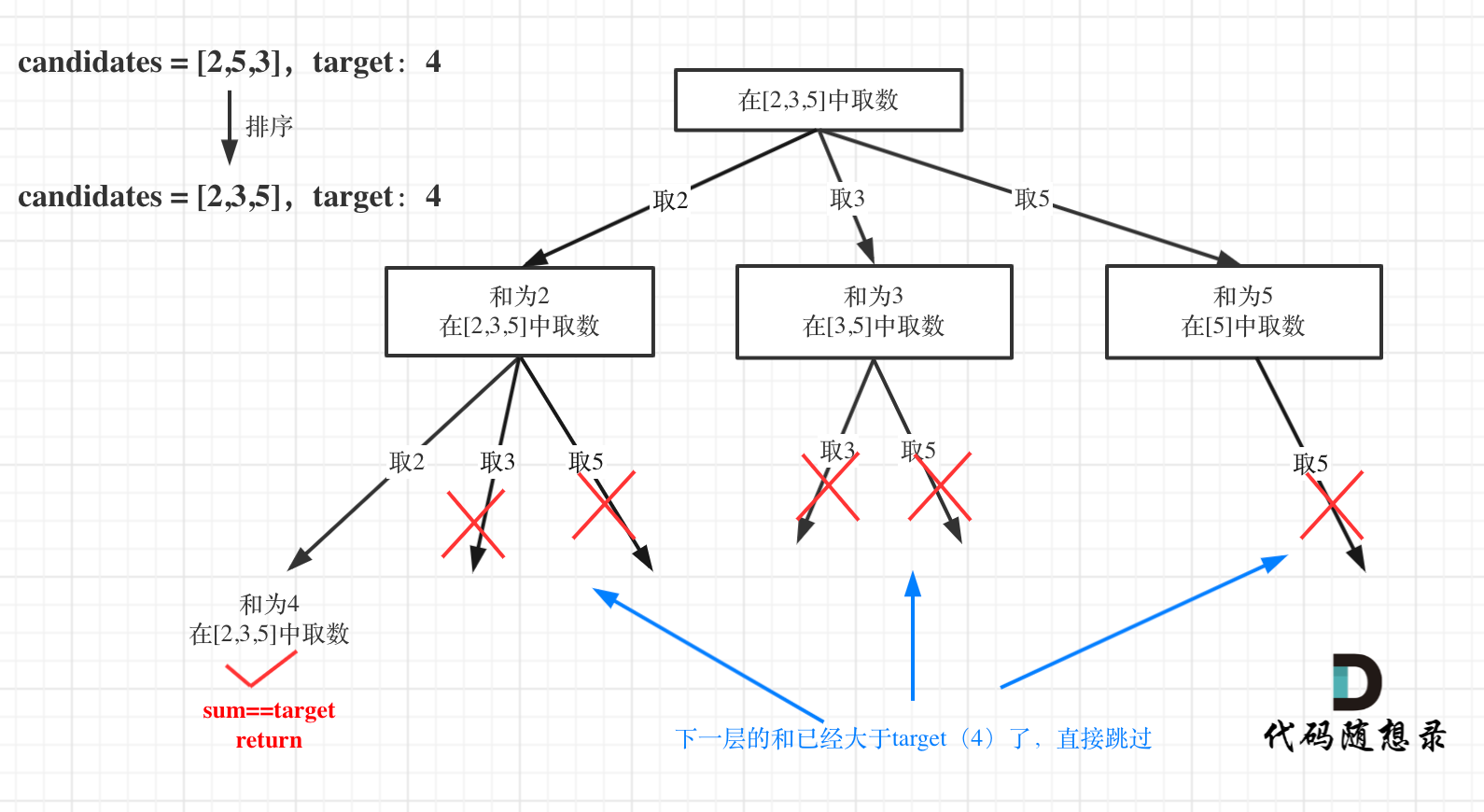
于是
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
result=[]
self.dfs(candidates,target,0,0,[],result)
return result
def dfs(self,candidates,target,total,sIndex,path,result):
if total > target:
return
if total == target:
result.append(path[:])
return
for i in range(sIndex,len(candidates)):
total+=candidates[i]
path.append(candidates[i])
self.dfs(candidates,target,total,i,path,result)#可以重复选取,sindex取i
total-=candidates[i] #进行回溯操作
path.pop()40. 组合总和 II
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
**注意:**解集不能包含重复的组合。
思路
其实就是上题的改编版,区别在于元素不能重复,但是想了好久还是不明白怎么进行树层的去重
实际上可以类比三数之和,先排序,利用双指针,遇到与前一项相等的数值就直接退出进行下一次遍历
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
result=[]
if len(candidates) ==0 :
return []
candidates.sort()
self.dfs2(candidates,target,0,0,[],result)
return result
def dfs2(self,candidates,target,total,sIndex,path,result):
if total > target:
return
if total == target:
result.append(path[:])
return
for i in range(sIndex,len(candidates)):
if i > sIndex and candidates[i-1]==candidates[i]: #
continue
total+=candidates[i]
path.append(candidates[i])
self.dfs2(candidates,target,total,i+1,path,result)#不可以重复选取,sindex取i+1
total-=candidates[i] #进行回溯操作
path.pop()分割问题
131. 分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
思路
class Solution:
def partition(self, s: str) -> List[List[str]]:
result=[]
n=len(s)
path=[]
def dfs(i,start):
if i==n:
result.append(path.copy())
return
if i<n-1:
dfs(i+1,start)
temp=s[start:i+1]
if temp==temp[::-1]:#判断回文
path.append(temp)
dfs(i+1,i+1) #遍历下一个字符串
path.pop() #回溯
dfs(0,0)
return result93. 复原 IP 地址
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
- 例如:
"0.1.2.201"和"192.168.1.1"是 有效 IP 地址,但是"0.011.255.245"、"192.168.1.312"和"192.168@1.1"是 无效 IP 地址。
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 '.' 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
思路
实际上相当于给字符串中加上四个逗号
写回溯算法的关键还是要思路清晰,逻辑正确那么结果就一定正确
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
#假设插入4个逗号
#index代表开始插入的下标
#dots代表已经插入的逗号数
result=[]
if len(s) > 12:
return []
def backTrack(index,dots,curIP):
if dots ==4 and index == len(s):
result.append(curIP[:-1])
return
if dots >4:
return
for i in range(index,min(index+3,len(s))):
if int(s[index:i+1]) <=255 and (s[index]!='0' or i==index ) :
backTrack(i+1,dots+1,curIP+s[index:i+1]+'.')
backTrack(0,0,'')
return result子集问题
78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集
思路
from typing import List
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
result = [[]]
if len(nums) == 0:
return result
def dfs(index, path):
for i in range(index, len(nums)):
path.append(nums[i])
result.append(path[:])
dfs(i + 1, path)
path.pop()
dfs(0, [])
return result90. 子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
思路
这道题目和78.子集 区别就是集合里有重复元素了,而且求取的子集要去重。
**去重的关键:**一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
(注意去重需要先对集合排序)去重的思路与回溯算法:求组合总和(三)大体相同
class Solution:
def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
nums.sort()
result = [[]]
if len(nums) == 0:
return result
def dfs(index, path):
for i in range(index, len(nums)):
if nums[i]==nums[i-1] and i > index: #树层去重
path.append(nums[i])
result.append(path[:])
dfs(i + 1, path)
path.pop()
dfs(0, [])
return result491.递增子序列
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。
数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
思路
一个递增子序列 path 怎么产生?它的元素是从 nums 中一个个选的。
比如 [4,2,7,7],path 选第一个数,有 4 种选择:从nums[0]到nums[3]。
选了nums[i]之后,会在nums[i+1]到末尾的数中,再选下一个……
以此类推,直到没得选为止。当 path 满足要求,就可以加入解集,这是递归回溯的思路。
定义递归函数:在从下标 start 到末尾的子数组中选合适的数推入 path。path 也作为参数。在递归过程中,不断选数字入 path。
递归函数中,通过 for 循环枚举出当前的所有选择——(展开不同的递归分支)。
选择了一个数,推入 path,往下继续选择(继续递归)。
当 start 指针到达边界,能选的都选了,没有数字可选了,结束递归。
基于当前选择的递归,已经考察了所有可能,这时会回溯,path 要撤销最末尾的数字,切入别的分支。
class Solution:
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
result=[]
if len(nums) ==0:
return []
def dfs(index,path):
#由于返回的是该数组中不同的递增子序列,并且递增子序列中至少有两个元素,需要进行树层去重
if len(path) >=2:
result.append(path[:])
#这里不要取return,要取树上的节点
uset=set()
for i in range(index,len(nums)):
if path and nums[i]<path[-1] or nums[i] in uset:
continue
path.append(nums[i])
uset.add(nums[i]) #记录这个元素在本层中已经用过了
dfs(i+1,path)
path.pop()
dfs(0,[])
return result排列问题
46. 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
思路
抽象为树,每次都是从0开始遍历
这题的主要考点就是进行树枝去重
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
result=[]
used=[False]*len(nums)
if len(nums) == 0:
return []
def dfs(index,path):
if len(path) == len(nums):
result.append(path[:])
return
for j in range(0,len(nums)):
if used[j]: #进行树枝去重
continue
path.append(nums[j])
used[j]=True
dfs(0,path)
used[j]=False
path.pop()
dfs(0,[])
return result47. 全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
思路
与上题类似,把树枝去重改成树层去重即可
树层去重有两种方法:1.采用used数组记录状态2.先排序,利用双指针进行去重
于是
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
result=[]
if len(nums)==0:
return []
used=[False]*len(nums)
nums.sort()
def dfs(index,path):
if len(path) == len(nums):
result.append(path[:])
return
for i in range(index,len(nums)):
if (i > 0 and nums[i]==nums[i-1] and used[i-1])or used[i]: #进行树层去重,还要进行树枝去重
continue
used[i]=True
path.append(nums[i])
dfs(0,path)
used[i]=False
path.pop()
dfs(0,[])
return result这段代码去重的关键在与
if (i > 0 and nums[i]==nums[i-1] and used[i-1])or used[i]
'''
进行详细解释:
nums[i]==nums[i-1] 代表着树层去重
or used[i] 是进行树枝去重
而and used[i-1] 或者说可以写出 and not used[i+1]
条件 not used[i-1] 的目的是确保算法在处理输入数组 nums 中的重复元素时不会跳过考虑某个递归树的特定分支。让我们在代码上下文中详细解释这个条件的目的:
在同一层次的重复检查(树的分支):
条件 (i > 0 and nums[i]==nums[i-1] and not used[i-1]) 检查在同一层次(在递归树的同一分支中)是否存在重复元素。
如果 nums[i] 与 nums[i-1] 相同(重复元素),且 used[i-1] 为 False(表示在当前分支中前一个元素未被使用),则跳过该分支以避免生成重复的排列。
示例:
考虑输入数组 nums = [1, 1, 2]。
如果没有条件 not used[i-1],算法可能会生成重复的排列,比如 [1, 1, 2],因为第一个 1 可以选择在位置 0 或 1。该条件通过确保仅在第一次出现的 1 已被使用时考虑第二次出现的 1,从而防止了这种情况。
总体重复避免策略:
整个条件 (i > 0 and nums[i]==nums[i-1] and not used[i-1]) 是处理在递归树的同一层次(同一分支)和不同层次(不同分支)上的重复元素的策略的一部分。
used 数组跟踪在特定层次使用的元素,该条件有助于跳过某些分支,以避免生成重复的排列。
'''332. 重新安排行程
给你一份航线列表 tickets ,其中 tickets[i] = [fromi, toi] 表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。
所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。
- 例如,行程
["JFK", "LGA"]与["JFK", "LGB"]相比就更小,排序更靠前。
假定所有机票至少存在一种合理的行程。且所有的机票 必须都用一次 且 只能用一次。
思路
# 核心思想--深度搜索+回溯
# 首先先把图的邻接表存进字典,然后对字典的value进行排序
# 然后从'JFK'开始深搜,每前进一层就减去一条路径,
# 直到某个节点不存通往其他节点的路径时,说明该节点就为此次行程的终点
# 需要跳出while循环进行回溯,返回到上一层节点进行搜索,再次找到倒数第二个终点,依次类推
# 设定ans为返回答案,每次找到的节点都要往头部插入
# 举例说明:[["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
# 构建领接表的字典:{'JFK': ['SFO', 'ATL'], 'SFO': ['ATL'], 'ATL': ['JFK', 'SFO']})
# 按照题目要求对字典的val排序:{'JFK': ['ATL', 'SFO'], 'SFO': ['ATL'], 'ATL': ['JFK', 'SFO']})
# 开始从 JFL 开始进行dfs搜索
# 1.JFK --> ALT
# JFK pop出ALT,JFK的字典变为:'JFK': ['SFO']
# 2.JFK --> ALT --> JFK
# ALT pop出JFK,ALT的字典变为:'ALT': ['SFO']
# 3.JFK --> ALT --> JFK --> SFO
# JFK pop出SFO,JFK的字典变为:'JFK': ['']
# 4.JFK --> ALT --> JFK --> SFO --> ATL
# SFO pop出ALT,SFO的字典变为:'SFO': ['']
# 5.JFK --> ALT --> JFK --> SFO --> ATL --> SFO
# ATL pop出SFO,ATL的字典变为:'ATL': ['']
# 此时我们可以发现SFO的val为空,没有地方可以去了,说明我们已经找出了终点SFO
# 然后向上回溯,依次将其添加到ans中
# 最终答案为:["JFK","ATL","JFK","SFO","ATL","SFO"]
import collections
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
d = collections.defaultdict(list) #邻接表
for f, t in tickets:
d[f] += [t] # 路径存进邻接表
for f in d:
d[f].sort() # 邻接表排序
ans = []
def dfs(f): # 深搜函数
while d[f]:
dfs(d[f].pop(0)) # 路径检索
ans.insert(0, f) # 放在最前
dfs('JFK')
return ans棋盘问题
51. N 皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
思路
rows相当于index,相当与树的递归深度,而cols在每一层遍历,回溯每次下的Q即可,手搓一个dfs
虽然速度只打败百分17的人,算法还需要优化,不过第一次手撕出来,还是有点高兴的
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
result=[]
#初始化一个棋盘
board=[['.'for j in range(n)]for i in range(n)]
#进行dfs
#index == rows
def islegal(index,cols):
#理论上cols不可能冲突
#检测rows冲突
if index >=0 and cols >=0:
for i in range(index):
if i>=0 and board[i][cols]=='Q':
return False
#检测左上是否冲突
for i,j in zip(tuple(range(index-1, -1, -1)),tuple(range(cols-1, -1, -1))): # 修改这一行
if i>=0 and board[i][j]=='Q':
return False
#检测右上是否冲突
for i,j in zip(tuple(range(index-1, -1, -1)),tuple(range(cols+1,n, 1))): # 修改这一行
if i>=0 and board[i][j]=='Q':
return False
return True
def dfs(index):
if index == n:
path=[]
for i in range(n):
path.append("".join(board[i]))
result.append(path)
return
for cols in range(n):
if islegal(index,cols):
board[index][cols]='Q'
dfs(index+1)
board[index][cols]='.'
dfs(0)
return result优化的思路
- 可以用一个一维数组来存储每一行皇后的列位置,而不是用一个二维数组来表示整个棋盘。这样可以节省空间,也可以简化判断是否合法的逻辑。
- 可以用位运算来加速判断是否合法的过程。具体地,你可以用三个整数来分别记录每一列,每一条主对角线,和每一条副对角线上是否已经有皇后。每次放置一个皇后时,你只需要检查当前位置的列,主对角线,和副对角线是否为 0,如果是,说明可以放置,然后更新这三个整数的相应位为 1。这样可以避免使用循环和数组索引,提高效率
- 可以用一个全局变量来记录最终的结果,而不是作为参数传递。这样可以避免不必要的拷贝,也可以简化函数的参数列表。
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
# 用一个全局变量来存储结果
self.result = []
# 用一个一维数组来存储每一行皇后的列位置
board = [-1] * n
# 用三个整数来分别记录每一列,每一条主对角线,和每一条副对角线上是否已经有皇后
# 用位运算来加速判断和更新
self.cols = 0
self.diag1 = 0
self.diag2 = 0
# 从第 0 行开始回溯
self.dfs(0, n, board)
return self.result
def dfs(self, row, n, board):
# 如果已经到达最后一行,说明找到了一个解
if row == n:
# 根据 board 数组生成棋盘字符串
path = []
for i in range(n):
s = "." * board[i] + "Q" + "." * (n - board[i] - 1)
path.append(s)
# 将结果添加到全局变量中
self.result.append(path)
return
# 遍历当前行的每一列
for col in range(n):
# 计算当前位置的主对角线和副对角线的索引
d1 = row + col
d2 = row - col + n - 1
# 用位运算判断当前位置的列,主对角线,和副对角线是否为空
if (self.cols >> col) & 1 == 0 and (self.diag1 >> d1) & 1 == 0 and (self.diag2 >> d2) & 1 == 0:
# 如果为空,说明可以放置皇后
# 更新 board 数组
board[row] = col
# 更新三个整数,将相应的位设为 1
self.cols |= 1 << col
self.diag1 |= 1 << d1
self.diag2 |= 1 << d2
# 继续下一行的回溯
self.dfs(row + 1, n, board)
# 回溯后,恢复 board 数组和三个整数的状态,将相应的位设为 0
board[row] = -1
self.cols &= ~(1 << col)
self.diag1 &= ~(1 << d1)
self.diag2 &= ~(1 << d2)
37. 解数独
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
思路
与N皇后十分相似,这题的解法也很明显,就是一个一个试,知道所有格子都填满,但是不同的在于,每一行每一列都需要遍历,所以这是二维回溯,前面的都是一维的回溯
class Solution:
def solveSudoku(self, board: List[List[str]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
rows=len(board)
cols=len(board[0])
def dfs(board):
#若有解返回True 无解则返回False
for row in range(rows):
for col in range(cols):
#若格子里面有数字就直接跳过
if board[row][col]!='.':
continue
#逐个从1-9的数字中尝试填入这个格子
for k in range(1,10):
if isValid(row,col,k):
board[row][col]=str(k)
#填入下一个
if dfs(board):
return True
#回溯
board[row][col]='.'
#如果9个数字都填过,说明这一步就无解,回溯到上一格子填入其他数字
return False
#递归结束 有解
return True
def isValid(row,col,k):
#同一列无重复的,范围一定是0-8 预设的还会有数字
for i in range(9):
if board[i][col] == str(k):
return False
#同一行无重复
for j in range(9):
if board[row][j] == str(k):
return False
#3X3九宫格无重复
startRow=(row//3)*3
startCol=(col//3)*3
for i in range(startRow,startRow+3):
for j in range(startCol,startCol+3):
if board[i][j] == str(k):
return False
#如何这些限制条件都符合就可以放置
return True
dfs(board)提交,过了,400多ms,尝试一下优化
优化
- 初始化9个行set 快速查找行内是否存在重复,就不必n^2的查重操作了
- 9个列set 同理
- 9个块set
- 用一个empty_list存一下需要填的位置
- 开始回溯, 每次只放不重复的元素, 如果找到结果立刻返回, 不需要再多余计算
- 最后把结果填进原数组即可
class Solution:
def solveSudoku(self, board: List[List[str]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
lines = [set() for _ in range(9)]
cols = [set() for _ in range(9)]
sqs = [set() for _ in range(9)]
empty_list = []
for i, line in enumerate(board):
for j, ch in enumerate(line):
if ch == '.':
empty_list.append((i, j))
else:
lines[i].add(ch)
cols[j].add(ch)
sqs[(i // 3) * 3 + (j // 3)].add(ch)
res = []
def dfs(k):
if k == len(empty_list):
return True
i, j = empty_list[k]
for ch in '123456789':
if not (ch in lines[i] or ch in cols[j] or ch in sqs[(i // 3) * 3 + (j // 3)]):
lines[i].add(ch)
cols[j].add(ch)
sqs[(i // 3) * 3 + (j // 3)].add(ch)
res.append(ch)
if dfs(k+1):
return True
res.pop()
lines[i].remove(ch)
cols[j].remove(ch)
sqs[(i // 3) * 3 + (j // 3)].remove(ch)
return False
dfs(0)
for (i, j), r in zip(empty_list, res):
board[i][j] = r总结
-
回溯是递归的副产品,只要有递归就会有回溯,所以回溯法也经常和二叉树遍历,其实抽象结构两者是相同的
-
用递归控制for循环嵌套的数量
-
搜索的过程:for循环横向遍历,递归纵向遍历,回溯不断调整结果集
-
剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够题目要求的k个元素了,就没有必要搜索了。
-
集合元素会有重复,但要求解集不能包含重复的组合:**“树枝去重”和“树层去重”**组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。
-
也可以使用set针对同一父节点本层去重,但子集问题一定要排序
-
使用used数组在时间复杂度上几乎没有额外负担!
-
深度优先搜索也是用递归来实现的,所以往往伴随着回溯。
-
单纯的回溯搜索(深搜)并不难,难还难在容器的选择和使用上
-
棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了。
-
子集问题分析:
- 时间复杂度:O(2n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2n)
- 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
排列问题分析:
- 时间复杂度:O(n!),这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * … 1 = n!。
- 空间复杂度:O(n),和子集问题同理。
组合问题分析:
- 时间复杂度:O(2^n),组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
- 空间复杂度:O(n),和子集问题同理。
N皇后问题分析:
- 时间复杂度:O(n!) ,其实如果看树形图的话,直觉上是O(n^n),但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * … * 1。
- 空间复杂度:O(n),和子集问题同理。
解数独问题分析:
- 时间复杂度:O(9^m) , m是’.'的数目。
- 空间复杂度:O(n2),递归的深度是n2
-
117233
动态规划(基础版)
斐波那契型
746. 使用最小花费爬楼梯
给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
class Solution:
def minCostClimbingStairs(self, cost: List[int]) -> int:
n=len(cost)
dp=[0 for i in range(n+2)]
for i in range(2,n+1):
dp[i]=min(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2])
return dp[n]最基础的动态规划了吧,,,
写出最简单的状态转移方程就行了
198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
思路
偷k间房子的最大价值:可分解为2种偷法
- 偷第k间+前k-2间房子最大价值
- 不偷第k间+前k-1间房子的最大价值
根据此就可列出状态转移方程
class Solution:
def rob(self, nums: List[int]) -> int:
n=len(nums)
dp=[0 for i in range(n+1)]
dp[0]=0
dp[1]=nums[0]
for i in range(1,n):
dp[i+1]=max(dp[i],nums[i]+dp[i-1])
return dp[n]由于每次计算都只用了两个值
还可进一步优化空间复杂度为O(1)
class Solution:
def rob(self, nums: List[int]) -> int:
n=len(nums)
prev=0
current=nums[0]
for i in range(1,n):
prev,current=current,max(nums[i]+prev,current)
return current740. 删除并获得点数
给你一个整数数组 nums ,你可以对它进行一些操作。
每次操作中,选择任意一个 nums[i] ,删除它并获得 nums[i] 的点数。之后,你必须删除 所有 等于 nums[i] - 1 和 nums[i] + 1 的元素。
开始你拥有 0 个点数。返回你能通过这些操作获得的最大点数。
思路
才看题目的时候是挺懵b的,根本不知道怎么写状态方程
但实际上我们从1开始计算
会发现其实和打家劫舍是有共通点的:
相同点
- 打家劫舍中是相邻的房子不能连续偷。
- 这个题是相邻的数字不能同时拿(拿一个相邻的就删除了。)
不同点
- 前者打家劫舍是有房子的金额,如果我们能够算出这个题目中的“金额”我们就能够迎刃而解。
怎么算金额呢?实际上金额就是 数字i出现的次数*i
那么就可以类比写出状态方程:
f[i]=max(f[i-2]+cnt[i]*i,f[i-1])
那么这题就很清晰了
class Solution:
def deleteAndEarn(self, nums: List[int]) -> int:
cnt=[0]*10010
m=max(nums)
#统计数字出现的次数
for i in nums:
cnt[i]+=1
dp=[0]*10002
#特殊情况的处理
dp[1]=cnt[1]*1
dp[2]=max(cnt[2]*2,dp[1])
for i in range(3,m+1):
dp[i]=max(dp[i-1],dp[i-2]+cnt[i]*i)
return dp[m]矩阵
62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
思路
梦回高中了,属于是
利用排列组合的知识,可以得到路径的递推关系:
dp[i][j]=dp[i-1][j]+dp[j-1][i]#dp代表(i,j)的路径数于是
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
#生成一个二维数组,最上边的一行路径都是1
#在dp里面直接把特殊情况给处理了
dp=[[1]*n]+[[1]+[0]*(n-1) for _ in range(m-1)]
for i in range(1,m):
for j in range(1,n):
dp[i][j]=dp[i-1][j]+dp[i][j-1]
return dp[m-1][n-1]进一步优化空间复杂度,把空间复杂度降到O(n)
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
cur = [1] * n
for i in range(1, m):
for j in range(1, n):
cur[j] += cur[j-1]
return cur[-1]64. 最小路径和
给定一个包含非负整数的 *m* x *n* 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
**说明:**每次只能向下或者向右移动一步。
思路
是上一题的加强版,稍加修改就行了
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+values[i][j]于是
class Solution:
def minPathSum(self, grid: List[List[int]]) -> int:
#m=Rows
m=len(grid)
#n=cols
n=len(grid[0])
dp=[[0 for i in range(n)]for i in range(m)]
#先计算边上的:
dp[0][0]=grid[0][0]
for j in range(1,n):
dp[0][j]=grid[0][j]+dp[0][j-1]
for i in range(1,m):
dp[i][0]=grid[i][0]+dp[i-1][0]
for i in range(1,m):
for j in range(1,n):
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+grid[i][j]
return dp[-1][-1]63. 不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
思路
是62的plus版
障碍处理:
有障碍 = 此路不通 = 此格没有路线 = 此格路线数为0
由于初始化每一格路线数 = 0,
所以遇到障碍格,不更新该格即可。
我考虑直接在障碍图上进行处理
当然也可以单独开个二维表存储路线,不过有点浪费空间
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
#生成一个二维数组,最上边的一行路径都是1
#在dp里面直接把特殊情况给处理了
m=len(obstacleGrid)
n=len(obstacleGrid[0])
if obstacleGrid[0][0]==1:
return 0
#在障碍图的基础上填充路线
for i in range(m):
for j in range(n):
if (i==0)&(j==0):
obstacleGrid[0][0]=1
#在这里要多一些对于特殊情况的处理
else:
#利用dp累加路线,在这里优先级很重要
#要先判断该位置是否有障碍物然后进行处理
#if elif如果条件都满足只执行if
if obstacleGrid[i][j]==1:
obstacleGrid[i][j]=0
elif i==0:
obstacleGrid[i][j]=obstacleGrid[i][j-1]
elif j==0:
obstacleGrid[i][j]=obstacleGrid[i-1][j]
else:
obstacleGrid[i][j]=obstacleGrid[i-1][j]+obstacleGrid[i][j-1]
return obstacleGrid[-1][-1]120. 三角形最小路径和
给定一个三角形 triangle ,找出自顶向下的最小路径和。
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
思路
很容易可以想到状态方程如下:设坐标(i,j)
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j]) #j不在两端
dp[i][j]=dp[i-1][j] #j=0
dp[i][j]=dp[i-1][j-1] #j=n[m]于是
class Solution:
def minimumTotal(self, triangle: List[List[int]]) -> int:
#m=Rows n=Col
m=len(triangle)
n=[len(triangle[i]) for i in range(m)] #n是存储m行cols的列表
#设置一个dp存储路径数 valueList=List
dp=[[0 for i in range(n[i])]for i in range(m)]
#状态方程dp
#先处理极端情况
for i in range(m):
for j in range(n[i]):
if (i==0)&(j==0):
dp[i][j]=triangle[i][j]
else:
if j==0:
dp[i][j]=dp[i-1][j]+triangle[i][j]
elif j==n[i]-1:
dp[i][j]=dp[i-1][j-1]+triangle[i][j]
else:
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j])+triangle[i][j]
return min(dp[-1])这种套路题关键点就是找状态方程,以及特殊情况的处理
931. 下降路径最小和
给你一个 `n x n` 的 **方形** 整数数组 `matrix` ,请你找出并返回通过 `matrix` 的**下降路径** 的 **最小和** 。
**下降路径** 可以从第一行中的任何元素开始,并从每一行中选择一个元素。在下一行选择的元素和当前行所选元素最多相隔一列(即位于正下方或者沿对角线向左或者向右的第一个元素)。具体来说,位置 `(row, col)` 的下一个元素应当是 `(row + 1, col - 1)`、`(row + 1, col)` 或者 `(row + 1, col + 1)` 。思路
有比较明显的递推关系,分解子问题,就能写出来递推关系
于是
class Solution:
def minFallingPathSum(self, matrix: List[List[int]]) -> int:
#m=rows n=cols
m=len(matrix)
n=len(matrix[0])
dp=[[0 for i in range(n)] for i in range(m)]
for i in range(m):
for j in range(n):
if i ==0:
dp[i][j]=matrix[i][j]
elif j==0:
dp[i][j]=min(dp[i-1][j],dp[i-1][j+1])+matrix[i][j]
elif j==n-1:
dp[i][j]=min(dp[i-1][j],dp[i-1][j-1])+matrix[i][j]
else:
dp[i][j]=min(dp[i-1][j],dp[i-1][j-1],dp[i-1][j+1])+matrix[i][j]
return min(dp[-1])221. 最大正方
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积。
思路
这个题…想了几十分钟。。。。
感觉需要很强的抽象能力才能划分成子问题
-
重新开个dp存储最大正方形的边长
-
设置dp[i] [j]为以(i,j)为右下角最大正方形的边长
当且仅当该位置为1的时候才存在正方形此处可以构成的最大正方形的边长,是其正上方,左侧,和左上界三者共同约束的,且为三者中的最小值加1。
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i][j-1])+1于是
class Solution:
def maximalSquare(self, matrix: List[List[str]]) -> int:
m=len(matrix)
n=len(matrix[0])
dp=[[0 for i in range(n)] for i in range(m)]
for i in range(m):
for j in range(n):
if matrix[i][j]=='0':
dp[i][j]=0
else:
if (i==0)&(j==0):
dp[i][j]=1
else:
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i][j-1])+1
max2=0
for i in range(m):
temp=max(dp[i])
if temp > max2:
max2=temp
return max2*max2字符串
5. 最长回文子串
给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
思路
最初的思路是暴力枚举
但是复杂度是n**3,想着有没有更好的算法
虽然但是,我觉得这题用dp还是不太好理解
中心拓展的方法更直观
class Solution:
def expandAroundCenter(self,s,l,r):
while l>=0 and r<len(s) and s[l]==s[r]:
l-=1
r+=1
return l+1,r-1
def longestPalindrome(self, s: str) -> str:
start,end=0,0
n=len(s)
for i in range(n):
l1,r1=self.expandAroundCenter(s,i,i)#拓展奇数回文子串
l2,r2=self.expandAroundCenter(s,i,i+1)#拓展偶数回文子串
if r1-l1 > end-start:
end,start=r1,l1
if r2-l2 >end -start:
end,start=r2,l2
return s[start:end+1]dp思路
方法二:动态规划
回文天然具有「状态转移」性质:一个长度严格大于 222 的回文去掉头尾字符以后,剩下的部分依然是回文。反之,如果一个字符串头尾两个字符都不相等,那么这个字符串一定不是回文。「动态规划」的方法根据这样的性质得到。
第 1 步:定义状态
dp[i][j] 表示:子串 s[i..j] 是否为回文子串,这里子串 s[i..j] 定义为左闭右闭区间,即可以取到 s[i] 和 s[j]。
第 2 步:思考状态转移方程
根据头尾字符是否相等,需要分类讨论:
dp[i][j] = (s[i] == s[j]) and dp[i + 1][j - 1]
说明:
「动态规划」的「自底向上」求解问题的思路,很多时候是在填写一张二维表格。由于 s[i..j] 表示 s 的一个子串,因此 i 和 j 的关系是 i <= j,只需要填这张表格对角线以上的部分;
看到 dp[i + 1][j - 1] 就需要考虑特殊情况:如果去掉 s[i..j] 头尾两个字符子串 s[i + 1..j - 1] 的长度严格小于 222(不构成区间),即 j−1−(i+1)+1<2j - 1 - (i + 1) + 1 < 2j−1−(i+1)+1<2 时,整理得 j−i<3j - i < 3j−i<3,此时 s[i..j] 是否是回文只取决于 s[i] 与 s[j] 是否相等。结论也比较直观:j−i<3j - i < 3j−i<3 等价于 j−i+1<4j - i + 1 < 4j−i+1<4,即当子串 s[i..j]s[i..j]s[i..j] 的长度等于 222 或者等于 333 的时候,s[i..j] 是否是回文由 s[i] 与 s[j] 是否相等决定。
第 3 步:考虑初始化
单个字符一定是回文串,因此把对角线先初始化为 true,即 dp[i][i] = true。根据第 2 步的说明:当 s[i..j] 的长度为 222 时,只需要判断 s[i] 是否等于 s[j],所以二维表格对角线上的数值不会被参考。所以不设置 dp[i][i] = true 也能得到正确结论。
第 4 步:考虑输出
一旦得到 dp[i][j] = true,就记录子串的「长度」和「起始位置」。没有必要截取,这是因为截取字符串也有性能消耗。
第 5 步:考虑优化空间
下面给出的「参考代码」,在填表的过程中,只参考了左下方的数值。事实上可以优化,但是增加了代码编写和理解的难度,丢失了可读性和可解释性。在这里不做优化空间;
填表应该遵守这样的原则:总是先得到小子串是否是回文的结果,然后大子串才能参考小子串的判断结果,所以填表顺序很重要;
建议自己动手,画一下表格,相信会对「动态规划」作为一种「表格法」有更好的理解。class Solution:
def longestPalindrome(self, s: str) -> str:
n=len(s)
dp=[[i == j for j in range(n)] for i in range(n)]
#先枚举子串长度
maxlen=1
begin=0
if n < 2:
return s
for L in range(2,n+1):
#枚举左边界
for i in range(n):
#由L,i确定右边界:
j=L+i-1
#如果越界:
if j>=n:
break
if s[i]==s[j]:
if j-i <3:
dp[i][j]=True
else:
dp[i][j]=dp[i+1][j-1]
else:
dp[i][j]=False
if dp[i][j]and j-i+1>maxlen:
maxlen=j-i+1
begin=i
return s[begin:begin+maxlen]139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
**注意:**不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
刚开始的思路是这样的
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
flag=False
i=0
j=0
while not flag:
if i<=len(s)-1 and j <=len(s)-1:
if s[i:j+1] in wordDict:
i=j+1
j=j+1
continue
if i>len(s)-1 and j>len(s)-1:
flag=True
elif j>len(s)-1 and i <=len(s)-1:
break
j+=1
return flag就是逐个截取
但是
输入
s ="aaaaaaa"
wordDict =["aaaa","aaa"] 直接寄了,因为每次先读取aaa aaa+aaa+a不符合还是想到用动态规划
我们需要判断一个字符串是否可以由一个字典中的多个单词组合而成,这自然让人想到将问题拆分成更小的子问题。
具体来说,我们可以考虑字符串的每一个子串,看它是否可以由字典中的单词组成,这可以通过检查之前的子串是否能由字典中的单词组成来实现,从而形成了子问题间的依赖关系。
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
# 创建一个长度为 len(s) + 1 的布尔型数组 dp
dp = [False] * (len(s) + 1)
# 空字符串总是可以被表示,因此 dp[0] 设为 True
dp[0] = True
# 遍历字符串 s 的每个子字符串
for i in range(1, len(s) + 1):
# 遍历字典 wordDict 中的每个单词
for word in wordDict:
# 检查以 i 结尾的子字符串是否可以由 wordDict 中的单词组成
# 条件:dp[i - len(word)] 为 True 且 s 的子字符串与 word 匹配
if i>= len(word) and dp[i - len(word)] and s[i - len(word):i] == word:
# 如果可以,将 dp[i] 设置为 True,并跳出循环
dp[i] = True
break
# 返回 dp[len(s)] 的值,表示整个字符串 s 是否可以由 wordDict 中的单词组成
return dp[len(s)]516. 最长回文子序列
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
思路
设置dp[i][j]为字符串s在下标区间i,j之间的最长回文长度
dp[i][j]=dp[i+1][j-1]+2 当s[i]=s[j]
dp[i][j]=max(dp[i+1][j],dp[i][j-1]) 当s[i]!=s[j]
然后根据图标确定约束关系,确定遍历顺序比较重要
从递推公式dp[i][j] = dp[i + 1][j - 1] + 2 和 dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) 可以看出,dp[i][j]是依赖于dp[i + 1][j - 1] 和 dp[i + 1][j],
也就是从矩阵的角度来说,dp[i][j] 下一行的数据。 所以遍历i的时候一定要从下到上遍历,这样才能保证,下一行的数据是经过计算的。
如果i<j则认为数据不合法dp[i][j]=0class Solution:
def longestPalindromeSubseq(self, s: str) -> int:
n=len(s)
dp=[[0 for i in range(n)]for i in range(n)]
for i in range(n-1,-1,-1):
#单个字符的长度都是1
dp[i][i]=1
for j in range(i+1,n):
if s[i]==s[j]:
dp[i][j]=dp[i+1][j-1]+2
else:
dp[i][j]=max(dp[i+1][j],dp[i][j-1])
return dp[0][-1]72. 编辑距离
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
现在定义dp[i][j] 代表 word1 中前 i 个字符,变换到 word2 中前 j 个字符,最短需要操作的次数;”
现在再来理解“dp[i-1][j-1] 表示替换操作,dp[i-1][j] 表示删除操作,dp[i][j-1] 表示插入操作。”
dp[i-1][j-1] (表示替换):word1的前i-1个字符已经变换到word2的前j-1个字符的次数,说明word1的前i-1个和word2的前j-1个字符已经完成操作;那么对于word1的第i个怎么变成word2的第j个呢?这两个字符都存在,那么只能是替换了;所以dp[i][j] = dp[i-1][j-1]+1;
dp[i][j-1] (表示插入):word1的前i个字符已经变换到word2的前j-1个字符的次数,当前word1的第i步字符已经用了,但是word2还差一个字符(因为当前只是处理了word2的前j-1个字符),那么插入一个字符就好了;所以dp[i][j] = dp[i][j-1]+1;
dp[i-1][j] (表示删除):word1的前i-1个字符已经变换到word2的前j个字符的次数,当前word1仅用了前i-1个字符就完成了到word2的前j个字符的操作,所以word1的第i个字符其实没啥用了,那么删除操作就好了;所以dp[i][j] = dp[i-1][j]+1;于是
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
n1 = len(word1)
n2 = len(word2)
dp = [[0] * (n2 + 1) for _ in range(n1 + 1)]
# 第一行
for j in range(1, n2 + 1):
dp[0][j] = dp[0][j-1] + 1
# 第一列
for i in range(1, n1 + 1):
dp[i][0] = dp[i-1][0] + 1
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
if word1[i-1] == word2[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(dp[i][j-1], dp[i-1][j], dp[i-1][j-1] ) + 1
#print(dp)
return dp[-1][-1]贪心算法
前言
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
贪心的算法一般没有套路最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。
贪心算法的正确性的数学证明有如下两种方法:
- 数学归纳法
- 反证法
事实上,做题直接证明出来,不太现实,只能先推几项,猜测其正确性
手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心。
贪心算法一般分为如下四步:
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
做题的时候,只要想清楚 局部最优 是什么,如果推导出全局最优,其实就够了
题目
455. 分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
思路
每个孩子最多只能给一块饼干,那么就要尽量避免饼干尺寸的浪费
有点和田忌赛马的策略有点类似
先将饼干数组和小孩数组排序。
然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
class Solution:
def findContentChildren(self, g: List[int], s: List[int]) -> int:
g.sort(reverse=True)
s.sort()
index=0
#贪心:大饼干优先
index=len(s)-1 #index是饼干的下标
count=0#代表满足的孩子的人数
#遍历孩子,从胃口最大的开始
for i in range(len(g)):
if index >=0 and s[index]>=g[i]:
index-=1
i+=1
count+=1
return count376. 摆动序列
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 **摆动序列 。**第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
- 例如,
[1, 7, 4, 9, 2, 5]是一个 摆动序列 ,因为差值(6, -3, 5, -7, 3)是正负交替出现的。 - 相反,
[1, 4, 7, 2, 5]和[1, 7, 4, 5, 5]不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
子序列 可以通过从原始序列中删除一些(也可以不删除)元素来获得,剩下的元素保持其原始顺序。
给你一个整数数组 nums ,返回 nums 中作为 摆动序列 的 最长子序列的长度 。
思路
局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。
整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。
实际操作上,其实连删除的操作都不用做,因为题目要求的是最长摆动子序列的长度,所以只需要统计数组的峰值数量就可以了(相当于是删除单一坡度上的节点,然后统计长度)
class Solution:
def wiggleMaxLength(self, nums):
if len(nums) <= 1:
return len(nums) # 如果数组长度为0或1,则返回数组长度
curDiff = 0 # 当前一对元素的差值
preDiff = 0 # 前一对元素的差值
result = 1 # 记录峰值的个数,初始为1(默认最右边的元素被视为峰值)
for i in range(len(nums) - 1):
curDiff = nums[i + 1] - nums[i] # 计算下一个元素与当前元素的差值
# 如果遇到一个峰值
if (preDiff <= 0 and curDiff > 0) or (preDiff >= 0 and curDiff < 0):
result += 1 # 峰值个数加1
preDiff = curDiff # 注意这里,只在摆动变化的时候更新preDiff
return result # 返回最长摆动子序列的长度122. 买卖股票的最佳时机 II
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
局部最优:收集每天的正利润,全局最优:求得最大利润。
以每天为维度,只要每天有正收入就收集
class Solution:
def maxProfit(self, prices: List[int]) -> int:
profits=0
for i in range(len(prices)-1):
profits+=max(prices[i+1]-prices[i],0)
return profits