Part.1 前言
对于逆向工程权威指南关键部分的摘录,整理以及个人的理解
逆向工程权威指南是入门逆向必读的一本书籍
由于我是初学者,所以我目前只学习re4b x86汇编部分,对于ARM以及MIPS架构待以后进阶后再进行学习
Part.2 指令讲解
Chapter1 CPU
**指令码:CPU受理的底层命令。典型的底层命令有:将数据在寄存器间转移、操作内存、计算运算等指令。每类CPU都有自己的指令集架构(Instruction Set Architecture,ISA)。
**机器码:发送给CPU的程序代码。一条指令通常被封装为若干字节。
**汇编语言:为了让程序员少长白头发而创造出来的、易读易记的代码,它有很多类似宏的扩展功能。
**CPU寄存器:每种CPU都有其固定的通用寄存器(GPR)。x86 CPU里一般有8个GPR,x64里往往有16个GPR,而ARM里则通常有16个GPR。您可以认为CPU寄存器是一种存储单元,它能够无差别地存储所有类型的临时变量。假如您使用一种高级的编程语言,且仅会使用到8个32位变量,那么光CPU自带的寄存器就能完成不少任务了!
指令集架构
最常见的三种
-
ARM指令集分为3类:ARM模式指令集、Thumb模式指令集(包括Thumb-2)和ARM64的指令集。需要强调的是:不同的指令集分别
属于不同的指令集架构;一个指令集绝非另一个指令集的变种。
-
x86指令集 各opcode(汇编指令对应的机器码)的长度不尽相同
-
MIPS指令集 多数都使用了固定长度的32位opcode
汇编语言存在两种主流语体,即Intel语体和AT&T语体
Chap2 最简函数
int f()
{
return 123;
}f:
mov eax,123
ret这个函数仅由两条指令构成:第一条指令把数值123存放在EAX寄存器里;根据函数调用约定,后面一条指令会把EAX的值当作返回值传递给调用者函数,而调用者函数(caller)会从EAX寄存器里取值,把它当作返回结果。
Chap3 Hello,World!
msvs
#include <stdio.h>
int main()
{
printf("hello,world!\n");
return 0;
}用MSVScl 1.cpp /Fa1.asm生成1.asm
CONST SEGMENT
$SG3830 DB 'hello, world', 0AH, 00H
CONST ENDS
PUBLIC _main
EXTRN _printf:PROC
; Function compile flags: /Odtp
_TEXT SEGMENT
_main PROC
push ebp
mov ebp, esp
push OFFSET $SG3830
call _printf
add esp, 4
xor eax, eax
pop ebp
ret 0
_main ENDP
_TEXT ENDS生成1.asm后,编译器会生成1.obj然后再链接为1.exe
对这段汇编的解读
-
文件分为两个代码段,即CONST和_TEXT段,它们分别代表数据段和代码段。
-
字符串常量“hello,world”分配了一个指针(const char[]),只是在代码中这个指针的名称并不明显
-
编译器进行了自己的处理,并在内部把字符串常量命名为$SG3830,
0AH是换行符可以发现在字符串常量尾部添加了
00H这个是字符串常量的结束标志,编译器添加的 -
在代码段
_TEXT只有一个函数,即main(),其中PROC是Procdure的缩写,表示程序的开始,与ENDP配对使用 -
主函数的函数体有标志性的函数序言(function prologue)
push ebp ; 保存调用者的栈帧指针 mov ebp, esp ; 建立当前函数的栈帧指针 sub esp, N ; 为局部变量分配空间(N 是需要分配的字节数)以及函数尾声(function epilogue)
mov esp, ebp ; 恢复栈指针 pop ebp ; 恢复调用者的栈帧指针 ret ; 返回到调用者实际上所有的函数都有这样的序言和尾声。
-
在函数序言之后,看到调用
printf()的指令CALL _printf通过
PUSH指令,程序把字符串的指针推送入栈。这样,printf()函数就可以调用栈里的指针,即字符串“hello, world!”的地址。 -
在
printf()函数结束以后,程序的控制流会返回到main()函数之中。此时,字符串地址(即指针)仍残留在数据栈之中。这个时候就需要调整栈指针(ESP寄存器里的值)来释放这个指针。 -
下一条语句是
“add ESP,4”,把ESP寄存器(栈指针/Stack Pointer)里的数值加4。(在32位系统中,指针的大小占4字节,同理在64位中,就要+8)这条指令可以理解为“POP某寄存器”。只是本例的指令直接舍弃了栈里的数据而POP指令还要把寄存器里的值存储到既定寄存器
某些编译器(如Intel C编辑器)不会使用ADD指令来释放数据栈,它们可能会用POP ECX指令。例如,Oracle RDBMS(由Intel C编译器编译)就会用POP ECX指令,而不会用ADD指令。虽然POP ECX命令确实会修改ECX寄存器的值,但是它也同样释放了栈空间。
Intel C++编译器使用POP ECX指令的另外一个理由就是,POP ECX对应的OPCODE(1字节)比ADD ESP的OPCODE(3字节)要短。
-
在上述程序中printf()函数结束之后,main()函数会返回0(函数正常退出的返回码)。即main()函数的运算结果是0。这个返回值是由指令
“XOR EAX, EAX”计算出来的。编译器通常采用异或运算指令,而不会使用“MOV EAX,0”指令。主要是因为异或运算的opcode较短(2字节:5字节) -
汇编列表中最后的操作指令是RET,将控制权交给调用程序。通常它起到的作用就是将控制权交给操作系统,这部分功能由C/C++的
CRT实现。(C RUNTIME LIBRARY)
gcc
利用gcc编译器编译gcc 1.c -o 1采用-S -masm=intel生成intel语法的汇编列表文件
生成后用IDA打开
Main proc near
var_10 = dword ptr -10h
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 10h
mov eax, offset aHelloWorld ; "hello, world\n"
mov [esp+10h+var_10], eax
call _printf
mov eax, 0
leave
retn
main endp汇编解读
- 与MSVC生成的结果基本相同。它首先把“hello, world”字符串在数据段的地址(指针)存储到EAX寄存器里,然后再把它存储在数据栈里。
- 开头的
and esp,0FFFFFFF0h向16字节边界对齐(成为16的整数倍),属于初始化的指令。如果地址位没有对齐,那么CPU可能需要访问两次内存才能获得栈内数据。虽然在8字节边界处对齐就可以满足32位x86 CPU和64位x64 CPU的要求,但是主流编译器的编译规则规定“程序访问的地址必须向16字节对齐(被16整除),目的是为了提高效率 “SUB ESP,10h”将在栈中分配0x10 bytes,即16字节。我们在后文看到,程序只会用到4字节空间。但是因为编译器对栈地址(ESP)进行了16字节对齐,所以每次都会分配16字节的空间。- 而后,程序将字符串地址(指针的值)直接写入到数据栈。此处,GCC使用的是MOV指令;而MSVC生成的是PUSH指令。其中var_10是局部变量,用来向后面的printf()函数传递参数。
- GCC和MSVC不同,除非人工指定优化选项,否则它会生成与源代码直接对应的“MOV EAX, 0”指令。但是,我们已经知道MOV指令的opcode肯定要比XOR指令的opcode长。
- LEAVE指令,简化函数尾声,等效于
“MOV ESP, EBP”和“POP EBP”两条指令。可见,这个指令调整了数据栈指针ESP,并将EBP的数值恢复到调用这个函数之前的初始状态。
msvs x86-64
$SG2989 DB 'hello, world', 0AH 00H
main PROC
sub rsp, 40
lea rcx, OFFSET FLAT:$SG2989
call printf
xor eax, eax
add rsp, 40
ret 0
main ENDP在x86-64框架的CPU里,所有的物理寄存器都被扩展为64位寄存器。寄存器变为r字开头
为了尽可能充分地利用寄存器、减少访问内存数据的次数,编译器会充分利用寄存器传递函数参数(请参见64.3节的fastcall约定)。也就是说,编译器会优先使用寄存器传递部分参数,再利用内存(数据栈)传递其余的参数。Win64的程序还会使用RCX、RDX、R8、R9这4个寄存器来存放函数参数。我们稍后就会看到这种情况:printf()使用RCX寄存器传递参数,而没有像32位程序那样使用栈传递数据。
main()函数的返回值是整数类型的零,但是出于兼容性和可移植性的考虑,C语言的编译器仍将使用32位的零。换而言之,即使是64位的应用程序,在程序结束时EAX的值是零,而RAX的值不一定会是零。
数据栈的对应空间里仍留有40字节的数据。这部分数据空间有个专用的名词,即阴影空间(shadow space)
gcc x86-64
.string "hello, world\n"
main:
sub rsp, 8
mov edi, OFFSET FLAT:.LC0 ; "hello, world"
xor eax, eax ; number of vector registers passed
call printf
xor eax, eax
add rsp, 8
retLinux、BSD和Mac OS X系统中的应用程序,会优先使用RDI、RSI、RDX、RCX、R8、R9这6个寄存器传递函数所需的头6个参数,然后使用数据栈传递其余的参数。
使用了EDI寄存器来传递字符串指针,为什么不用RDI
需要注意的是,64位汇编指令MOV在写入R-寄存器的低32位地址位的时候,即对E-寄存器进行写操作的时候,会同时清除R-寄存器中的高32位地址位。所以, “MOV EAX, 011223344h”能够对RAX寄存器进行正确的赋值操作,因为该指令会清除(置零)高地址位的内容。
使用EDI是因为可以使opcode由7个字节减少到5个字节,gcc优化
gcc的优化有很多特性,例如:它可能会把字符串拆出来单独使用。以节省内存
Problems
1.答:调用了MessagBeep这个函数,参数为0xFFFFFFFF
Chap4 函数序言和函数尾声
略
Chap5 栈
-
栈就是CPU寄存器里的某个指针所指向的一片内存区域。这里所说的“某个指针”通常位于x86/x64平台的ESP寄存器/RSP寄存器,以及ARM平台的SP寄存器。
-
操作栈的最常见的指令是PUSH和POP,
PUSH指令会对ESP/RSP/SP寄存器的值进行减法运算,使之减去4(32位)或8(64位),然后将操作数写到上述寄存器里的指针所指向的内存中。POP指令是PUSH指令的逆操作:它先从栈指针(Stack Pointer,上面三个寄存器之一)指向的内存中读取数据,用以备用(通常是写到其他寄存器里),然后再将栈指针的数值加上4或8。 -
栈是逆增长的,即从高地址向低地址增长
栈的用途
-
保存函数的返回地址
call指令等价于push 返回地址与jmp 函数地址ret指令从栈中读取返回地址,然后跳转到这个地址,等价于pop 返回地址与jmp 返回地址由此可实现函数的递归调用
-
参数传递
最常用的参数传递约定是
cdecl以下为其主要规则
- 参数从右到左压入栈
- 调用者负责清理栈:函数调用结束后,调用者需要负责从栈中弹出传递给函数的所有参数。这意味着编译器会在调用函数之后生成相应的代码来调整堆栈指针,恢复调用前的状态。
- 可变参数列表支持:cdecl 支持函数具有可变数量的参数(如 printf 函数),这是通过在参数列表中使用省略号(…)来表示的。
- 返回值通常在EAX寄存器中(对于x86架构):大多数情况下,函数的返回值如果大小适当(比如整数、指针),会通过EAX寄存器返回。对于更大的返回类型,可能会通过其他方式,如通过指针传递。
例如
push arg3 push arg2 push arg1 call f add esp.12;4*3被调用的函数可以通过栈指针获取所需参数
ESP 返回地址 ESP+4 arg1, 它在IDA里记为arg_0 ESP+8 arg2, 它在IDA里记为arg_4 ESP+0xC arg3, 它在IDA里记为arg_8 需要注意的是,程序员可以使用栈来传递参数,也可以不使用栈传递参数。参数处理方面并没有相关的硬性规定。例如也可以用寄存器或者堆上开辟内存进行传参,不过在x86这种约定已是习惯
如果函数可处理的参数数量可变,就需要用说明符如%d进行格式化说明,明确参数信息
printf("%d %d %d", 1234);这个命令不仅会让printf()显示1234,而且还会让它显示数据栈内1234之后的两个地址的随机数。
由此可知,声明main()函数的方法并不是那么重要。我们可以将之声明为
main(),main(int argc, char *argv[])或main(int argc, char *argv[], char *envp[]),CRT中调用main()指令如下:push envp push argv push argc call main -
存储局部变量
-
x86.alloca()函数
malloc()是在堆上分配内存,而alloc()直接使用栈来分配内存由于函数尾声的代码会还原
ESP的值,不需要特地使用free()来释放内存 -
(Win)SEH结构化异常处理
如果程序里存在
SEH记录,那么记录会保存在栈中 -
缓冲区溢出保护
-
典型的栈的内存存储格式
在32位系统中,在程序调用函数之后、执行它的第一条指令之前,栈在内存中的存储格式一般如下表所示。
| ... | //高位 +-----------+ | 参数 | +-----------+ | 返回地址 | +-----------+ <- esp (调用后) | 调用者的ebp | +-----------+ | 局部变量 | +-----------+ <- esp (设置完局部变量后)//低位… …… ESP-0xC 第2个局部变量,在IDA里记为var_8 ESP-8 第1个局部变量,在IDA里记为var_4 ESP-4 保存的EBP值 ESP 返回地址 ESP+4 arg1, 在IDA里记为arg_0 ESP+8 arg2, 在IDA里记为arg_4 ESP+0xC arg3, 在IDA里记为arg_8 … ……
栈的噪音
函数退出以后,原有栈的空间里的局部变量不会被自动清除,仍然保留就成了栈中的脏数据
例如
#include <stdio.h>
void f1()
{
int a=1, b=2, c=3;
};
void f2()
{
int a, b, c;
printf ("%d, %d, %d\n", a, b, c);
};
int main()
{
f1();
f2();
};我们会发现,没有对f2的变量初始化,仍然打印的是 1 2 3
可以研究一下汇编代码,利用MSVS编译的代码如下
$SG2752 DB '%d, %d, %d', 0aH, 00H
_c$ = -12 ; size = 4
_b$ = -8 ; size = 4
_a$ = -4 ; size = 4
_f1 PROC
push ebp
mov ebp, esp
sub esp, 12
mov DWORD PTR _a$[ebp], 1
mov DWORD PTR _b$[ebp], 2
mov DWORD PTR _c$[ebp], 3
mov esp, ebp
pop ebp
ret 0
_f1 ENDP
_c$ = -12 ; size = 4
_b$ = -8 ; size = 4
_a$ = -4 ; size = 4
_f2 PROC
push ebp
mov ebp, esp
sub esp, 12
mov eax, DWORD PTR _c$[ebp]
push eax
mov ecx, DWORD PTR _b$[ebp]
push ecx
mov edx, DWORD PTR _a$[ebp]
push edx
push OFFSET $SG2752 ; ’%d, %d, %d’
call DWORD PTR __imp__printf
add esp, 16
mov esp, ebp
pop ebp
ret 0
_f2 ENDP
main PROC
push ebp
mov ebp, esp
call _f1
call _f2
xor eax, eax
pop ebp
ret 0
_main ENDP在这个特例里,第二个函数在第一个函数之后执行,而第二个函数变量的地址和SP的值又与第一个函数的情况相同。所以,相同地址的变量获得的值相同。
总而言之,在运行第二个函数时,栈中的所有值(即内存中的单元)受前一个函数的影响,而获得了前一个函数的变量的值。严格地说,这些地址的值不是随机值,而是可预测的伪随机值。
Problems
5.1
如果使用MSVC编译、运行下列程序,将会打印出3个整数。这些数值来自哪里?如果使用MSVC的优化选项“/Ox”,程序又会在屏幕上输出什么?为什么GCC的情况完全不同?
#include <stdio.h>
int main()
{
printf ("%d, %d, %d\n");
return 0;
};如果未启用MSVC的优化编译功能,程序显示的数字分别是EBP的值、RA和argc。在命令行中执行相应的程序即可进行验证。
如果启用了MSVC的优化编译功能,程序显示的数字分别来自:返回地址RA、argc和数组argv[]。
GCC会给main() 函数的入口分配16字节的地址空间,所以输出内容会有不同。
5.2
答:打印时间
Chap6 printf()函数与参数传递
演示程序
#include <stdio.h>
int main()
{
printf("a=%d,b=%d,c=%d",1,2,3);
return 0;
}用 g++ -m32 -o 1 1.c进行编译或者使用MSVS工具链进行编译,跟随本书的节奏,配置一下MSVS的环境
通过命令行使用 Microsoft C++ 工具集 | Microsoft Learn
首先将Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build加入环境变量
命令行输入vcvarsall.bat x86
然后cl 1.cpp
MSVS工具链一些常用的指令
cl /Fa 1.c生成不带注释的汇编代码
cl /FAs 1.c生成带注释的汇编代码,生成1.asm
dumpbin /all example.obj显示目标文件中的所有信息,包括段内容、符号表和重定位信息。
/c 代表只编译不链接。
/I 指定头文件的目录
/C 在编译期间保留代码注释,这里和/I连在一起使用,/IC
首先介绍一个概念,VC中有个PDB文件,全称是Program Database,用来存放程序信息的小的数据库文件。
编译Debug版本时,调试信息需要保留,我们可以选择直接将调试信息写到.obj文件中,或者存到.pdb文件中。
/Z7 不产生.pdb文件,将所有调试信息存入.obj文件中
/Zi和/ZI 都产生.pdb文件,不过/ZI支持"编辑继续调试"功能, (the edit and continue feature), 看上去更酷,但是我从来没有用过这个功能。
/ZI有一些边际效应,会禁止#pragma optmize 指令,也不能和/clr一起用。
/nologo- 已经无效,自己生成命令行的时候,没必要用了。
/W3 也中警告级别,VC提供了很多警告级别,参考http://msdn.microsoft.com/en-us/library/vstudio/thxezb7y.aspx
自己编译的话,直接用/Wall最好。
/WX- 不太明白为什么有 - 号,(估计是和:NO的意思相同,也就是不启用该功能), /WX的意思是将warning转变成error,这样强迫消除所有的warning,如果和/Wall一起使用,那是最好的。
/sdl 是对代码进行安全检查,如果发现相关警告,转变成错误输出
/Od 禁止优化
/Oy- 禁止该选项,该选项如果没有 - 号,则会在x86上编译时忽略frame-pointer,起到加速程序的作用。 frame-pointer,我暂时不知道是啥。
/D 预处理定义,后面可以跟不同的参数都是宏啊,比如
/Gm 启用最小化重新编译, VC用.idb保留了上次编译的缓存信息,包括文件依赖关系。下次编译时可以使用.idb文件用来检查,跳过不需要重新编译的文件。
具体参见:
MSVC Compiler Options | Microsoft Learn
x86
MSVS编译得到的汇编指令如下
_TEXT SEGMENT
_main PROC
; 3 : {
push ebp
mov ebp, esp
; 4 : printf("a=%d,b=%d,c=%d",1,2,3);
push 3
push 2
push 1
push OFFSET $SG9695
call _printf
add esp, 16 ; 00000010H
; 5 : return 0;
xor eax, eax
; 6 : }
pop ebp
ret 0
_main ENDP
_TEXT ENDS可以看到printf()函数的参数是逆序存入栈中,第一个参数在最后入栈
在32位下,32位地址指针和int类型数据都占据32位即4字节的空间,因此4个参数总共占用16字节的存储空间
因此在调用函数之后,“ADD ESP, X”指令修正ESP寄存器中的栈指针。通常情况下,我们可以通过call之后的这条指令判断参数的数量:变量总数=*X*÷4。(仅适用于调用约定为cdecl的程序)
如果某个程序连续地调用多个函数,且调用函数的指令之间不夹杂其他指令,那么编译器可能把释放参数存储空间的“ADD ESP,X”指令进行合并,一次性地释放所有空间
体验用onlydbg加载这个程序
这里需要用到debug版本的编译命令
cl /Z7 /EHsc 1.exe 1.c便于跟踪程序
找到main函数的方法:方法很多,不细说了
具体操作按书上来
Chap7 scanf()
演示程序
#include <stdio.h>
int main()
{
int x;
printf("Enter X:\n");
scanf("%d", &x);
printf("You Entered: %d\n", x);
return 0;
}x86
cl /FAs /Z7 2 2.c
_DATA SEGMENT
$SG9696 DB 'Enter X:', 0aH, 00H
ORG $+2
$SG9697 DB '%d', 00H
ORG $+1
$SG9698 DB 'You Entered: %d', 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
_x$ = -4 ; size = 4
_main PROC
; 3 : {
push ebp
mov ebp, esp
push ecx
; 4 : int x;
; 5 : printf("Enter X:\n");
push OFFSET $SG9696
call _printf
add esp, 4
; 6 : scanf("%d", &x);
lea eax, DWORD PTR _x$[ebp]
push eax
push OFFSET $SG9697
call _scanf
add esp, 8
; 7 :
; 8 : printf("You Entered: %d\n", x);
mov ecx, DWORD PTR _x$[ebp]
push ecx
push OFFSET $SG9698
call _printf
add esp, 8
; 9 : return 0;
xor eax, eax
; 10 : }
mov esp, ebp
pop ebp
ret 0
_main ENDP汇编解读:
-
可以看到,
scanf()传递的第二个参数(eax)是一个指向栈中的指针,x是局部变量,存储在栈中。在栈中分配了4字节空间,存储局部变量x -
**汇编宏_x$ (其值为−4)**用于访问局部变量x,而EBP寄存器用来存储栈当前帧的指针。
在函数运行的期间,EBP一直指向当前的栈帧(stack frame)。这样,函数即可通过EBP+offset的方式访问本地变量、以及外部传入的函数参数。
ESP也可以用来访问本地变量,获取函数所需的运行参数。不过ESP的值经常发生变化,用起来并不方便。函数在启动之初就会利用EBP寄存器保存ESP寄存器的值。这就是为了确保在函数运行期间保证EBP寄存器存储的原始ESP值固定不变。
在32位系统里,典型的栈帧(stack frame)结构如下表所示。
…… …… EBP-8 局部变量#2,IDA标记为var_8 EBP-4 局部变量#1,IDA标记为var_4 EBP EBP的值 EBP+4 返回地址Return address EBP+8 函数参数#1,IDA标记为arg_0 EBP+0xC 函数参数#2,IDA标记为arg_4 EBP+0x10 函数参数#3,IDA标记为arg_8 …… …… -
scanf()在此例中有两个参数,第一个参数是一个指针,指向含有"%d"的格式化字符串,第二个参数是局部变量x的地址“lea eax, DWORD PTR _x$[ebp]”指令将变量x的地址放入EAX寄存器。
在此处
LEA会将EBP寄存器值与宏_x$求和,然后将这个结果存储到EAX,然后把EAX寄存器的值送入栈中(就是把x的地址送入EAX寄存器) -
而后调用
printf()函数,第一个参数即格式化字符串的指针第二个参数是
mov ecx,[ebp-4]间接取值,传递给ecx的值是ebp-4指向的地址的值,即变量x的值
用onlydbg动态跟踪这个过程,具体书上有
- 调试可以发现,执行完
scanf()函数,EAX存储有函数的返回值,其值是scanf()读取参数的个数 - 我们可以在栈中找到局部变量的地址,进而跟踪其值
全局变量
如果上文的x是全局变量,会有什么样的变化
将x改成全局变量
_DATA SEGMENT
$SG9696 DB 'Enter X:', 0aH, 00H
ORG $+2
$SG9697 DB '%d', 00H
ORG $+1
$SG9698 DB 'You Entered: %d', 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
_main PROC
; 4 : {
push ebp
mov ebp, esp
; 5 :
; 6 : printf("Enter X:\n");
push OFFSET $SG9696
call _printf
add esp, 4
; 7 : scanf("%d", &x);
push OFFSET _x
push OFFSET $SG9697
call _scanf
add esp, 8
; 8 :
; 9 : printf("You Entered: %d\n", x);
mov eax, DWORD PTR _x
push eax
push OFFSET $SG9698
call _printf
add esp, 8
; 10 : return 0;
xor eax, eax
; 11 : }
pop ebp
ret 0
_main ENDP
_TEXT ENDS-
可以发现
x的存储空间不再由栈中存储,而是在数据段(由于没给x赋值,编译器自动优化为bss段(不占据空间)) -
如果对上述源代码稍做改动,加上变量初始化的指令:
int x=10; //设置默认值那么对应的代码会变为:
_DATA SEGMENT _x DD 0aH ...上述指令将初始化x。其中DD代表DWORD,表示x是32位的数据。
若在IDA里打开对x进行初始化的可执行文件,我们将会看到在数据段的开头部分看到初始化变量x。紧随其后的空间用于存储本例中的字符串。
用IDA打开7.2节里那个不初始化变量x的例子,那么将会看
有很多带“?”标记的变量,这是未初始化的x变量的标记。这意味着在程序加载到内存之后,操作系统将为这些变量分配空间、并填入数字零。但是在可执行文件里,这些未初始化的变量不占用内存空间。为了方便使用巨型数组之类的大型数据,人们刻意做了这种设定。
Problem
#include <string.h>
#include <stdio.h>
void alter_string(char *s)
{
strcpy (s, "Goodbye!");
printf ("Result: %s\n", s);
};
int main()
{
alter_string ("Hello, world!\n");
};在win可运行,因为s是在data段
而在linux不可运行,s存储在rodata段,不可写
Chap8 参数获取
main()函数把3个数字推送入栈,然后调用了f(int, int, int)。被调用方函数f()通过_a)与EBP寄存器的值相加,从而求得所需地址。
当变量a的值存入EAX寄存器之后,f()函数通过各参数的地址依次进行乘法和加法运算,运算结果一直存储于EAX寄存器。此后EAX的值就可以直接作为返回值传递给调用方函数。调用方函数main()再把EAX的值当作参数传递给printf()函数。
Chap9 返回值
在x86系统里,被调用方函数通常通过EAX寄存器返回运算结果。若返回值属于byte或char类型数据,返回值将存储于EAX寄存器的低8位——AL寄存器存储返回值。如果返回值是浮点float型数据,那么返回值将存储在FPU的ST(0)寄存器里。ARM系统的情况相对简单一些,它通常使用R0寄存器回传返回值。
void类型的返回值
调用main
push envp
push argv
push argc
call main
push eax
call exit也就是exit(main(argc,argv,envp));
如果声明main()的数据类型是void,则main()函数不会明确返回任何值(没有return指令)。不过在main()函数退出时,EAX寄存器还会存有数据,EAX寄存器保存的数据会被传递给exit()函数、成为后者的输入参数。通常EAX寄存器的值会是被调用方函数残留的确定数据,所以void类型函数的返回值、也就是主函数退出代码往往属于伪随机数(pseudorandom)
返回值为结构体型数据
调用方函数(caller)创建了数据结构、分配了数据空间,被调用的函数仅向结构体填充数据。其效果等同于返回结构体。
Chap10 指针
指针通常用来帮助函数处理返回值。当函数需要返回多个值时,它通常都是通过指针传递返回值的。
#include <stdio.h>
void f1 (int x, int y, int *sum, int *product)
{
*sum=x+y;
*product=x*y;
};
int sum, product;
void main()
{
f1(123, 456, &sum, &product);
printf ("sum=%d, product=%d\n", sum, product);
};COMM _product:DWORD
COMM _sum:DWORD
; 定义字符串常量 $SG2803,表示格式化输出的字符串 "sum=%d, product=%d\n"
$SG2803 DB 'sum=%d, product=%d', 0aH, 00H
; 定义参数在栈帧中的偏移量
_x$ = 8 ; 参数 _x 在栈帧中的偏移量,大小为 4 字节
_y$ = 12 ; 参数 _y 在栈帧中的偏移量,大小为 4 字节
_sum$ = 16 ; _sum 在栈帧中的偏移量,大小为 4 字节
_product$ = 20 ; _product 在栈帧中的偏移量,大小为 4 字节
; 定义 _f1 函数
_f1 PROC
; 将参数 _y 的值加载到 ecx 寄存器
mov ecx, DWORD PTR _y$[esp-4]
; 将参数 _x 的值加载到 eax 寄存器
mov eax, DWORD PTR _x$[esp-4]
; 计算 _x 和 _y 的和,结果存储到 edx 寄存器
lea edx, DWORD PTR [eax+ecx]
; 计算 _x 和 _y 的乘积,结果存储到 eax 寄存器
imul eax, ecx;eax=eax*ecx
; 将 _product 的地址加载到 ecx 寄存器
mov ecx, DWORD PTR _product$[esp-4]
; 保存 esi 寄存器的值,为后续操作做准备
push esi
; 将 _sum 的地址加载到 esi 寄存器
mov esi, DWORD PTR _sum$[esp]
; 将和的结果存储到 _sum 指向的位置
mov DWORD PTR [esi], edx
; 将积的结果存储到 _product 指向的位置
mov DWORD PTR [ecx], eax
; 恢复 esi 寄存器的值
pop esi
; 返回到调用者
ret 0
_f1 ENDP
; 定义 _main 函数
_main PROC
; 将 _product 的地址压入栈中
push OFFSET _product
; 将 _sum 的地址压入栈中
push OFFSET _sum
; 将参数 456 压入栈中
push 456 ; 456 的十六进制表示为 0x1c8
; 将参数 123 压入栈中
push 123 ; 123 的十六进制表示为 0x7b
; 调用 _f1 函数
call _f1
; 将 _product 的值加载到 eax 寄存器
mov eax, DWORD PTR _product
; 将 _sum 的值加载到 ecx 寄存器
mov ecx, DWORD PTR _sum
; 将 _product 和 _sum 的值作为参数,调用 printf 函数
push eax
push ecx
push OFFSET $SG2803
call DWORD PTR __imp__printf
; 调整栈指针,清理参数
add esp, 28
xor eax, eax
; 返回到调用者
ret 0
_main ENDPChap12 条件转移
数值比较
#include <stdio.h>
void f_signed (int a, int b)
{
if (a>b)
printf ("a>b\n");
if (a==b)
printf ("a==b\n");
if (a<b)
printf ("a<b\n");
};
void f_unsigned (unsigned int a, unsigned int b)
{
if (a>b)
printf ("a>b\n");
if (a==b)
printf ("a==b\n");
if (a<b)
printf ("a<b\n");
};
int main()
{
f_signed(1, 2);
f_unsigned(1, 2);
return 0;
};_a$ = 8 ; size = 4
_b$ = 12 ; size = 4
_f_unsigned PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
cmp eax, DWORD PTR _b$[ebp]
jbe SHORT $LN3@f_unsigned
push OFFSET $SG2761 ; 'a>b'
call _printf
add esp, 4
$LN3@f_unsigned:
mov ecx, DWORD PTR _a$[ebp]
cmp ecx, DWORD PTR _b$[ebp]
jne SHORT $LN2@f_unsigned
push OFFSET $SG2763 ; 'a==b'
call _printf
add esp, 4
$LN2@f_unsigned:
mov edx, DWORD PTR _a$[ebp]
cmp edx, DWORD PTR _b$[ebp]
jae SHORT $LN4@f_unsigned
push OFFSET $SG2765 ; 'a<b'
call _printf
add esp, 4
LN4@f_unsigned:
Pop ebp
Ret 0
_f_unsigned ENDP
_main PROC
push ebp
mov ebp, esp
push 2
push 1
call _f_signed
add esp, 8
push 2
push 1
call _f_unsigned
add esp, 8
xor eax, eax
pop ebp
ret 0
_main ENDP- JLE,即“Jump if Less or Equal”。如果上一条CMP指令的第一个操作表达式小于或等于(不大于)第二个表达式,JLE将跳转到指令所标明的地址;如果不满足上述条件,则运行下一条指令,就本例而言程序将会调用printf()函数。第二个条件转移指令是JNE,“Jump if Not Equal”,如果上一条CMP的两个操作符不相等,则进行相应跳转。
- JGE,即“Jump if Greater or Equal”。如果CMP的第一个表达式大于或等于第二个表达式(不小于),则进行跳转。这段程序里,如果三个跳转的判断条件都不满足,将不会调用printf()函数;不过,除非进行特殊干预,否则这种情况应该不会发生
- 经GCC编译后,f_unsigned()函数使用的条件转移指令是JBE(Jump if Below or Equal,相当于JLE)和JAE(Jump if Above or Equal,相当于JGE)。==JA/JAE/JB/JBE与JG/JGE/JL/JLE的区别,在于它们检查的标志位不同:前者检查借/进位标志位CF(1意味着小于)和零标志位ZF(1意味着相等),后者检查“SF XOR OF”(1意味着异号)和ZF。==从指令参数的角度看,前者适用于unsigned(无符号)类型数据的(CMP)运算,而后者的适用于signed(有符号)类型数据的运算。
计算绝对值
int my_abs (int i)
{
if (i<0)
return -i;
else
return i;
};i$ = 8
my_abs PROC
; ECX = 输入值
test ecx, ecx ; 执行 ECX 和自身的按位与操作以设置标志
; 检查输入值的符号
; 如果符号为正则跳过 NEG 指令
jns SHORT $LN2@my_abs ; 如果 ECX 为非负数,则跳转到 $LN2@my_abs
; 取反值
neg ecx ; 如果 ECX 为负数,取反 ECX (ECX = -ECX)
$LN2@my_abs:
; 将结果准备到 EAX:
mov eax, ecx ; 将 ECX 的值复制到 EAX
ret 0 ; 从过程返回(不清除任何参数)
my_abs ENDP ; 过程 my_abs 的结束
neg 指令用于将寄存器或内存位置中的操作数取反。具体来说,它将操作数变为它的相反数(即取负值)。neg 指令实际上是计算二补数。
以下是 neg 指令的详细解释:
- 如果操作数是正数,
neg会将其变为负数。 - 如果操作数是负数,
neg会将其变为正数。 - 如果操作数是零,
neg会保持其为零。
在处理过程中,neg 指令会影响标志寄存器(Flags Register)中的以下标志:
- CF(进位标志):如果结果为非零,则设置 CF。
- ZF(零标志):如果结果为零,则设置 ZF。
- SF(符号标志):根据结果的最高位设置 SF。
- OF(溢出标志):如果操作数是最小的负数,则设置 OF(例如,对于32位整数,-2^31 变为 2^31-1 会导致溢出)。
假设 ECX 寄存器包含值 5 或 -5,在执行 neg 指令后的变化如下:
mov ecx, 5 ; ECX = 5
neg ecx ; ECX = -5
mov ecx, -5 ; ECX = -5
neg ecx ; ECX = 5条件运算符
const char* f (int a)
{
return a==10 ? "it is ten" : "it is not ten";
};-
在编译含有条件运算符的语句时,早期无优化功能的编译器会以编译“if/else”语句的方法进行处理。
$SG746 DB 'it is ten', 00H ; 定义字符串 "it is ten" 并以空字符结尾 $SG747 DB 'it is not ten', 00H ; 定义字符串 "it is not ten" 并以空字符结尾 tv65 = -4 ; 这是一个临时变量,存储在栈帧中的偏移量为 -4 _a$ = 8 ; 输入值在栈帧中的偏移量为 8 _f PROC push ebp ; 保存基指针 EBP mov ebp, esp ; 设置新的栈帧 push ecx ; 保存 ECX 寄存器的值 ; 比较输入值是否为10 cmp DWORD PTR _a$[ebp], 10 ; 比较位于栈帧偏移 _a$ 处的值是否为10 ; 如果不等于10,则跳转到 $LN3@f jne SHORT $LN3@f ; 如果不等于10,跳转到 $LN3@f ; 将指向字符串 'it is ten' 的指针存储到临时变量中 mov DWORD PTR tv65[ebp], OFFSET $SG746 ; 将字符串 "it is ten" 的地址存储到 tv65 变量中 ; 跳转到退出标签 jmp SHORT $LN4@f ; 跳转到 $LN4@f $LN3@f: ; 将指向字符串 'it is not ten' 的指针存储到临时变量中 mov DWORD PTR tv65[ebp], OFFSET $SG747 ; 将字符串 "it is not ten" 的地址存储到 tv65 变量中 $LN4@f: ; 这是退出部分。从临时变量中复制指向字符串的指针到 EAX 中 mov eax, DWORD PTR tv65[ebp] ; 将 tv65 变量中的值复制到 EAX 寄存器 mov esp, ebp ; 恢复栈指针 pop ebp ; 恢复基指针 ret 0 ; 返回,清理栈上的参数 _f ENDP ; 过程 _f 结束开启编译器优化
$SG792 DB 'it is ten', 00H $SG793 DB 'it is not ten', 00H _a$ = 8 ; size = 4 _f PROC ; compare input value with 10 cmp DWORD PTR _a$[esp-4], 10 mov eax, OFFSET $SG792 ; 'it is ten' ; jump to $LN4@f if equal je SHORT $LN4@f mov eax, OFFSET $SG793 ; 'it is not ten' $LN4@f: ret 0 _f ENDP
比较大小
- 启用优化功能后,编译器会尽可能避免使用条件转移指令
int my_max(int a, int b)
{
if (a>b)
return a;
else
return b;
};
int my_min(int a, int b)
{
if (a<b)
return a;
else
return b;
};没开启优化
_a$ = 8
_b$ = 12
_my_min PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
; compare A and B:
cmp eax, DWORD PTR _b$[ebp]
; jump, if A is greater or equal to B:
jge SHORT $LN2@my_min
; reload A to EAX if otherwise and jump to exit
mov eax, DWORD PTR _a$[ebp]
jmp SHORT $LN3@my_min
jmp SHORT $LN3@my_min ; this is redundant JMP
$LN2@my_min:
; return B
mov eax, DWORD PTR _b$[ebp]
$LN3@my_min:
pop ebp
ret 0
_my_min ENDP
_a$ = 8
_b$ = 12
_my_max PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
; compare A and B:
cmp eax, DWORD PTR _b$[ebp]
; jump if A is less or equal to B:
jle SHORT $LN2@my_max
; reload A to EAX if otherwise and jump to exit
mov eax, DWORD PTR _a$[ebp]
jmp SHORT $LN3@my_max
jmp SHORT $LN3@my_max ; this is redundant JMP
$LN2@my_max:
; return B
mov eax, DWORD PTR _b$[ebp]
$LN3@my_max:
pop ebp
ret 0
_my_max ENDPChap13 Switch
case较少的情形
#include <stdio.h>
void f (int a)
{
switch (a)
{
case 0: printf ("zero\n"); break;
case 1: printf ("one\n"); break;
case 2: printf ("two\n"); break;
default: printf ("something unknown\n"); break;
};
};
int main()
{
f(2); //test
};msvs不开启优化
tv64 = -4 ; size = 4
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
push ecx
mov eax, DWORD PTR _a$[ebp]
mov DWORD PTR tv64[ebp], eax
cmp DWORD PTR tv64[ebp], 0
je SHORT $LN4@f
cmp DWORD PTR tv64[ebp], 1
je SHORT $LN3@f
cmp DWORD PTR tv64[ebp], 2
je SHORT $LN2@f
jmp SHORT $LN1@f
$LN4@f:0
push OFFSET $SG739 ; 'zero', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN7@f
$LN3@f:1
push OFFSET $SG741 ; 'one', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN7@f
$LN2@f:2
push OFFSET $SG743 ; 'two', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN7@f
$LN1@f:default
push OFFSET $SG745 ; 'something unknown', 0aH, 00H
call _printf
add esp, 4
$LN7@f:ret
mov esp, ebp
pop ebp
ret 0
_f ENDP可以发现编译器把Switch翻译成了if else形式可以认为,switch()语句是一种旨在简化大量嵌套if()语句而设计的语法糖
开启优化
cl 1.c /Fa1.asm /Ox
_a$ = 8 ; size = 4
_f PROC
mov eax, DWORD PTR _a$[esp-4];eax=a
sub eax, 0;eax=eax-0
je SHORT $LN4@f;if a==0
sub eax, 1
je SHORT $LN3@f;if a==1
sub eax, 1
je SHORT $LN2@f;if a==2
;default
mov DWORD PTR _a$[esp-4], OFFSET $SG791 ; 'something unknown', 0aH, 00H
jmp _printf
$LN2@f:;2
mov DWORD PTR _a$[esp-4], OFFSET $SG789 ; 'two', 0aH, 00H
jmp _printf
$LN3@f:;1
mov DWORD PTR _a$[esp-4], OFFSET $SG787 ; 'one', 0aH, 00H
jmp _printf
$LN4@f:;0
mov DWORD PTR _a$[esp-4], OFFSET $SG785 ; 'zero', 0aH, 00H
jmp _printf
_f ENDP两处不同
-
a存到eax之后,eax-0;这样看似无意义,实际上可以检查eax寄存器的值是否为0,如果eax是0,ZF=1,进而检查第一个判断条件,如果不是就继续-1判断
-
在把字符串指针存储到变量a之后,函数使用JMP指令调用printf()函数。
这点不难解释:调用方函数把参数推送入栈之后,的确通常通过CALL指令调用其他函数。这种情况下,CALL指令会把返回地址推送入栈、并通过无条件转移的手段启用被调用方函数。就本例而言,在被调用方函数运行的任意时刻,栈的内存存储结构为:
- ESP——指向RA。
- ESP+4——指向变量a。
另一方面,在本例程序调用printf()函数之前、之后,除了制各第一个格式化字符串的参数问题以外,栈的存储结构其实没有发生变化。所以,编译器在分配JMP指令之前,把字符串指针存储到相应地址上。
这个程序把函数的第一个参数替换为字符串的指针,然后跳转到printf()函数的地址,就好像程序没有“调用”过f()函数、直接“转移”了printf()函数一般。当printf()函数完成输出的使命以后,它会执行RET返回指令。RET指令会从栈中读取(POP)返回地址RA、并跳转到RA。不过这个RA不是其调用方函数——f()函数内的某个地址,而是调用f()函数的函数即main()函数的某个地址。换而言之,==跳转到这个RA地址后,printf()函数会伴随其调用方函数f()==一同结束。
除非每个case从句的最后一条指令都是调用printf()函数,否则编译器就做不到这种程度的优化。某种意义上说这与longjmp()函数十分相似。当然,这种优化的目的无非就是提高程序的运行速度。
case较多的情形
在switch()语句存在大量case()分支的情况下,编译器就不能直接套用大量JE/JNE指令了。会生成一种跳转表,否则程序代码肯定会非常庞大。
#include <stdio.h>
void f (int a)
{
switch (a)
{
case 0: printf ("zero\n"); break;
case 1: printf ("one\n"); break;
case 2: printf ("two\n"); break;
case 3: printf ("three\n"); break;
case 4: printf ("four\n"); break;
default: printf ("something unknown\n"); break;
};
};
int main()
{
f(2); // test
};x86,未开启优化,msvs
tv64 = -4 ; size=4
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp;函数序言
push ecx
mov eax, DWORD PTR _a$[ebp];eax=a
mov DWORD PTR tv64[ebp], eax;tv64=a
cmp DWORD PTR tv64[ebp], 4;if a==4
ja SHORT $LN1@f;if a>4
mov ecx, DWORD PTR tv64[ebp]
jmp DWORD PTR $LN11@f[ecx*4];jmp 跳转表
$LN6@f:0
push OFFSET $SG739 ; 'zero', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN9@f
$LN5@f:1
push OFFSET $SG741 ; 'one', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN9@f
$LN4@f:2
push OFFSET $SG743 ; 'two', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN9@f
$LN3@f:3
push OFFSET $SG745 ; 'three', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN9@f
$LN2@f:4
push OFFSET $SG747 ; 'four', 0aH, 00H
call _printf
add esp, 4
jmp SHORT $LN9@f
$LN1@f:defalut
push OFFSET $SG749 ; 'something unknown', 0aH, 00H
call _printf
add esp, 4
$LN9@f:;ret
mov esp, ebp
pop ebp
ret 0
npad 2; align next label
$LN11@f:;跳转表
DD $LN6@f ; 0
DD $LN5@f ; 1
DD $LN4@f ; 2
DD $LN3@f ; 3
DD $LN2@f ; 4
_f ENDP-
汇编解读:
-
这段代码可被分为数个调用
printf()函数的指令组 -
$ln11@F的偏移量开始的表叫做跳转表(jumptable)
-
函数最初把变量a与数字4进行比较,如果a>4,就打印something unknown
-
jmp DWORD PTR $LN11@f[ecx*4]如果a<=4,会先计算a*4,然后根据LN11@f这个表查询,并跳转到这个表所指向的地址。为什么要x4?是因为x86系统的内存地址都是32位数据,每个地址占用4字节,偏移地址需要x4才能到达此时的switch语句等效于
jmp DWORD PTR ($LN11@f[ecx*4])$LN11@f+ecx*4 -
npad指令属于
汇编宏,==它的作用是把紧接其后的标签地址向4字节(或16字节)边界对齐。==npad的地址对齐功能可提高处理器的IO读写效率,通过一次操作即可完成内存总线、缓冲内存等设备的数据操作。
-
switch()的大体框架
MOV REG,input
CMP REG,4 ; maximal number of cases
JA default
SHL REG,3 ; find element in table.shift for 3bits in x64.
MOV REG, jump_table[REG]
JMP REG
case1;
; do something
JMP exit
case2;
; do something
JMP exit
case3;
; do something
JMP exit
case4;
; do something
JMP exit
Case5;
; do something
JMP exit
defaule:
…
exit:
…
jump_table dd casel
dd case2
dd case3
dd case4
dd case5若不使用上述指令,我们也可以在32位系统上使用指令JMP jump_table[REG*4]/在64位上使用JMP jump_table[REG*8],实现转移表中的寻址计算。
说到底,转移表只不过是某种指针数组它和18.5节介绍的那种指针数组十分雷同。
case从句多对一
#include <stdio.h>
void f (int a)
{
switch (a)
{
case 1:
case 2:
case 7:
case 10:
printf ("1, 2, 7, 10\n");
break;
case 3:
case 4:
case 5:
case 6:
printf ("3, 4, 5\n");
break;
case 8:
case 9:
case 20:
case 21:
printf ("8 9, 21\n");
break;
case 22:
printf ("22\n");
break;
default:
printf ("default\n");
break;
};
};
int main ()
{
f(4);
};如果编译器刻板地按照每种可能的逻辑分支逐一分配对应的指令组,那么程序里将会存在大量的重复指令。一般而言,编译器会通过某种派发机制来降低代码的冗余度。
使用MSVS 开启/Ox优化
1 $SG2798 DB '1, 2, 7, 10', 0aH, 00H
2 $SG2800 DB '3, 4, 5', 0aH, 00H
3 $SG2802 DB '8, 9, 21', 0aH, 00H
4 $SG2804 DB '22', 0aH, 00H
5 $SG2806 DB 'default', 0aH, 00H
6
7 _a$ = 8
8 _f PROC
9 mov eax, DWORD PTR _a$[esp-4]
10 dec eax
11 cmp eax, 21
12 ja SHORT $LN1@f
13 movzx eax, BYTE PTR $LN10@f[eax];从eax寄存器指向的内存地址中读取一个字节(BYTE)大小的数据,然后无符号扩展这个字节到32位(DWORD),最后将扩展后的结果存储到eax寄存器中。
14 jmp DWORD PTR $LN11@f[eax*4]
15 $LN5@f:
16 mov DWORD PTR _a$[esp-4], OFFSET $SG2798 ; '1, 2, 7, 10'
17 jmp DWORD PTR __imp__printf
18 $LN4@f:
19 mov DWORD PTR _a$[esp-4], OFFSET $SG2800 ; '3, 4, 5'
20 jmp DWORD PTR __imp__printf
21 $LN3@f:
22 mov DWORD PTR _a$[esp-4], OFFSET $SG2802 ; '8, 9, 21'
23 jmp DWORD PTR __imp__printf
24 $LN2@f:
25 mov DWORD PTR _a$[esp-4], OFFSET $SG2804 ; '22'
26 jmp DWORD PTR __imp__printf
27 $LN1@f:
28 mov DWORD PTR _a$[esp-4], OFFSET $SG2806 ; 'default'
29 jmp DWORD PTR __imp__printf
30 npad 2 ; align $LN11@f table on 16-byte boundary
31 $LN11@f:
32 DD $LN5@f ; print '1, 2, 7, 10'
33 DD $LN4@f ; print '3, 4, 5'
34 DD $LN3@f ; print '8, 9, 21'
35 DD $LN2@f ; print '22'
36 DD $LN1@f ; print 'default'
37 $LN10@f:
38 DB 0 ; a=1 ;byte型1个字节
39 DB 0 ; a=2
40 DB 1 ; a=3
41 DB 1 ; a=4
42 DB 1 ; a=5
43 DB 1 ; a=6
44 DB 0 ; a=7
45 DB 2 ; a=8
46 DB 2 ; a=9
47 DB 0 ; a=10
48 DB 4 ; a=11
49 DB 4 ; a=12
50 DB 4 ; a=13
51 DB 4 ; a=14
52 DB 4 ; a=15
53 DB 4 ; a=16
54 DB 4 ; a=17
55 DB 4 ; a=18
56 DB 4 ; a=19
57 DB 2 ; a=20
58 DB 2 ; a=21
59 DB 3 ; a=22
60 _f ENDP汇编解读:
-
这里使用了两个表,一个是索引表$LN10@f,另一个转移表是$LN11@f
-
movzx是汇编语言中的一个指令,它是move with zero extend的缩写,用于无符号扩展并传送数据。此指令主要用于将一个较小位宽的数据(通常是8位或16位)加载到一个较大位宽的寄存器或内存位置中,并在扩展高位时用0填充。1mov bl, 80h ; 将8位立即数80h送入8位寄存器BL 2movzx ax, bl ; 将BL的内容无符号扩展到16位,并放入AX寄存器在这个例子中,
BL寄存器中的值是80h(十进制128),当使用movzx指令将BL的内容复制到AX寄存器时,因为是无符号扩展,所以BL的值被扩展为0080h(前导的高位补0),这样AX寄存器的值就变成了0080h。 -
首先movzx指令在索引表中查询输入值,返回0(input1,2,7,10);1(input3,4,5),2(input8,9,21),3(input 22)4(default)
-
然后把缩影表的返回值,在第二个转移表中完成跳转s
fall-through
1 #define R 1
2 #define W 2
3 #define RW 3
4
5 void f(int type)
6 {
7 int read=0, write=0;
8
9 switch (type)
10 {
11 case RW:
12 read=1;
13 case W:
14 write=1;
15 break;
16 case R:
17 read=1;
18 break;
19 default:
20 break;
21 };
22 printf ("read=%d, write=%d\n", read, write);
23 };无论type的值是RW还是W,程序都会执行第14行的指令。type为RW的陈述语句里没有break指令,从而利用switch语句的fall through效应。
msvs x86 nasm
$SG1305 DB 'read=%d, write=%d', 0aH, 00H
_write$ = -12 ; size= 4
_read$ = -8 ; size= 4
tv64 = -4 ; size= 4
_type$ = 8 ; size= 4
_f PROC
push ebp
mov ebp, esp
sub esp, 12;int write,read,tv64
mov DWORD PTR _read$[ebp], 0;read=0
mov DWORD PTR _write$[ebp], 0;write=0
mov eax, DWORD PTR _type$[ebp];eax=type
mov DWORD PTR tv64[ebp], eax;tv64=type
cmp DWORD PTR tv64[ebp], 1 ; R
je SHORT $LN2@f
cmp DWORD PTR tv64[ebp], 2 ; W
je SHORT $LN3@f;无break语句
cmp DWORD PTR tv64[ebp], 3 ; RW
je SHORT $LN4@f
jmp SHORT $LN5@f;break
$LN4@f: ; case RW:
mov DWORD PTR _read$[ebp], 1
$LN3@f: ; case W:
mov DWORD PTR _write$[ebp], 1
jmp SHORT $LN5@f
$LN2@f: ; case R:
mov DWORD PTR _read$[ebp], 1
$LN5@f: ;printf
mov ecx, DWORD PTR _write$[ebp]
push ecx
mov edx, DWORD PTR _read$[ebp]
push edx
push OFFSET $SG1305 ; 'read=%d, write=%d'
call _printf
add esp, 12
mov esp, ebp
pop ebp
ret 0
_f ENDPChap14 循环
x86指令集里有一条专门的LOOP指令。LOOP指令检测ECX寄存器的值是否是0,如果它不是0则将其递减,并将操作权交给操作符所指定的标签处(即跳转)。或许是因为循环指令过于复杂的缘故,至今尚未见过直接使用LOOP指令将循环语句转译成汇编语句的编译器。所以,如果哪个程序直接使用LOOP指令进行循环控制,那它很可能就是手写的汇编程序。
for
#include <stdio.h>
void printing_function(int i)
{
printf ("f(%d)\n", i);
};
int main()
{
int i;
for (i=2; i<10; i++)
printing_function(i);
return 0;
};_i$ = -4
_main PROC
push ebp
mov ebp, esp
push ecx
mov DWORD PTR _i$[ebp], 2 ; 初始态;i=2
jmp SHORT $LN3@main
$LN2@main:
mov eax, DWORD PTR _i$[ebp] ; 循环控制语句:
add eax, 1 ; i递增1
mov DWORD PTR _i$[ebp], eax
$LN3@main:
cmp DWORD PTR _i$[ebp], 10 ; 判断是否满足循环条件 if i==10
jge SHORT $LN1@main ; 如果i=10 则终止循环语句
mov ecx, DWORD PTR _i$[ebp] ; 循环体: call f(i)
push ecx;传参
call _printing_function
add esp, 4
jmp SHORT $LN2@main ; 跳到循环开始处
$LN1@main: ;exit ; 循环结束
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDPgcc
main proc near ; 开始定义主程序过程
var_20 = dword ptr -20h ; 定义一个变量var_20,在栈上距离EBP-20h的位置
var_4 = dword ptr –4 ; 定义另一个变量var_4,在栈上距离EBP-4的位置
push ebp ; 保存当前基址指针(EBP)
mov ebp, esp ; 将栈顶指针(ESP)复制到基址指针(EBP),建立新的堆栈帧
and esp, 0FFFFFFF0h ; 确保ESP为16字节对齐,通过与操作去掉ESP的低4位
sub esp, 20h ; 在栈上为局部变量分配空间,减小ESP 32字节(20h)
mov [esp+20h+var_4], 2 ; 初始化变量var_4,即(i=2),这里存的是循环起始值
jmp short loc_8048476 ; 无条件跳转到循环条件检查处开始循环
loc_8048465: ; 循环体开始
mov eax, [esp+20h+var_4] ; 把计数器(i)的值加载到EAX寄存器
mov [esp+20h+var_20], eax ; 把EAX的值(即i的值)存入var_20,可能是为调用准备参数
call printing_function ; 调用打印函数,可能打印var_20中的值
add [esp+20h+var_4], 1 ; 将计数器(i)加1,即i=i+1
loc_8048476: ; 循环条件检查
cmp [esp+20h+var_4], 9 ; 比较计数器(i)是否小于等于9
jle short loc_8048465 ; 如果i<=9,则跳转回循环体继续执行
mov eax, 0 ; 设置返回值为0,这里作为程序正常退出的标志
leave ; 恢复先前的堆栈状态,将ESP设置回EBP的值,然后弹出EBP
retn ; 返回调用者,结束程序
main endp ; 结束主程序过程定义msvs开启优化
_main PROC
push esi
mov esi, 2
$LL3@main:
push esi
call _printing_function
inc esi
add esp, 4
cmp esi, 10 ; 0000000aH
jl SHORT $LL3@main
xor eax, eax
pop esi
ret 0
_main ENDP开启优化后,ESI寄存器成了计数器i的专用寄存器,大幅简洁了汇编s
进行这种优化的前提条件是:被调用方函数不应当修改局部变量专用寄存器的值。当然,在本例中编译器能够判断函数printing_function ()不会修改ESI寄存器的值。在编译器决定给局部变量分配专用寄存器的时候,它会在函数序言部分保存这些专用寄存器的初始状态,然后在函数尾声里还原这些寄存器的原始值,因此存在push esi和pop esi来还原原始值
gcc -O3 -o 1 1,c
main proc near
var_10 = dword ptr -10h
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 10h
mov [esp+10h+var_10], 2
call printing_function
mov [esp+10h+var_10], 3
call printing_function
mov [esp+10h+var_10], 4
call printing_function
mov [esp+10h+var_10], 5
call printing_function
mov [esp+10h+var_10], 6
call printing_function
mov [esp+10h+var_10], 7
call printing_function
mov [esp+10h+var_10], 8
call printing_function
mov [esp+10h+var_10], 9
call printing_function
xor eax, eax
leave
retn
main endp-
在这里,gcc把循环指令给分解了(就是给展开了)
编译器会对迭代次数较少的循环进行循环分解(Loop unwinding)对处理。展开循环体以后代码的执行效率会有所提升,但是会增加程序代码的体积。
-
如果迭代次数多的话,gcc的优化代码就与msvs相差无几
public main main proc near var_20 = dword ptr -20h push ebp mov ebp, esp and esp, 0FFFFFFF0h push ebx mov ebx, 2 ; i=2 sub esp, 1Ch ; aligning label loc_80484D0 (loop body begin) by 16-byte border: nop loc_80484D0: ; pass (i) as first argument to printing_function(): mov [esp+20h+var_20], ebx add ebx, 1 ; i++ call printing_function cmp ebx, 64h ; i==100? jnz short loc_80484D0 ; if not, continue add esp, 1Ch xor eax, eax ; return 0 pop ebx mov esp, ebp pop ebp retn main endp区别在于gcc是拿ebx作为i的专有寄存器,其他与msvs类似
内存块复制
#include <stdio.h>
void my_memcpy (unsigned char* dst, unsigned char* src, size_t cnt)
{
size_t i;
for (i=0; i<cnt; i++)
dst[i]=src[i];
};gcc -Os
; RDI = 目标地址;dst
; RSI = 源地址;src
; RDX = 块大小;cnt
; 在 0 的位置初始化计数器(i)
xor eax, eax
.L2:
; 如果所有字节已复制,则退出:
cmp rax, rdx ; 对寄存器rax和rdx的值进行比较。
je .L5 ; 如果这两个值相等(即已经拷贝了规定的字节数),就跳转到.L5,即返回(ret)。
; 在 RSI+i 处加载字节:
mov cl, BYTE PTR [rsi+rax] ; 将地址为(rsi+rax)的一个字节值加载到cl寄存器中。
; 在 RDI+i 处存储字节:
mov BYTE PTR [rdi+rax], cl ; 将cl寄存器的值存储到地址为(rdi+rax)的内存中。
inc rax ; i++,将rax寄存器的值增加1,以便下一次复制下一个字节。
jmp .L2 ; 无条件跳转到.L2,进行下一轮的比较和字节拷贝。
.L5:
ret ; 函数返回,结束拷贝操作。总结
MOV [counter], 2 ; initialization
JMP label_check
label_increment:
ADD [counter], 1 ; increment
label_check:
CMP [counter], 10
JGE exit
; loop body
; do something here
; use counter variable in local stack
JMP label_increment
exit:通常情况下,程序应当首先判断循环条件是否满足,然后再执行循环体。但是在编译器确定第一次迭代肯定会发生的情况下,它可能会调换循环体和判断语句的顺序。下面这个程序就是个典型的例子。
指令清单14.19 x86
MOV REG, 2 ; initialization
body:
; loop body
; do something here
; use counter in REG, but do not modify it!
INC REG ; increment
CMP REG, 10
JL body编译器不会使用LOOP指令。由LOOP控制的循环控制语句比较少见。如果某段代码带有LOOP指令,那么您应当认为这是手写出来的汇编程序。
; count from 10 to 1
MOV ECX, 10
body:
; loop body
; do something here
; use counter in ECX, but do not modify it!
LOOP bodyECX作为count的专用寄存器
Problem
for(i=100;i>0;i--)
{
printf("%d";i);
}for(i=1;i<100;i+=3)
{
printf("%d\n",i);
}Chap15 C语言字符串的函数
strlen()
int my_strlen(const char * str)
{
const char *eos=str;
while(*eos++);
return(eos-str-1);
}
int main()
{
return my_strlen("hello!");
}Non-optimizing MSVS
_eos$ = -4 ; 定义局部变量eos的栈偏移量为-4
_str$ = 8 ; 定义参数str的栈偏移量为8
_strlen PROC
push ebp ; 保存基址指针
mov ebp, esp ; 设置新的基址指针
push ecx ; 保存ecx寄存器的值
mov eax, DWORD PTR _str$[ebp] ; 将传入的字符串指针存储到eax中
mov DWORD PTR _eos$[ebp], eax ; 将eax的值(即字符串指针)保存到局部变量eos 中
$LN2@strlen_:
mov ecx, DWORD PTR _eos$[ebp] ; 将eos的值加载到ecx中
; 从ecx指向的地址处取8位字节,并将其作为32位值(带符号扩展)加载到edx中
movsx edx, BYTE PTR [ecx];edx=*eos
mov eax, DWORD PTR _eos$[ebp] ; 将eos的值加载到eax中
add eax, 1 ; 将eax自增1,指向下一个字符
mov DWORD PTR _eos$[ebp], eax ; 将更新后的eax值保存回eos中
test edx, edx ; 测试edx寄存器(即当前字符是否为0)
je SHORT $LN1@strlen_ ; 如果edx为0,跳转到$LN1@strlen_,结束循环
jmp SHORT $LN2@strlen_ ; 否则,继续循环
$LN1@strlen_:
; 计算两个指针之间的差值
mov eax, DWORD PTR _eos$[ebp] ; 将eos的值加载到eax中
sub eax, DWORD PTR _str$[ebp] ; 用eos减去原始字符串指针
sub eax, 1 ; 减去1,得到字符串长度(不包括结尾的空字符)
mov esp, ebp ; 恢复栈指针
pop ebp ; 恢复基址指针
ret 0 ; 返回结果(eax中保存着字符串长度)
_strlen ENDP-
MOVSX,即MOV with Sign Extend,从内存中读取8位数据,并存储到32位寄存器里本例中,MOVSX将用原始数据的8位数据填充EDX寄存器的低8位;如果原始数据是负数,该指令将使用1填充第8到第31位(高24位),否则使用0填充高24位。
这是为了保证有符号型数据在类型转换后的数值保持不变。
举了个例子
假如char型数据的原始值是−2(0xFE),直接把整个字节复制到int型数据的最低8位上时,int型数据的值就变成0x000000FE,以有符号型数据的角度看它被转换为254了,而没有保持原始值−2。−2对应的int型数据是0xFFFFFFFE。所以,在把原始数据复制到目标变量之后,还要使用符号标志位填充剩余的数据,而这就是MOVSX的功能。
Non-optimizing GCC
public strlen ; 公共标志,使得其他模块可以调用该函数
strlen proc near ; 声明一个near过程,命名为strlen
eos = dword ptr -4 ; 定义局部变量eos的栈偏移量为-4
arg_0 = dword ptr 8 ; 定义参数arg_0(字符串指针)的栈偏移量为8
push ebp ; 保存基址指针
mov ebp, esp ; 设置新的基址指针
sub esp, 10h ; 为局部变量分配16字节的栈空间
mov eax, [ebp+arg_0] ; 将传入的字符串指针加载到eax中
mov [ebp+eos], eax ; 将eax的值(即字符串指针)保存到局部变量eos中
loc_80483F0:
mov eax, [ebp+eos] ; 将eos的值加载到eax中
movzx eax, byte ptr [eax] ; 从eax指向的地址处加载一个字节,并零扩展为32位
test al, al ; 测试al寄存器的值(即当前字符是否为0)
setnz al ; 如果al不为零,al = 1;否则,al = 0
add [ebp+eos], 1 ; 将eos自增1,指向下一个字符
test al, al ; 测试al寄存器的值(即当前字符是否为零)
jnz short loc_80483F0 ; 如果al不为零,跳转到loc_80483F0,继续循环
; 循环结束(当前字符为0),计算字符串的长度
mov edx, [ebp+eos] ; 将eos的值加载到edx中
mov eax, [ebp+arg_0] ; 将传入的字符串指针加载到eax中
mov ecx, edx ; 将edx的值加载到ecx中
sub ecx, eax ; ecx = edx - eax,计算eos与字符串起始地址的差值
mov eax, ecx ; 将ecx的值加载到eax中
sub eax, 1 ; eax减去1,得到字符串的实际长度(不包括结尾的空字符)
leave ; 恢复栈指针和基址指针
retn ; 返回结果(eax中保存着字符串长度)
strlen endp ; 过程结束-
这里
sub esp,10h,eos只需要4个字节,但是为了满足对齐要求分配了额外的12个字节 -
MOVZX是MOV with Zero-Extent的缩写,将8位或16位数据转换为32位数据的时候,它直接复制原始数据到目标寄存器的相应低位,并且使用0填充剩余的高位。==相当于一步完成了“xor eax, eax”和“mov al,[源8/16位数据]”2条指令
-
SETNZ指令:如果AL的值不是0,则“test al, al”指令会设置标志寄存器ZF=0;而SETNZ(Not Zero)指令会在ZF=0的时候,设置AL=1。用白话解说,就是:如果AL不等于0,则跳到loc_80483F0处。编译器转译出来的代码中,有些代码确实没有实际意义
Optimizing MSVS
_str$ = 8 ; size = 4
_strlen PROC
mov edx, DWORD PTR _str$[esp-4] ;用EDX作字符串指针
mov eax, edx ; 复制到 EAX
$LL2@strlen:
mov cl, BYTE PTR [eax] ; CL = *EAX
inc eax ; EAX++
test cl, cl ; CL==0?
jne SHORT $LL2@strlen ; no, continue loop
sub eax, edx ; 计算指针的变化量
dec eax ; decrement EAX
ret 0
_strlen ENDPOptimizing GCC -O3
public strlen
strlen proc near
arg_0 = dword ptr 8
push ebp
mov ebp, esp
mov ecx, [ebp+arg_0];ecx=arg_0;
mov eax, ecx;eax=arg_0
loc_8048418:
movzx edx, byte ptr [eax];edx=*eop
add eax, 1;eop++
test dl, dl;if dl ==0?
jnz short loc_8048418;dl !=0,loop
not ecx
add eax, ecx
pop ebp
retn
strlen endp-
movzx替换为mov dl byte ptr[eax]也可,使用movzx或许是为了保证寄存器的高地址位不含有噪音数据 -
NOT,NOT指令对操作数的所有bit都进行非运算,等价于XOR ECX,0xfffffffh,not ecx的结果与某数相加,相当于某数减去ECX然后再减1从而得到正确的字符串长度
not ecx相当于ecx=(-ecx)-1,由位运算可以推导
Problems:
_s$ = 8
_f PROC
mov edx, DWORD PTR _s$[esp-4];edx=_s
mov cl, BYTE PTR [edx];cl=*_s=8
xor eax, eax
test cl, cl
je SHORT $LN2@f;if cl==0,exit
npad 4 ; align next label
$LL4@f:
cmp cl, 32;
jne SHORT $LN3@f;if cl!=32,jmp LN3
inc eax;eax++
$LN3@f:
mov cl, BYTE PTR [edx+1];cl=*(_s+1)
inc edx;eax++
test cl, cl
jne SHORT $LL4@f;if cl!=0;jmp LL4
$LN2@f:
ret 0
_f ENDP
int func(char *_s)
{
int count=0;
while(*_s++)
{
if(*_s==32);//' '相当于统计字符串的空格数
{
count++;
}
}
return count;
}.LFB24:
push ebx ; 保存 ebx 寄存器的值
mov ecx, DWORD PTR [esp+8] ; 将参数(假设是字符串指针)传递给 ecx
xor eax, eax ; 将 eax 寄存器清零 (计数器)
movzx edx, BYTE PTR [ecx] ; 将字符串的第一个字符加载到 edx
test dl, dl ; 测试该字符是否为 null (字符串结尾)
je .L2 ; 如果是 null, 跳转到 .L2 结束
.L3:
cmp dl, 32 ; 比较该字符与空格 (ASCII 32)
lea ebx, [eax+1] ; 计算当前计数器值加1的地址
cmove eax, ebx ; 如果字符是空格,eax = ebx (即eax加1)
add ecx, 1 ; 将 ecx 指针前移一个字符
movzx edx, BYTE PTR [ecx] ; 将下一个字符加载到 edx
test dl, dl ; 测试该字符是否为 null
jne .L3 ; 如果不是 null, 跳转到 .L3 继续处理
.L2:
pop ebx ; 恢复 ebx 寄存器的值
ret ; 返回
cmove指令是 x86 汇编中的条件移动指令之一,它的全名是conditional move if equal。这意味着当满足给定条件时,从源操作数移动到目标操作数,而如果条件不成立,则不进行移动.如果比较结果是相等(即当前字符是空格)eax=ebx=eax+1
int func(char *str)
{
int count=0;
while(*str++)
{
int temp=count+1;
if(*str==32)
{
count=temp;
}
}
return count;
}进一步简化代码就是计数所有空格字符
Chap16 数学计算指令的替换
出于性能优化的考虑,编译器可能会将1条数学运算指令替换为其他的1条、甚至是一组等效指令。例如LEA指令通常替代其他简单计算指令,ADD与SUB同样可以相互替换
乘法
替换为加法运算
unsigned int f(unsigned int a)
{
return a*8;
};使用MSVC 2010(启用/Ox)进行编译,编译器会把“乘以8”的运算指令拆解为3条加法指令。
mov eax, DWORD PTR _a$[esp-4]
add eax, eax
add eax, eax
add eax, eax
ret 0 替换为移位运算
编译器通常会把“乘以2”“除以2”的运算指令处理为位移运算指令
unsigned int f(unsigned int a)
{
return a*4;
};_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
shl eax, 2;shift left
pop ebp
ret 0
_f ENDP替换为移位,加减法的混合运算
即使乘数是7或17,乘法运算仍然可以用非乘法运算指令配合位移指令实现。
#include <stdint.h>
int f1(int a)
{
return a*7;
};
int f2(int a)
{
return a*28;
};
int f3(int a)
{
return a*17;
};; a*7
_a$ = 8
_f1 PROC
mov ecx, DWORD PTR _a$[esp-4]
; ECX=a
lea eax, DWORD PTR [ecx*8]
; EAX=ECX*8
sub eax, ecx
; EAX=EAX-ECX=ECX*8-ECX=ECX*7=a*7
ret 0
_f1 ENDP
; a*28
_a$ = 8
_f2 PROC
mov ecx, DWORD PTR _a$[esp-4]
; ECX=a
lea eax, DWORD PTR [ecx*8]
; EAX=ECX*8
sub eax, ecx
; EAX=EAX-ECX=ECX*8-ECX=ECX*7=a*7
shl eax, 2
; EAX=EAX<<2=(a*7)*4=a*28
ret 0
_f2 ENDP
; a*17
_a$ = 8
_f3 PROC
mov eax, DWORD PTR _a$[esp-4]
; EAX=a
shl eax, 4
; EAX=EAX<<4=EAX*16=a*16
add eax, DWORD PTR _a$[esp-4]
; EAX=EAX+a=a*16+a=a*17
ret 0
_f3 ENDP除法运算
替换为位移运算
unsigned int f(unsigned int a)
{
return a/4;
};shr eax,2
Problem
_a$ = 8
_f PROC
mov ecx, DWORD PTR _a$[esp-4];ecx=a
lea eax, DWORD PTR [ecx*8];eax=a*8
sub eax, ecx;eax=eax-a=7a
ret 0
_f ENDPChap17 FPU
-
FPU是专门处理浮点数的运算单元,是CPU的一个组件。 -
IEEE 754标准规定了计算机程序设计环境中的二进制和十进制的浮点数的交换、算术格式以及方法。符合这种标准的浮点数由符号位、尾数(又称为有效数字、小数位)和指数位构成。 -
在80486处理器问世之前,FPU(与CPU位于不同的芯片)叫作协作(辅助)处理器。而且那个时候的FPU还不属于主板的标准配置;如果想要在主板上安装FPU,人们还得单独购买它。
80486 DX之后的CPU处理器集成了FPU的功能。
若没有FWAIT指令和opcode以D8~DF开头的所谓的“ESC”字符指令(opcode以D8~DF开头),恐怕很少有人还会想起FPU属于独立运算单元的这段历史。FWAIT指令的作用是让CPU等待FPU运算结束,而ESC字符指令都在FPU上执行。
FPU自带一个由
8个80位寄存器构成的循环栈。这些80位寄存器用以存储IEEE 754格式的浮点数据,通常叫作ST(0)~ST(7)寄存器。IDA和OllyDbg都把ST(0)显示为ST。也有不少教科书把ST(0)叫作“栈顶/Stack Top”寄存器。
#include <stdio.h>
double f (double a, double b)
{
return a/3.14 + b*4.1;
};
int main()
{
printf ("%f\n", f(1.2, 3.4));
};CONST SEGMENT
__real@4010666666666666 DQ 04010666666666666r ; 4.1 ; 定义常量4.1,存储在段`CONST`中
CONST ENDS
CONST SEGMENT
__real@40091eb851eb851f DQ 040091eb851eb851fr ; 3.14 ; 定义常量3.14,存储在段`CONST`中
CONST ENDS
_TEXT SEGMENT
_a$ = 8 ; 变量`_a`的偏移量,相对于基指针(`ebp`)的8字节位置
_b$ = 16 ; 变量`_b`的偏移量,相对于基指针(`ebp`)的16字节位置
_f PROC ; `_f` 是一个过程(函数)
push ebp ; 保存调用者的栈帧基指针,把当前`ebp`值推入栈
mov ebp, esp ; 将栈指针`esp`的值保存在栈帧基指针`ebp`中,建立函数栈帧
fld QWORD PTR _a$[ebp]
; 将ebp偏移_a的值(即变量_a的值)加载到FPU(浮点运算单元)堆栈中
; 当前FPU堆栈状态: ST(0) = _a
fdiv QWORD PTR __real@40091eb851eb851f
; 将ST(0)中的值除以常量3.14,并将结果存储在ST(0)中
; 当前FPU堆栈状态: ST(0) = _a / 3.14
fld QWORD PTR _b$[ebp]
; 将ebp偏移_b的值(即变量_b的值)加载到FPU堆栈中
; 当前FPU堆栈状态: ST(0) = _b; ST(1) = _a / 3.14
fmul QWORD PTR __real@4010666666666666
; 将ST(0)中的值乘以常量4.1,并将结果存储在ST(0)中
; 当前FPU堆栈状态: ST(0) = _b * 4.1; ST(1) = _a / 3.14
faddp ST(1), ST(0)
; 将ST(0)和ST(1)中的值相加,并将结果存储在ST(1)中,
; 然后弹出堆栈顶(即ST(0)),堆栈平衡
; 当前FPU堆栈状态: ST(0) = (_a / 3.14) + (_b * 4.1)
pop ebp ; 恢复调用者的基指针,将栈顶的值弹出到`ebp`中
ret 0 ; 从函数返回,传递0个参数给调用者
_f ENDP ; 结束过程定义汇编解读
FLD指令从栈中读取8个字节,把这个值转换成FPU寄存器所需的80位数据格式,并存入ST(0)寄存器FDIV指令把ST(0)寄存器的值用作被除数,把参数__real@40091eb851eb851f(即3.14)的值当作除数.因为汇编语法不支持含有小数点的浮点立即数,所以程序使用64位IEEE 754格式的16进制数- 进行
FDIV运算之后,ST(0)寄存器将保存商 - 此外,
FDIVP也是FPU的除法运算指令。FDIVP在进行ST(1)/ST(0)运算时,先把两个寄存器的值POP出来进行运算,再把商推送入(PUSH)FPU的栈(即ST(0)寄存器)。 - 下一条
FLD指令把b送入FPU的栈中 - 此时
ST(1)寄存器里是上次除法运算的商,ST(0)寄存器里是变量b的值 - 接下来的
FMUL指令做乘法运算,它用ST(0)寄存器里的值(即变量b),乘以参数__real @4010666666666666(即4.1),并将运算结果(积)存储到ST(0)寄存器。 - 最后一条运算指令FADDP计算栈内顶部两个值的和。它
先把运算结果存储在ST(1)寄存器,再POP ST(0)。所以,运算表达式的运算结果存储在栈顶的ST(0)寄存器里。 - 根据有关规范,函数必须使用ST(0)寄存器存储浮点运算的返回结果。所以在FADDP指令之后,除了函数尾声的指令之外再无其他指令。
GCC -O3
; 定义过程 f,作为一个近过程
public f
f proc near
; 定义过程的参数
arg_0 = qword ptr 8 ; 第一个参数的偏移量,相对于`ebp`的8字节位置
arg_8 = qword ptr 10h ; 第二个参数的偏移量,相对于`ebp`的16字节位置
push ebp ; 把调用者的栈帧基指针`ebp`推入栈中,保留调用者的栈帧
fld ds:dbl_8048608 ; 加载全局数据段中的常量3.14到FPU(浮点运算单元)堆栈
; 当前栈状态: ST(0) = 3.14
mov ebp, esp ; 创建新的栈帧,ebp指向当前栈顶
fdivr [ebp+arg_0] ; 反除法指令,将ST(0)中的常量3.14除以第一个参数(arg_0)
; 当前栈状态: ST(0) = 除法结果 (3.14 / arg_0)
fld ds:dbl_8048610 ; 加载全局数据段中的常量4.1到FPU堆栈
; 当前栈状态: ST(0) = 4.1, ST(1) = 除法结果
fmul [ebp+arg_8] ; 将ST(0)中的4.1乘以第二个参数(arg_8)
; 当前栈状态: ST(0) = 乘法结果 (4.1 * arg_8), ST(1) = 除法结果
pop ebp ; 恢复调用者的栈帧,将栈顶的值弹出到ebp中
faddp st(1), st ; 将ST(0)和ST(1)相加,并将结果存储在ST(1)中,
; 然后弹出堆栈顶(即ST(0)),栈平衡
; 当前栈状态: ST(0) = 加法结果 ((3.14 / arg_0) + (4.1 * arg_8))
ret ; 从过程返回,返回地址从栈顶弹出
f endp ; 结束过程定义-
gcc把3.14送入FPU的栈中(ST(0)寄存器),用作arg_0的除数 -
FDIVR是Reverse Divide的缩写。FDIVR指令的除数和被除数,对应FDIV指令的被除数和除数,即位置相反,FDIV是ST[0]作为被除数,FDIVR是ST[0]作除数其他相同
利用参数传递浮点型
#include <math.h>
#include <stdio.h>
int main ()
{
printf ("32.01 ^ 1.54 = %lf\n", pow (32.01,1.54));
return 0;
}msvs x86
CONST SEGMENT
__real@40400147ae147ae1 DQ 040400147ae147ae1r ; 32.01 ; 定义常量32.01,存储在段`CONST`中
__real@3ff8a3d70a3d70a4 DQ 03ff8a3d70a3d70a4r ; 1.54 ; 定义常量1.54,存储在段`CONST`中
CONST ENDS
_main PROC ; 主过程 _main 的开始
push ebp ; 将调用者的栈帧基指针`ebp`推入栈,保留调用者的栈帧
mov ebp, esp ; 将当前栈顶指针`esp`的值赋给`ebp`,建立新的栈帧
sub esp, 8 ; 为第1个变量分配8个字节的栈空间
fld QWORD PTR __real@3ff8a3d70a3d70a4 ; 加载常量1.54到FPU(浮点运算单元)堆栈
fstp QWORD PTR [esp] ; 将FPU堆栈顶部(ST(0))的值存储到栈顶(对应第1个变量的空间)
sub esp, 8 ; 为第2个变量分配8个字节的栈空间
fld QWORD PTR __real@40400147ae147ae1 ; 加载常量32.01到FPU堆栈
fstp QWORD PTR [esp] ; 将FPU堆栈顶部的值存储到栈顶(对应第2个变量的空间)
call _pow ; 调用`_pow`函数计算幂(默认底数在 [esp + 8],指数在 [esp])
add esp, 8 ; 调整栈指针,释放第2个变量的空间
; 栈分配了8个字节的空间用于存储函数 `_pow` 的结果
; 运算结果存储于FPU堆栈的ST(0)寄存器
fstp QWORD PTR [esp] ; 将FPU堆栈顶部的值(`_pow`结果)存储到栈顶,供`printf()`使用
push OFFSET $SG2651 ; 推送格式字符串的地址到栈,用于`printf()`调用
call _printf ; 调用`printf()`函数打印结果
add esp, 12 ; 调整栈指针,释放用于`printf`调用的栈空间(8字节结果 + 4字节地址)
xor eax, eax ; 将`eax`寄存器置零,表示程序返回值为0
pop ebp ; 恢复调用者的栈帧,将栈顶的值弹出到`ebp`中
ret 0 ; 从过程返回,传递0个参数给调用者
_main ENDP ; 结束过程定义汇编解读
- FLD和FSTP指令是在数据段(SEGMENT)和FPU的栈间交换数据的指令。FLD把内存里的数据推送入FPU的栈,而FSTP则把FPU栈顶的数据
复制到内存中。这两个连用相当于使浮点数给入栈了,给pow传递参数 - pow()函数是指数运算函数,它从FPU的栈内读取两个参数进行计算,并把运算结果(x的y次幂)存储在ST(0)寄存器里。之后,printf()函数先从内存栈中读取8个字节的数据,再以双精度浮点的形式进行输出。
- 此外,这个例子里还可以直接成对使用MOV指令把浮点数据从内存复制到FPU的栈里。内存本身就把浮点数据存储为IEEE 754的数据格式,而pow()函数所需的参数就是这个格式的数据,所以此处没有格式转换的必要。
比较说明
#include <stdio.h>
double d_max (double a, double b)
{
if (a>b)
return a;
return b;
};
int main()
{
printf ("%f\n", d_max (1.2, 3.4));
printf ("%f\n", d_max (5.6, -4));
};Non-Optimizing MSVS
PUBLIC _d_max
_TEXT SEGMENT
_a$ = 8 ; 变量_a$在栈帧中的偏移,大小为8字节
_b$ = 16 ; 变量_b$在栈帧中的偏移,大小为8字节
_d_max PROC
push ebp ; 保存旧的基址指针
mov ebp, esp ; 将当前栈顶指针赋值给基址指针
fld QWORD PTR _b$[ebp]; 加载_b$,将其压入FPU堆栈的ST(0)寄存器
; 当前堆栈状态:ST(0) = _b
; 比较_b(ST(0))和_a$,然后弹出寄存器
fcomp QWORD PTR _a$[ebp]; 比较ST(0)和_a$,并弹出ST(0)
; 此时FPU堆栈为空
fnstsw ax ; 将FPU状态字存储到AX寄存器
test ah, 5 ; 检查AX寄存器的高8位的第0和第2位(对应的是C2,C0标志位)
jp SHORT $LN1@d_max ; 如果标志位有正数标志(a<=b),则跳转到$LN1@d_max
; 如果_a > _b,继续执行以下代码
fld QWORD PTR _a$[ebp]; 加载_a$,将其压入FPU堆栈的ST(0)
jmp SHORT $LN2@d_max ; 跳转到$LN2@d_max
$LN1@d_max:
fld QWORD PTR _b$[ebp]; 加载_b$,将其压入FPU堆栈的ST(0)
$LN2@d_max:
pop ebp ; 恢复基址指针
ret 0 ; 返回
_d_max ENDP-
FCOMP首先比较ST(0)与_a的值,然后根据比较的结果设置FPU状态字(寄存器)的C3/C2/C0位。FPU的状态字寄存器是一个16位寄存器,用于描述FPU的当前状态- 如果b>a,则C3、C2、C0寄存器的值会分别是0、0、0。
- 如果a>b,则寄存器的值会分别是0、0、1。
- 如果a=b,则寄存器的值会分别是1、0、0。
- 如果出现了错误(NaN或数据不兼容),则寄存器的值是1、1、1。
在设置好相应比特位之后,
FCOMP指令还会从栈里抛出(POP)一个值。FCOM与FCOMP的功能十分相似。FCOM指令只根据数值比较的结果设置状态字,而不会再操作FPU的栈。 -
FNSTSW指令在 x86 汇编中用于将浮点状态字(Floating Point Status Word)存储到指定位置或 AX 寄存器中F:操作前不等待FPU可用NST:No STore到内存操作SW:Status Word(状态字)C3/C2/C0标志位对应AX的第14/10/8位。
复制数值并不会改变标志位(bit)的数权(位置)。标志位会集中在AX寄存器的高地址位区域——即AH寄存器里。以AH来看:0:C0 1:C1 2:C2 6:C3
test ah, 5指令把ah的值(FPU标志位的加权求和值)和0101(二进制的5)做与(AND)运算,并设置标志位。影响test结果的只有第0比特位的C0标志位和第2比特位的C2标志位,因为其他的位都会被置零。 -
奇偶校验位PF(parity flag)的介绍
PF标志位的作用是判定运算结果中的“1”的个数,如果“1”的个数为偶数,则PF的值为1,否则其值为0。
检验奇偶位通常用于判断处理过程是否出现故障,并不能判断这个数值是奇数还是偶数。FPU有四个条件标志位(C0到C3)。但是,必须把标志位的值组织起来、存放在标志位寄存器中,才能进行奇偶校验位的正确性验证。FPU标志位的用途各有不同:C0位是进位标志位CF,C2是奇偶校验位PF,C3是零标志位ZF
在使用FUCOM指令(FPU比较指令的通称)时,如果操作数里出现了不可比较的浮点值(非数值型内容NaN或其他无法被指令支持的格式),则C2会被设为1。
如果C0和C2都是0或都是1,则设PF标志为1并触发JP跳转(Jump on Parity)。前面对C3/C2/C0的取值进行了分类讨论,C2和C0的数值相同的情况分为b>a和 a=b这两种情况。因为test指令把ah的值与5进行“与”运算,所以C3的值无关紧要。
在此之后的指令就很简单了。如果触发了JP跳转,则FLD指令把变量_b的值复制到ST(0)寄存器,否则变量_a的值将会传递给ST(0)寄存器。
如果需要检测C2的状态
如果TEST指令遇到错误(NaN等情形),则C2标志位的值会被设置为1。不过我们的程序不检测这类错误。
如果编程人员需要处理FPU的错误,他就不得不添加额外的错误检查指令。
Optimizing MSVS 2010
_a$ = 8 ; size = 8
_b$ = 16 ; size = 8
_d_max PROC
fld QWORD PTR _b$[esp-4]
fld QWORD PTR _a$[esp-4]
; current stack state: ST(0) = _a, ST(1) = _b
fcom ST(1) ; compare _a and ST(1) = (_b)
fnstsw ax
test ah, 65 ; 00000041H
jne SHORT $LN5@d_max
; copy ST(0) to ST(1) and pop register,
; leave (_a) on top
fstp ST(1)
; current stack state: ST(0) = _a
ret 0
$LN5@d_max:
; copy ST(0) to ST(0) and pop register,
; leave (_b) on top
fstp ST(0)
; current stack state: ST(0) = _b
ret 0
_d_max ENDP-
FCOM指令和前面用过的FCOMP指令略有不同,它不操作FPU栈。而且本例的操作数也和前文有区别,这里它是逆序的。所以,FCOM生成的条件标志位的涵义也与前例不同。
- 如果a>b,则C3、C2、C0位的值分别为0、0、0。
- 如果b>a,则对应数值为0、0、1。
- 如果a=b,则对应数值为1、0、0。
-
是说,“test ah, 65”这条指令仅仅比较两个标志位——C3(第6位/bit)和C0(第0位/bit)。在a>b的情况下,两者都应为0:这种情况下,程序不会被触发JNE跳转,并会执行后面的FSTP ST(1)指令,把ST(0)的值复制到操作数中,然后从FPU栈里抛出一个值。换句话说,这条指令把ST(0)的值(即变量_a的值)复制到ST(1)寄存器;此后栈顶的2个值都是_a。然后,相当于POP出一个值来,使ST(0)寄存器的值为_a,函数随即结束。
在b>a或a==b的情况下,程序将触发条件转移指令JNE。从ST(0)取值、再赋值给ST(0)寄存器,相当于NOP操作没有实际意义。接着它从栈里POP出一个值,使ST(0)的值为先前ST(1)的值,也就是变量_b。然后结束本函数。大概是因为FPU的指令集里没有POP并舍弃栈顶值的指令,所以才会出现这样的汇报指令。
Chap18 数组
#include <stdio.h>
int main()
{
int a[20];
int i;
for (i=0; i<20; i++)
a[i]=i*2;
for (i=0; i<20; i++)
printf ("a[%d]=%d\n", i, a[i]);
return 0;
};用msvs 2008 进行编译
_TEXT SEGMENT
_i$ = -84 ; size = 4
_a$ = -80 ; size = 80
_main PROC
push ebp
mov ebp, esp
sub esp, 84 ; 00000054H
mov DWORD PTR _i$[ebp], 0;i=0
jmp SHORT $LN6@main
$LN5@main:;i+=1
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN6@main:
cmp DWORD PTR _i$[ebp], 20; 00000014H
jge SHORT $LN4@main
mov ecx, DWORD PTR _i$[ebp];i<20
shl ecx, 1;ecx*2=2i
mov edx, DWORD PTR _i$[ebp]
mov DWORD PTR _a$[ebp+edx*4], ecx;a[i]=2i
jmp SHORT $LN5@main
$LN4@main:;i=0
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN3@main
$LN2@main:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN3@main:;for i in range(20) printf(a[i])
cmp DWORD PTR _i$[ebp], 20 ; 00000014H
jge SHORT $LN1@main;ret
mov ecx, DWORD PTR _i$[ebp]
mov edx, DWORD PTR _a$[ebp+ecx*4]
push edx
mov eax, DWORD PTR _i$[ebp]
push eax
push OFFSET $SG2463
call _printf
add esp, 12 ; 0000000cH
jmp SHORT $LN2@main
$LN1@main:
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP- 程序为数组申请了80字节的栈空间,以存储20个4字节元素。
- 因为全部数组都存储于栈中,所以我们可以在内存数据窗口里看到整个数组。
gcc
public main
main proc near ; DATA XREF: _start+17
var_70 = dword ptr -70h
var_6C = dword ptr -6Ch
var_68 = dword ptr -68h
i_2 = dword ptr -54h
i = dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h;对齐
sub esp, 70h
mov [esp+70h+i], 0 ; i=0
jmp short loc_804840A
loc_80483F7:
mov eax, [esp+70h+i]
mov edx, [esp+70h+i]
add edx, edx ; edx=i*2
mov [esp+eax*4+70h+i_2], edx
add [esp+70h+i], 1 ; i++
loc_804840A:
cmp [esp+70h+i], 13h;19
jle short loc_80483F7;i<=19
mov [esp+70h+i], 0;i=0
jmp short loc_8048441
loc_804841B:
mov eax, [esp+70h+i]
mov edx, [esp+eax*4+70h+i_2]
mov eax, offset aADD ; "a[%d]=%d\n"
mov [esp+70h+var_68], edx
mov edx, [esp+70h+i]
mov [esp+70h+var_6C], edx
mov [esp+70h+var_70], eax
call _printf
add [esp+70h+i], 1
loc_8048441:
cmp [esp+70h+i], 13h
jle short loc_804841B;i<=19
mov eax, 0
leave
retn
main endp-
实际上变量==a的数据类型是整型指针。严格地说,在把数组传递给函数的时候,传递的数据就是指向第一个元素的指针,我们再根据这个指针就可以轻松地计算出数组每个元素的地址(即指针)。==如果使用a[idx]的形式表示数组元素,其中idx是数组元素在数组里的排列序号(即索引号),那么就可以通过数组第一个元素的地址、索引号和数据容量求得各个元素的地址。
举个典型的例子:字符串常量“string”是字符型数组,它的每个字符元素都是const char*型数据。使用索引号之后,我们就可以使用“string”[i]的形式描述字符串中的第i个字符——这正是C/C++表达式的表示方法!
缓冲区溢出
从汇编代码可以看出:编译器没有对索引进行判断,
可以访问a[20]
向数组边界之外的地址赋值
#include <stdio.h>
int main()
{
int a[20];
int i;
for (i=0; i<30; i++)
a[i]=i;
return 0;
};程序发生了崩溃
使用onlydbg加载,跟踪程序崩溃原因
-
当30个循环结束后,
EIP的值是0x15,显然不合法,此时EBP为0x14,ECX和EDX值为0x1DWhy?
-
首先回顾栈的结构
,main()函数的栈结构如下:
ESP i所占用的4字节 ESP+4 a[20]占用的80字节 ESP+84 保存过的EBP ESP+88 返回地址 赋值给a[19]的时候,数组a[]已经被全部赋值。
赋值给a[20]实际上修改的是栈里保存的
EBP,本例中将20赋值了给a[10],函数退出之前会将ebp设置为这个值,因此ebp为0x14最后运行
RET指令,相当于POP EIP,RET指令将程序的控制权传递给栈里的返回地址,不过此时这个值为0x15,这里没有可执行代码,因此崩溃 -
事实上,这就是缓冲区溢出攻击的原理,我们可以劫持返回地址来控制eip来跳转到其他程序的地址
目前已经有了很多手段来防御这种攻击,学pwn的时候再深入了解
-
canary,随机写入随机数,在函数结束之前检查这些值是否发生变化
-
如果启用MSVC的RTC1和RTCs选项编译本章开头的那段程序,就会在汇编指令里看到函数在退出之前调用@_RTC_CheckStackVars@8,用以检测“百灵鸟”是否会报警。
-
用gcc编译
mov eax, DWORD PTR [ebp-12] xor eax, DWORD PTR gs:20; jne .L5 mov ebx, DWORD PTR [ebp-4] .L5: call __stack_chk_fail显然随机值位于gs:20,
-
-
gs开头的寄存器就是常说的段寄存器。在MS-DOS和基于DOS的系统里,段寄存器的作用很广泛。但是,今天它的作用发生了变化。简单地说,Linux下的gs 寄存器总是指向TLS(参见第65章)——存储线程的多种特定信息。(Win32环境下的fs寄存器起到Linux下gs寄存器的作用。Win32的fs寄存器指向TIB)
其他
现在我们应该可以理解为什么C/C++编译不了下面的程序了。
void f(int size)
{
int a[size];
...
};在编译阶段,编译器必须确切地知道需要给数组分配多大的存储空间,它需要事先明确分配局部栈或数据段(全局变量)的格局,所以编译器无法处理上述这种长度可变的数组。
如果无法事先确定数组的长度,那么我们就应当使用malloc()函数分配出一块内存,然后直接按照常规变量数组的方式访问这块内存;或者遵循C99标准(参见ISO07,6.7.5/2)进行处理,但是遵循C99标准而设计出来的程序,内部实现的方法更接近alloca()函数(详情请参阅5.2.4节)。
字符串指针
#include <stdio.h>
const char* month1[]=
{
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December"
};
// in 0..11 range
const char* get_month1 (int month)
{
return month1[month];
};msvs x64
_DATA SEGMENT
month1 DQ FLAT:$SG3122
DQ FLAT:$SG3123
DQ FLAT:$SG3124
DQ FLAT:$SG3125
DQ FLAT:$SG3126
DQ FLAT:$SG3127
DQ FLAT:$SG3128
DQ FLAT:$SG3129
DQ FLAT:$SG3130
DQ FLAT:$SG3131
DQ FLAT:$SG3132
DQ FLAT:$SG3133
$SG3122 DB 'January', 00H
$SG3123 DB 'February', 00H
$SG3124 DB 'March', 00H
$SG3125 DB 'April', 00H
$SG3126 DB 'May', 00H
$SG3127 DB 'June', 00H
$SG3128 DB 'July', 00H
$SG3129 DB 'August', 00H
$SG3130 DB 'September', 00H
$SG3156 DB '%s', 0aH, 00H
$SG3131 DB 'October', 00H
$SG3132 DB 'November', 00H
$SG3133 DB 'December', 00H
_DATA ENDS
month$ = 8
get_month1 PROC
movsxd rax, ecx
lea rcx, OFFSET FLAT:month1
mov rax, QWORD PTR [rcx+rax*8]
ret 0
get_month1 ENDP- MOVSXD把ECX的32位整型数值、连同其符号扩展位(sign-extension)扩展为64位整型数据,再存储于RAX寄存器中。ECX存储的“月份”信息是32位整形数据。因为程序随后还要进行64位运算,所以需要把输入变量转换为64位值。
- 然后函数把
指针表的地址存储于RCX寄存器。 - 最后,函数的输
入变量(month)的值乘以8、再与指针表的地址相加。因为是64位系统的缘故,每个地址(即指针)的数据需要占用64位(即8字节)。所以指针表中的每个元素都占用8字节空间。因此,最终字符串的地址要加上month*8。MOV指令不仅完成了字符串地址的计算,而且还完成了指针表的查询。在输入值为1时,函数将返回字符串“February”的指针地址。
Optimizing gcc
movsx rdi, edi
mov rax, QWORD PTR month1[0+rdi*8]
retOptimizing MSVS
_month$ = 8
_get_month1 PROC
mov eax, DWORD PTR _month$[esp-4]
mov eax, DWORD PTR _month1[eax*4]
ret 0
_get_month1 ENDP32位程序就不用把输入值转化为64位数据了。此外,32位系统的指针属于4字节数据,所以相关的计算因子变为了4。
多维数组
计算机内存是连续的线性空间,它可以与一维数组直接对应。在被拆分成多个一维数组之后,多维数组与内栈线性空间同样存在直接对应的存储关系。
| 存储地址 | 数组元素 |
|---|---|
| 0 | [0] [0] |
| 1 | [0] [1] |
| 2 | [0] [2] |
| 3 | [0] [3] |
| 4 | [1] [0] |
| 5 | [1] [1] |
| 6 | [1] [2] |
| 7 | [1] [3] |
| 8 | [2] [0] |
| 9 | [2] [1] |
| 10 | [2] [2] |
| 11 | [2] [3] |
在内存之中,3×4的二维数组将依次存储为连续的12个元素,如表18.2所示。
在计算上述数组中某个特定元素的内存存储编号时,可以先将二维索引号的第一个索引号乘以4(矩阵宽度),而后加上第二个索引号。这种方式就是C/C++、Python所用的“行优先的顺序”(row-majororder)。所谓行优先,就是先用第一行排满第一个索引号下的所有元素,然后再依次编排其他各行。
从性能及缓存的角度来看,与数据的存储方案(scheme)和组织方式(data organization)匹配的优先顺序最优。只要相互匹配,那么程序就可以连续访问数据,整体性能就会提高。所以,如果程序以“逐行”的方式访问数据,那么就应当以行优先的顺序组织数组;反之亦然。
显然根据这种规则我们可以利用一维数组的方式访问二维数组
例如
#include <stdio.h>
char a[3][4];
char get_by_coordinates1 (char array[3][4], int a, int b)
{
return array[a][b];
};
char get_by_coordinates2 (char *array, int a, int b)
{
// treat input array as one-dimensional
// 4 is array width here
return array[a*4+b];
};
char get_by_coordinates3 (char *array, int a, int b)
{
// treat input array as pointer,
// calculate address, get value at it
// 4 is array width here
return *(array+a*4+b);
};
int main() {
a[2][3]=123;
printf ("%d\n", get_by_coordinates1(a, 2, 3));
printf ("%d\n", get_by_coordinates2(a, 2, 3));
printf ("%d\n", get_by_coordinates3(a, 2, 3));
};Optimizing gcc
; RDI=address of array
; RSI=a
; RDX=b
get_by_coordinates1:
; sign-extend input 32-bit int values "a" and "b" to 64-bit ones
movsx rsi, esi
movsx rdx, edx
lea rax, [rdi+rsi*4]
; RAX=RDI+RSI*4=address of array+a*4
movzx eax, BYTE PTR [rax+rdx]
; AL=load byte at address RAX+RDX=address of array+a*4+b
ret
get_by_coordinates2:
lea eax, [rdx+rsi*4]
; RAX=RDX+RSI*4=b+a*4
cdqe
movzx eax, BYTE PTR [rdi+rax]
; AL=load byte at address RDI+RAX=address of array+b+a*4
ret
get_by_coordinates3:
sal esi, 2
; ESI=a<<2=a*4
; sign-extend input 32-bit int values "a*4" and "b" to 64-bit ones
movsx rdx, edx
movsx rsi, esi
add rdi, rsi
; RDI=RDI+RSI=address of array+a*4
movzx eax, BYTE PTR [rdi+rdx]
; AL=load byte at address RDI+RDX=address of array+a*4+b
ret三者汇编很接近并且计算的下标是一样的
多维数组的情况也差不多,例如三维
#include <stdio.h>
int a[10][20][30];
void insert(int x, int y, int z, int value)
{
a[x][y][z]=value;
};msvs x86
_DATA SEGMENT
COMM _a:DWORD:01770H
_DATA ENDS
PUBLIC _insert
_TEXT SEGMENT
_x$ = 8 ; size = 4
_y$=12 ; size = 4
_z$=16 ; size = 4
_value$ = 20 ; size = 4
_insert PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _x$[ebp]
imul eax, 2400 ; eax=600*4*x
mov ecx, DWORD PTR _y$[ebp]
imul ecx, 120 ; ecx=30*4*y
lea edx, DWORD PTR _a[eax+ecx]; edx=a + 600*4*x + 30*4*y
mov eax, DWORD PTR _z$[ebp]
mov ecx, DWORD PTR _value$[ebp]
mov DWORD PTR [edx+eax*4], ecx; *(edx+z*4)=value
pop ebp
ret 0
_insert ENDP
_TEXT ENDS数组元素地址=600×4x + 30×4y + 4z。32位系统里int类型是32位(4字节)数据,所以要每项都要乘以4。
gcc
public insert
insert proc near
x = dword ptr 8
y = dword ptr 0Ch
z = dword ptr 10h
value = dword ptr 14h
push ebp
mov ebp, esp
push ebx
mov ebx, [ebp+x];ebx=x
mov eax, [ebp+y];eax=y
mov ecx, [ebp+z];ecx=z
lea edx, [eax+eax] ; edx=y*2
mov eax, edx ; eax=y*2
shl eax, 4 ; eax=(y*2)<<4 = y*2*16 = y*32
sub eax, edx ; eax=y*32 - y*2=y*30
imul edx, ebx, 600 ; edx=x*600
add eax, edx ; eax=eax+edx=y*30 + x*600
lea edx, [eax+ecx] ; edx=y*30 + x*600 + z
mov eax, [ebp+value]
mov dword ptr ds:a[edx*4], eax ; *(a+edx*4)=value
pop ebx
pop ebp
retn
insert endp- gcc在计算30y进行了优化;(y + y) << 4 − (y + y) = (2 y)<< 4 − 2 y = 2×16y − 2 y = 32 y − 2 y = 30 y
计算机的显示屏幕是一个2D显示空间,但是显存却是一个一维线性数组。
二维字符串数组的封装格式
#include <stdio.h>
#include <assert.h>
const char month2[12][10]=
{
{ 'J','a','n','u','a','r','y', 0, 0, 0 },
{ 'F','e','b','r','u','a','r','y', 0, 0 },
{ 'M','a','r','c','h', 0, 0, 0, 0, 0 },
{ 'A','p','r','i','l', 0, 0, 0, 0, 0 },
{ 'M','a','y', 0, 0, 0, 0, 0, 0, 0 },
{ 'J','u','n','e', 0, 0, 0, 0, 0, 0 },
{ 'J','u','l','y', 0, 0, 0, 0, 0, 0 },
{ 'A','u','g','u','s','t', 0, 0, 0, 0 },
{ 'S','e','p','t','e','m','b','e','r', 0 },
{ 'O','c','t','o','b','e','r', 0, 0, 0 },
{ 'N','o','v','e','m','b','e','r', 0, 0 },
{ 'D','e','c','e','m','b','e','r', 0, 0 }
};
// in 0..11 range
const char* get_month2 (int month)
{
return &month2[month][0];
};Optimizing msvs
month2 DB 04aH
DB 061H
DB 06eH
DB 075H
DB 061H
DB 072H
DB 079H
DB 00H
DB 00H
DB 00H
...
get_month2 PROC
; sign-extend input argument and promote to 64-bit value
movsxd rax, ecx
lea rcx, QWORD PTR [rax+rax*4]
; RCX=month+month*4=month*5
lea rax, OFFSET FLAT:month2
; RAX=pointer to table
lea rax, QWORD PTR [rax+rcx*2]
; RAX=pointer to table + RCX*2=pointer to table + month*5*2=pointer to table + month*10
ret 0
get_month2 ENDP-
上述程序完全不访问内存。整个函数的功能,只是计算月份名称字符串的首字母指针pointer_to_the_table+month*10。它使用单条LEA指令,替代了多条MUL和MOV指令。
-
上述数组的每个字符串都占用10字节空间。最长的字符串由“September”和内容为零的字节构成,其余的字符串使用零字节对齐,所以每个字符串都占用10个字节。如此一来,计算字符串首地址的方式变得简单,整个函数的效率也会有所提高。
Optimizing gcc
movsx rdi, edi
lea rax, [rdi+rdi*4]
lea rax, month2[rax+rax]
ret直接使用LEA指令进行乘以10的计算
Not Optimizing GCC
get_month2:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
movsx rdx, eax
; RDX = sign-extended input value
mov rax, rdx
; RAX = month
sal rax, 2
; RAX = month<<2 = month*4
add rax, rdx
; RAX = RAX+RDX = month*4+month = month*5
add rax, rax
; RAX = RAX*2 = month*5*2 = month*10
add rax, OFFSET FLAT:month2
; RAX = month*10 + pointer to the table
pop rbp
ret不开启优化编译,GCC的乘法运算方式不同
Not Optimizing MSVS
month$ = 8
get_month2 PROC
mov DWORD PTR [rsp+8], ecx
movsxd rax, DWORD PTR month$[rsp]
; RAX = sign-extended input value into 64-bit one
imul rax, rax, 10
; RAX = RAX*10
lea rcx, OFFSET FLAT:month2
; RCX = pointer to the table
add rcx, rax
; RCX = RCX+RAX = pointer to the table+month*10
mov rax, rcx
; RAX = pointer to the table+month*10
mov ecx, 1
; RCX = 1
imul rcx, rcx, 0
; RCX = 1*0 = 0
add rax, rcx
; RAX = pointer to the table+month*10 + 0 = pointer to the table+month*10
ret 0
get_month2 ENDP- msvs不开启优化,会直接使用imul指令,然而为什么RCX要乘以0?作者说这是MSVS的怪癖代码,希望我们从编程人员的角度来理解程序的源代码
Problem
; 函数开始
?s@@YAXPAN00@Z PROC; s, COMDAT
; 将参数加载到寄存器中
mov eax, DWORD PTR _b$[esp-4] ; eax = 结束地址 - 4 (实际是_b的地址)
mov ecx, DWORD PTR _a$[esp-4] ; ecx = 起始地址 - 4(a的地址)
mov edx, DWORD PTR _c$[esp-4] ; edx = 结果存放地址 - 4(c的地址)
; 保存寄存器edi和esi,用于循环,因为此后edi和esi作为计数器,
push esi
push edi
; 计算数组长度,两次减法实质上得到的是_b - _a的值,即元素个数,但这里是用字节数表示的
sub ecx, eax ; ecx = 起始地址与结束地址之间的距离(字节数)
sub edx, eax ; edx同样调整,确保结果存回原区间
; 设置外层循环次数为200次(每次处理两个浮点数,合计处理400个浮点数)
mov edi, 200 ; 000000c8H;edi=i
$LL6@s: ; 外层循环开始
push 100 ; 00000064H ; 内层循环计数器,每次处理100对浮点数
pop esi;esi=100,作为计数器
$LL3@s: ; 内层循环开始
fld QWORD PTR [ecx+eax] ; 将当前地址的浮点数推入FPU堆栈
fadd QWORD PTR [eax] ; 将源地址的浮点数与栈顶的浮点数相加
fstp QWORD PTR [edx+eax] ; 将结果从堆栈弹出并存回目的地址
add eax, 8 ; eax指针向前移动8字节,指向下一个浮点数
dec esi ; 内层循环计数器递减
jne SHORT $LL3@s ; 如果未达到内层循环次数,则跳转继续内层循环
dec edi ; 外层循环计数器递减
jne SHORT $LL6@s ; 如果未达到外层循环次数,则跳转继续外层循环
; 恢复保存的寄存器,并清理栈
pop edi
pop esi
ret 0 ; 函数返回,不带返回值
?s@@YAXPAN00@Z ENDP ; s 函数结束#define M 100
#define N 200
void s(double *a, double *b, double *c)
{
for(int i=0;i<N;i++)
for(int j=0;j<M;j++)
*(c+i*M+j)=*(a+i*M+j) + *(b+i*M+j);
};; 函数开始,标准的函数框架建立
?m@@YAXPAN00@Z PROC; m, COMDAT
push ebp
mov ebp, esp
push ecx ; 保存ecx
push ecx ; 这里重复push ecx可能是为了对齐栈或者保留空间(MSVS的怪癖代码)
mov edx, DWORD PTR _a$[ebp] ; edx = _a$ (起始地址)
push ebx ; 保存ebx
mov ebx, DWORD PTR _c$[ebp] ; ebx = _c$ (目标地址或另一个起始地址)
push esi ; 保存esi
mov esi, DWORD PTR _b$[ebp] ; esi = _b$ (可能的结束地址或偏移量)
; 计算数组长度或偏移
sub edx, esi ; 计算长度或偏移1;edx=edx-esi=ptr(a-b)
push edi ; 保存edi
sub esi, ebx ; 计算长度或偏移2,注意这里的操作似乎与预期逻辑不符,需结合具体算法理解
;esi=esi-ebx=ptr(b-c)
; 初始化循环计数器
mov DWORD PTR tv315[ebp], 100 ; 外层循环计数器设为100;tv315=100
$LL9@m: ; 外层循环开始
mov eax, ebx ; eax = ebx=c,可能用于地址计算
mov DWORD PTR tv291[ebp], 300 ; 内层循环计数器设为300;tv291=300
$LL6@m: ; 内层循环开始
fldz ; 加载0.0到FPU堆栈,准备累加
lea ecx, DWORD PTR [esi+eax] ; 计算当前处理元素的地址;ecx=b
fstp QWORD PTR [eax] ; 将0.0存入eax指向的位置,清0,此时eax指向c;*c=0位于第二层循环,eax作为循环的指针
mov edi, 200 ; edi作为计数器;edi=200
$LL3@m: ; 第三层循环开始
dec edi ; 循环计数器递减
fld QWORD PTR [ecx+edx] ; 从当前地址加上之前计算的偏移处取元素,推入FPU栈;ecx+edx=b+a-b=a
fmul QWORD PTR [ecx] ; 将栈顶元素与ecx地址处的元素相乘 *a=*ax*b+c
fadd QWORD PTR [eax] ; 将乘积与eax地址处的元素相加,并将结果放回eax地址,c
fstp QWORD PTR [eax] ; 弹出FPU栈顶元素(已无用);这里的运算与edi无关
jne SHORT $LL3@m ; 若edi非零,继续内层循环
add eax, 8 ; eax指向下一个元素
dec DWORD PTR tv291[ebp] ; 内层循环计数器递减
jne SHORT $LL6@m ; 若内层计数器非零,继续内层循环
add ebx, 800 ; ebx增加800,可能用于处理下一批数据
dec DWORD PTR tv315[ebp] ; 外层循环计数器递减
jne SHORT $LL9@m ; 若外层计数器非零,继续外层循环
; 清理并返回
pop edi
pop esi
pop ebx
leave ; 恢复ebp和esp
ret 0 ; 函数返回
?m@@YAXPAN00@Z ENDP ; m函数结束for tv315 in range(100,-1,-1):
for tv291 in range(300,-1,-1):
*(c+tv315*100+tv291)=0
for edi in range(200,-1,-1):
*(c+tv315*100+tv291)+=*(a+tv315*100+tv291)* *(b+tv315*100+tv291)_array$ = 8
_x$ = 12
_y$ = 16
_f PROC
mov eax, DWORD PTR _x$[esp-4];eax=x;
mov edx, DWORD PTR _y$[esp-4];edx=y;
mov ecx, eax;ecx=x;
shl ecx, 4;x*2^4;
sub ecx, eax;ecx=15x
lea eax, DWORD PTR [edx+ecx*8];eax=y+120x
mov ecx, DWORD PTR _array$[esp-4];ecx=_array
fld QWORD PTR [ecx+eax*8];显然是8位浮点数,double类型
ret 0;返回的是_array[y+120x]
_f ENDPdouble f(double array[50][120], int x, int y)
{
return array[x][y];
};//理论上50是看不出来的,只能反汇编成一维的数组_array[y+120x]_array$ = 8
_x$ = 12
_y$ = 16
_z$ = 20
_f PROC
mov eax, DWORD PTR _x$[esp-4];eax=x
mov edx, DWORD PTR _y$[esp-4];edx=y
mov ecx, eax;ecx=x
shl ecx, 4;ecx=x*16
sub ecx, eax;ecx=15x
lea eax, DWORD PTR [edx+ecx*4];eax=y+60x
mov ecx, DWORD PTR _array$[esp-4];ecx=ptr(array)
lea eax, DWORD PTR [eax+eax*4];eax=5*(y+60x)
shl eax, 4;eax=80*(y+60x)
add eax, DWORD PTR _z$[esp-4];eax=80y+4800x+z
mov eax, DWORD PTR [ecx+eax*4];eax=array[80y+4800x+z];array为int类型
ret 0
_f ENDP显然是三维数组int array[][60][80];return array[x][y][z];
*5.(太难了)
; 初始化段定义了一个名为_tbl的数据段,大小为64字节,用于存放DWORD(双字)类型的数据
COMM _tbl:DWORD:064H
; 定义本地变量tv759,初始化值为-4,占用4字节
tv759 = -4 ;size= 4
_main PROC
; 保存调用者保存的寄存器
push ecx
push ebx
push ebp
push esi
; 初始化寄存器
xor edx, edx ; EDX = 0
push edi ; 保存EDI
xor esi, esi ; ESI = 0
xor edi, edi ; EDI = 0
xor ebx, ebx ; EBX = 0
xor ebp, ebp ; EBP = 0
; 将EDX(当前为0)的值存入局部变量tv759的内存位置,偏移esp+20
mov DWORD PTR tv759[esp+20], edx;t=0
; 设置EAX为_tbl的地址偏移4字节,即指向_tbl的第一个有效元素
mov eax, OFFSET _tbl+4;eax=tbl[1]
; 对齐指令,确保下一条标签正确对齐
npad 8
$LL6@main:
; 计算ECX = EDX * 2,用于后续赋值
lea ecx, DWORD PTR [edx+edx];ecx=2*edx
; 将ECX的值放入当前_EAX指向的位置+4,即初始化tbl的第二个DWORD
mov DWORD PTR [eax+4], ecx;tbl[i+1]=2*edx
; 从堆栈中读取tv759的值并增加3,然后存回tv759的位置
mov ecx, DWORD PTR tv759[esp+20];ecx=t;
add DWORD PTR tv759[esp+20], 3;t+=3;
; 将更新后的tv759值放入当前_EAX指向的位置+8
mov DWORD PTR [eax+8], ecx;ecx[i+2]=t
; 计算ECX = EDX * 4,并存入当前_EAX指向的位置+12
lea ecx, DWORD PTR [edx*4]
mov DWORD PTR [eax+12], ecx
; 计算ECX = EDX * 8,并存入当前_EAX指向的位置
lea ecx, DWORD PTR [edx*8]
mov DWORD PTR [eax], edx
; 初始化表的其他部分,使用固定的值
mov DWORD PTR [eax+16], ebp ; ebp的当前值(0)
mov DWORD PTR [eax+20], ebx ; ebx的当前值(0)
mov DWORD PTR [eax+24], edi ; edi的当前值(0)
mov DWORD PTR [eax+32], esi ; esi的当前值(0)
; 在当前_EAX指针前一个DWORD的位置置0
mov DWORD PTR [eax-4], 0
; 将ECX(即EDX*8)存入当前_EAX指向的位置+28
mov DWORD PTR [eax+28], ecx
; 更新_EAX指针,前进到下一个要初始化的表项
add eax, 40
; 增加循环计数器
inc edx
; 其他循环内增量,看似与某种模式或算法相关
add ebp, 5
add ebx, 6
add edi, 7
add esi, 9
; 检查是否已处理完整个表
cmp eax, OFFSET _tbl+404;400/4=100个int值
jl SHORT $LL6@main ; 若未处理完,跳转回循环开始处继续
; 循环结束,恢复之前保存的寄存器
pop edi
pop esi
pop ebp
; 函数返回值清零
xor eax, eax
; 恢复EBX和ECX,准备返回
pop ebx
pop ecx
; 函数返回,不带参数
ret 0
_main ENDP这段代码已经面目全非了,感觉真的很难看懂,
int tbl[10][10];
int main()
{
int x, y;
for (x=0; x<10; x++)
for (y=0; y<10; y++)
tbl[x][y]=x*y;
};柯佬‘sTips:遇到这种很难看懂的汇编,如果给的是二进制文件,能运行的直接运行完dump,不能运行的把片段抠下来,或者照着汇编写一遍,然后跑一遍进行猜测,搞逆向首先有大胆的猜测和想象
Chap19 位运算
有很多程序都把输入参数的某些比特位当作标识位处理。
特定位
x86
HANDLE fh;
fh=CreateFile ("file", GENERIC_WRITE | GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_ALWAYS ,FILE_ATTRIBUTE_NORMAL, NULL);msvs 2010编译后
push 0 ;NULL
push 128 ; 00000080H
push 4 ;OPEN_ALWAYS
push 0 ;NULL
push 1 ;FILE_SHARE_READ
push -1073741824 ; c0000000H
push OFFSET $SG78813 ;ptr(file)
call DWORD PTR __imp__CreateFileA@28
mov DWORD PTR _fh$[ebp], eax库文件WinNT.h对相关位域进行了定义
#define GENERIC_READ (0x80000000L)
#define GENERIC_WRITE (0x40000000L)
#define GENERIC_EXECUTE (0x20000000L)
#define GENERIC_ALL (0x10000000L)在API声明里,CreateFile()函数的第二个参数为GENERIC_WRITE|GENERIC_READ即0x0x80000000 | 0x40000000 = 0xC0000000,CreateFile()函数如何检测标志位呢
.text:7C83D429 test byte ptr [ebp+dwDesiredAccess+3], 40h
.text:7C83D42 Dmov [ebp+var_8], 1
.text:7C83D434 jz short loc_7C83D417
.text:7C83D436 jmp loc_7C810817byte ptr [ebp+dwDesiredAccess+3],即0xC0000000的头一个字节(这里是小端表示),实际上就是0xC0进行与运算
TEST与AND指令的唯一区别是前者不保存运算结果
即,上述可执行的程序源代码逻辑是:
if ((dwDesiredAccess&0x40000000) == 0) goto loc_7C83D417从而达到了检测标志位的效果
看看linux的
用gcc 4.4.1编译
#include <stdio.h>
#include <fcntl.h>
void main()
{
int handle;
handle=open ("file", O_RDWR | O_CREAT);
}; public main
main proc near
var_20 = dword ptr -20h
var_1C = dword ptr -1Ch
var_4 = dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 20h
mov [esp+20h+var_1C], 42h
mov [esp+20h+var_20], offset aFile ; "file"
call _open
mov [esp+20h+var_4], eax
leave
retn
main endp在libc.so.6里,open()函数调用的是syscall_sys_open
.text:000BE69B mov edx, [esp+4+mode] ; mode
.text:000BE69F mov ecx, [esp+4+flags] ; flags
.text:000BE6A3 mov ebx, [esp+4+filename] ; filename
.text:000BE6A7 mov eax, 5
.text:000BE6AC int 80h ; LINUX - sys_open在执行open()函数时,linux内核会检测某些标识位
在Linux 2.6中,当程序通过syscall调用 sys_open的时候,它调用的函数实际上是内核函数 do_sys_open()。在执行函数do_sys_open()的时候,系统又会调用do_filp_open() 函数。可以在Linux内核源代码里的fs/namei.c里找到这部分内容。
LINUX中编译器不仅会使用栈来传递参数,它还会使用寄存器传递部分参数。编译器最常采用的函数调用约定是fastcall(参见6.4.3节)。这个规范优先使用寄存器来传递参数。这使得CPU不必每次都要访问内存里的数据栈,大大提升了程序的运行效率。此外,我们可以通过GCC的regparm选项[1],设置传递参数的寄存器数量。
在Linux 2.6内核的编译选项中,设定了寄存器选项“-mregparm=3”
这个选项决定,编译器首先通过EAX,EDX和ECX寄存器传递函数所需的头三个参数,再通过栈传递其余的参数,如果参数的总数不足3个,只会用到部分寄存器
在Ubuntu里下载Linux Kernel 2.6.31,并用“make vmlinux”指令编译,然后使用IDA打开程序,寻找函数do_filp_open()
do_filp_open proc near
......
push ebp
mov ebp, esp
push edi
push esi
push ebx
mov ebx, ecx
add ebx, 1
sub esp, 98h
mov esi, [ebp+arg_4] ; acc_mode (5th arg)
test bl, 3
mov [ebp+var_80], eax ; dfd (1th arg)
mov [ebp+var_7C], edx ; pathname (2th arg)
mov [ebp+var_78], ecx ; open_flag (3th arg)
jnz short loc_C01EF684
mov ebx, ecx ; ebx <- open_flagloc_C01EF6B4: ; CODE XREF: do_filp_open+4F
test bl, 40h ; O_CREAT
jnz loc_C01EF810
mov edi, ebx
shr edi, 11h
xor edi, 1
and edi, 1
test ebx, 10000h
jz short loc_C01EF6D3
or edi, 240h,实际上是汇编宏O_CREAT的值.这里的test指令检查open_flag里是否存在0x40的标志位,如果这个位是1,就会触发下一条JNZ指令
清除位
#include <stdio.h>
#define IS_SET(flag, bit) ((flag) & (bit))
#define SET_BIT(var, bit) ((var) |= (bit))
#define REMOVE_BIT(var, bit) ((var) &= ~(bit))
int f(int a)
{
int rt=a;
SET_BIT (rt, 0x4000);
REMOVE_BIT (rt, 0x200);
return rt;
};
int main()
{
f(0x12340678);
};Non-optimizing MSVS
_rt$ = -4 ; size = 4
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
push ecx
mov eax, DWORD PTR _a$[ebp]
mov DWORD PTR _rt$[ebp], eax
mov ecx, DWORD PTR _rt$[ebp]
or ecx, 16384 ; 00004000H;set bit
mov DWORD PTR _rt$[ebp], ecx
mov edx, DWORD PTR _rt$[ebp]
and edx, -513 ; fffffdffH;remove bit
mov DWORD PTR _rt$[ebp], edx
mov eax, DWORD PTR _rt$[ebp]
mov esp, ebp
pop ebp
ret 0
_f ENDP#define IS_SET(flag, bit) ((flag) & (bit)) #define SET_BIT(var, bit) ((var) |= (bit)) #define REMOVE_BIT(var, bit) ((var) &= ~(bit))
以上为核心
在汇编中,OR指令是逐位进行或运算的指令,用来将指定位置置1
AND指令的作用是重置bit位,如果立即数的某个bit位为1,AND指令将会保留寄存器的这个bit位,否则置0
Optimizing MSVS
_a$ = 8 ; size = 4
_f PROC
mov eax, DWORD PTR _a$[esp-4]
and eax, -513 ; fffffdffH
or eax, 16384 ; 00004000H
ret 0
_f ENDP这里互换了顺序,其实没影响,因为对位操作是针对不同位的
Optimizing GCC
public f
f proc near
arg_0 = dword ptr 8
push ebp
mov ebp, esp
mov eax, [ebp+arg_0]
pop ebp
or ah, 40h
and ah, 0FDh
retn
f endp这里的第一个参数原本就在eax里面,函数序言和函数尾声其实可以省略
位移
<<与>>是位移运算符
对应的x86指令集为SHL和SHR
位移指令可用来对特定位进行取值或隔离,用途十分广泛。
在FPU上设置特定位

可以在不使用FPU指令的前提变更S符号位
#include <stdio.h>
float my_abs (float i)
{
unsigned int tmp=(*(unsigned int*)&i) & 0x7FFFFFFF;
return *(float*)&tmp;
};
float set_sign (float i)
{
unsigned int tmp=(*(unsigned int*)&i) | 0x80000000;
return *(float*)&tmp;
};
float negate (float i)
{
unsigned int tmp=(*(unsigned int*)&i) ^ 0x80000000;
return *(float*)&tmp;
};
int main()
{
printf ("my_abs():\n");
printf ("%f\n", my_abs (123.456));
printf ("%f\n", my_abs (-456.123));
printf ("set_sign():\n");
printf ("%f\n", set_sign (123.456));
printf ("%f\n", set_sign (-456.123));
printf ("negate():\n");
printf ("%f\n", negate (123.456));
printf ("%f\n", negate (-456.123));
};用位操作C/C++指令之后,我们不必在CPU和FPU的寄存器之间传递数据、再进行数学运算了。本节列举了三个位操作函数:清除MSB符号位的my_abs()函数、设置符号位的set_sign()函数及求负函数negate()。
x86
Optimizing MSVS
_tmp$ = 8
_i$ = 8
_my_abs PROC
and DWORD PTR _i$[esp-4], 2147483647 ; 7fffffffH
fld DWORD PTR _tmp$[esp-4]
ret 0
_my_abs ENDP;set S=0
_tmp$ = 8
_i$ = 8
_set_sign PROC
or DWORD PTR _i$[esp-4], -2147483648 ; 80000000H
fld DWORD PTR _tmp$[esp-4]
ret 0
_set_sign ENDP;set S=1
_tmp$ = 8
_i$ = 8
_negate PROC
xor DWORD PTR _i$[esp-4], -2147483648 ; 80000000H
fld DWORD PTR _tmp$[esp-4]
ret 0
_negate ENDP函数从栈中提取一个浮点类型的数据,但是把它当作整数类型数据进行处理。
AND和OR设置相应的比特位,而XOR用来设置相反的符号位。
因为要把浮点数还给FPU,所以最后把修改后的处理结果保存到ST0寄存器。
x64
optimizing msvs
tmp$ = 8
i$ = 8
my_abs PROC
movss DWORD PTR [rsp+8], xmm0
mov eax, DWORD PTR i$[rsp]
btr eax, 31
mov DWORD PTR tmp$[rsp], eax
movss xmm0, DWORD PTR tmp$[rsp]
ret 0
my_abs ENDP
_TEXT ENDS
tmp$ = 8
i$ = 8
set_sign PROC
movss DWORD PTR [rsp+8], xmm0
mov eax, DWORD PTR i$[rsp]
bts eax, 31
mov DWORD PTR tmp$[rsp], eax
movss xmm0, DWORD PTR tmp$[rsp]
ret 0
set_sign ENDP
tmp$ = 8
i$ = 8
negate PROC
movss DWORD PTR [rsp+8], xmm0
mov eax, DWORD PTR i$[rsp]
btc eax, 31
mov DWORD PTR tmp$[rsp], eax
movss xmm0, DWORD PTR tmp$[rsp]
ret 0
negate END-
BTR (Bit Test and Reset):
- 功能:测试并复位(清零)指定位置的位。
- 语法:
BTR destination, source - 操作:首先将 destination 操作数的 source 指定的位值存储在 CF(Carry Flag)标志中,然后将该位复位(即清零)。
- 例子:
BTR EAX, 5 ; 测试 EAX 寄存器中第 5 位的值,将其存储在 CF 中,然后清零这个位
-
BTS (Bit Test and Set):
- 功能:测试并设置(置位)指定位置的位。
- 语法:
BTS destination, source - 操作:首先将 destination 操作数的 source 指定的位值存储在 CF 标志中,然后将该位置位(即设为 1)。
- 例子:
BTS EAX, 5 ; 测试 EAX 寄存器中第 5 位的值,将其存储在 CF 中,然后将这位设为 1
-
BTC (Bit Test and Complement):
-
功能:测试并取反(翻转)指定位置的位。
-
语法:
BTC destination, source -
操作:首先将 destination 操作数的 source 指定的位值存储在 CF 标志中,然后将该位取反(如果是 1 则变为 0,如果是 0 则变为 1)。
-
例子:
BTC EAX, 5 ; 测试 EAX 寄存器中第 5 位的值,将其存储在 CF 中,然后将这位置位翻转
-
-
这些指令在进行位操作时会修改 CF(进位标志)以反映被测试的位值,可以用于实现复杂的位操作和逻辑判断。
-
movss用于在 SSE(Streaming SIMD Extensions)寄存器或内存之间传输单精度浮点数。它的全称是 “Move Scalar Single-Precision Floating-Point Value”。 -
输入值会
经XMM0寄存器存储到局部数据栈,然后通过BTR、BTS、BTC等指令进行处理。这些指令用于重置(BTR)、置位(BTS)和翻转(BTC)特定比特位。如果从0开始数的话,浮点数的第31位才是MSB。 -
最终,运算结果被复制到XMM0寄存器。在Win64系统中,浮点型返回值要保存在这个寄存器里。
位校验
介绍一个测算输入变量的2进制数里有多少个1的函数。这种函数叫作“population count/点数”函数。在支持SSE4的x86 CPU的指令集里,甚至有直接对应的POPCNT指令。
#include <stdio.h>
#define IS_SET(flag, bit) ((flag) & (bit))
int f(unsigned int a)
{
int i;
int rt=0;
for (i=0; i<32; i++)
if (IS_SET (a, 1<<i))
rt++;
return rt;
};
int main()
{
f(0x12345678); // test
};1<<i会逐一遍历32位数字的每一位,同时使其他位置零,从而计算二进制的1
这段程序里,1<<i可能产生的值有:
| C/C++表达式 | 2的指数 | 十进制数 | 十六进制数 |
|---|---|---|---|
| 1<<0 | 20 | 1 | 1 |
| 1<<1 | 21 | 2 | 2 |
| 1<<2 | 22 | 4 | 4 |
| 1<<3 | 23 | 8 | 8 |
| 1<<4 | 24 | 16 | 0x10 |
| 1<<5 | 25 | 32 | 0x20 |
| 1<<6 | 26 | 64 | 0x40 |
| 1<<7 | 27 | 128 | 0x80 |
| 1<<8 | 28 | 256 | 0x100 |
| 1<<9 | 29 | 512 | 0x200 |
| 1<<10 | 210 | 1024 | 0x400 |
| 1<<11 | 211 | 2048 | 0x800 |
| 1<<12 | 212 | 4096 | 0x1000 |
| 1<<13 | 213 | 8192 | 0x2000 |
| 1<<14 | 214 | 16384 | 0x4000 |
| 1<<15 | 215 | 32768 | 0x8000 |
| 1<<16 | 216 | 65536 | 0x10000 |
| 1<<17 | 217 | 131072 | 0x20000 |
| 1<<18 | 218 | 262144 | 0x40000 |
| 1<<19 | 219 | 524288 | 0x80000 |
| 1<<20 | 220 | 1048576 | 0x100000 |
| 1<<21 | 221 | 2097152 | 0x200000 |
| 1<<22 | 222 | 4194304 | 0x400000 |
| 1<<23 | 223 | 8388608 | 0x800000 |
| 1<<24 | 224 | 16777216 | 0x1000000 |
| 1<<25 | 225 | 33554432 | 0x2000000 |
| 1<<26 | 226 | 67108864 | 0x4000000 |
| 1<<27 | 227 | 134217728 | 0x8000000 |
| 1<<28 | 228 | 268435456 | 0x10000000 |
| 1<<29 | 229 | 536870912 | 0x20000000 |
| 1<<30 | 230 | 1073741824 | 0x40000000 |
| 1<<31 | 231 | 2147483648 | 0x80000000 |
逆向工程的实际工作中经常出现这些常数(bit mask)。逆向工程人员应当常备这个表格。背下十六进制数并不太困难。
x86 msvs nasm
_rt$ = -8 ;size=4
_i$ =-4 ;size=4
_a$ =8 ;size=4
_f PROC
push ebp
mov ebp, esp
sub esp, 8
mov WORD PTR _rt$[ebp], 0
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN4@f
$LN3@f:
mov ax, DWORD PTR _i$[ebp] ; 递增
add x, 1
mov WORD PTR _i$[ebp], eax
$LN4@f:
cmp DWORD PTR _i$[ebp], 32 ; 00000020H
jge SHORT $LN2@f ; 循环结束?
mov edx, 1
mov ecx, DWORD PTR _i$[ebp]
shl edx, cl ; EDX=EDX<<CL
and edx, DWORD PTR _a$[ebp]
je SHORT $LN1@f ; result of AND instruction was 0?
; then skip next instructions
mov eax, DWORD PTR _rt$[ebp] ; no, not zero
add eax, 1 ; increment rt
mov DWORD PTR _rt$[ebp], eax;rt+=1
$LN1@f:
jmp SHORT $LN3@f
$LN2@f:
mov eax, DWORD PTR _rt$[ebp]
mov esp, ebp
pop ebp
ret 0
_f ENDP比较简单,不难看懂,,,
gcc
public f
f proc near
rt = dword ptr -0Ch
i = dword ptr -8
arg_0 = dword ptr 8
push ebp
mov ebp, esp
push ebx
sub esp, 10h
mov [ebp+rt], 0;rt=0
mov [ebp+i], 0;i=0
jmp short loc_80483EF
loc_80483D0:
mov eax, [ebp+i];eax=i
mov edx, 1;edx=1
mov ebx, edx;ebx=edx=1
mov ecx, eax;ecx=i
shl ebx, cl;ebx<<=cl;1<<cl
mov eax, ebx;eax=ebx
and eax, [ebp+arg_0];eax&=arg_0
test eax, eax
jz short loc_80483EB;&=0,no ++l&=1,++
add [ebp+rt], 1;rt+=1
loc_80483EB:
add [ebp+i], 1
loc_80483EF:;main loop
cmp [ebp+i], 1Fh;i ?=31
jle short loc_80483D0;y,continue;no,jmp
mov eax, [ebp+rt];eax=rt
add esp, 10h
pop ebx
pop ebp
retn
f endpx64
#include <stdio.h>
#include <stdint.h>
#define IS_SET(flag, bit) ((flag) & (bit))
int f(uint64_t a)
{
uint64_t i;
int rt=0;
for (i=0; i<64; i++)
if (IS_SET (a, 1ULL<<i))
rt++;
return rt;
};Non-optimizing GCC 4.8.2
f:
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-24], rdi ; a
mov DWORD PTR [rbp-12], 0 ; rt=0
mov QWORD PTR [rbp-8], 0 ; i=0
jmp .L2
.L4:
mov rax, QWORD PTR [rbp-8]
mov rdx, QWORD PTR [rbp-24]
; RAX = i, RDX = a
mov ecx, eax
; ECX = i
shr rdx, cl
; RDX = RDX>>CL = a>>i
mov rax, rdx
; RAX = RDX = a>>i
and eax, 1
; EAX = EAX&1 = (a>>i)&1
test rax, rax
; the last bit is zero?
; skip the next ADD instruction, if it was so.
je .L3
add DWORD PTR [rbp-12], 1 ; rt++
.L3:
add QWORD PTR [rbp-8], 1 ; i++
.L2:
cmp QWORD PTR [rbp-8], 63 ; i< 63?
jbe .L4 ; jump to the loop boday begin, if so
mov eax, DWORD PTR [rbp-12] ; return rt
pop rbp
ret与x86几乎一样
Optimizing GCC
1 f:
2 xor eax, eax ; rt variable will be in EAX register
3 xor ecx, ecx ; i variable will be in ECX register
4 .L3:
5 mov rsi, rdi ; load input value
6 lea edx, [rax+1] ; EDX=EAX+1
7 ; EDX here is a "new version of rt", which will be written into rt variable, if the last bit is 1
8 shr rsi, cl ; RSI=RSI>>CL
9 and esi, 1 ; ESI=ESI&1
10 ; the last bit is 1? If so, write "new version of rt" into EAX
11 cmovne eax, edx
12 add rcx, 1 ; RCX++
13 cmp rcx, 64
14 jne .L3
15 rep ret ; AKA fatret-
先前的程序都是先比较特定位,再
rt++,而这段程序的顺序有所不同,是先递增rt再写入EDX寄存器 -
line 11如果最后的比特位是1,那么程序将使用CMOVNE指令(等同于CMOVNZ)把EDX寄存器(rt的候选值)传递给EAX寄存器(当前的rt值,也是函数的返回值),从而完成rt的更新。 -
迭代64次
-
优点:因为它只含有一个条件转移指令(在循环的尾部),所以这种编译方法独具优势。如果编译的方式过于机械化,那么程序要在递增rt和循环尾部进行两次条件转移。现在的CPU都具有分支预测的功能(请参加本书33.1节)。在性能方面,本例这类程序的效率更高。
-
line 15的指令rep ret相当于MSVS的FATRET,是由ret衍生出来的向优化指令AMD建议:如果RET指令的前一条指令是条件转移指令,那么在函数最后的返回指令最好使用REP RET指令。
optimizing msvs
a$ = 8
f PROC
; RCX = input value
xor eax, eax
mov edx, 1
lea r8d, QWORD PTR [rax+64]
; R8D=64
npad 5;align
$LL4@f:
test rdx, rcx
; there are no such bit in input value?
; skip the next INC instruction then.
je SHORT $LN3@f
inc eax ; rt++
$LN3@f:
rol rdx, 1 ; RDX=RDX<<1
dec r8 ; R8--
jne SHORT $LL4@f
fatret 0
f ENDPROL 和 SHL 是 x86 汇编语言中的两种不同的移位指令,它们虽然都涉及位操作,但功能和效果不同。以下是它们的详细解释:
ROL(Rotate Left)
功能:循环左移位
- 语法:
ROL destination, count - 操作:将目的操作数中的所有位向左移动指定的次数(
count),高位左移后重新进入最低位,这个过程是循环的。 - 效果:不会丢失任何位,原本被移出的高位将会重新进入低位。
- 例子:
ROL EAX, 1 ; 将 EAX 寄存器的值循环左移 1 位,例如:0b1011 -> 0b0111
SHL(Shift Logical Left)
功能:逻辑左移位
- 语法:
SHL destination, count - 操作:将目的操作数的所有位向左移动指定的次数(
count),高位移出后丢弃,低位用 0 填补。 - 效果:在左移过程中高位丢失,低位用0填充。
- 例子:
SHL EAX, 1 ; 将 EAX 寄存器的值左移 1 位,低位用 0 填充,例如:0b1011 -> 0b0110(低位为0)
ROL指令替代了SHL,ROL是rotate left,与SHL在本例中效果一样
R8从64递减为0,循环64次
Promblem
_a$ = 8
_f PROC
mov ecx, DWORD PTR _a$[esp-4];ecx=a
mov eax, ecx;eax=a
mov edx, ecx;edx=a
shl edx, 16 ; 00000010H;edx=a<<16
and eax, 65280 ; 0000ff00H;eax=a&0xff00
or eax, edx;eax|a<<16;eax=a&0xff00|a<<16
mov edx, ecx;edx=ecx=a
and edx, 16711680 ; 00ff0000H;edx=a&0xff0000
shr ecx, 16 ; 00000010H;ecx=a>>16
or edx, ecx;;edx=a&0xff0000|a>>16
shl eax, 8;eax<<8;eax=(a&0xff00|a<<16)<<8
shr edx, 8;;eax>>8;edx=(a&0xff0000|a>>16)>>8
or eax, edx;eax|edx;((a&0xff00|a<<16)<<8)|((a&0xff0000|a>>16)>>8)
ret 0
_f ENDP逆向得到的逻辑是return ((a&0xff00|a<<16)<<8)|((a&0xff0000|a>>16)>>8)
事实上化简结果与源码是等价的,编译器对这一系列操作进行了优化
_a$ = 8 ; size = 4
_f PROC
push esi
mov esi, DWORD PTR _a$[esp];esi=a
xor ecx, ecx;ecx=0
push edi;save edi
lea edx, DWORD PTR [ecx+1];edx=1
xor eax, eax;eax=0
npad 3 ; align next label
;loop0:edx=1;ecx=counter=i=0
$LL3@f:
mov edi, esi;edi=a
shr edi, cl;edi=(a>>cl)&0xff(ecx,low,i的低8位)
add ecx, 4;ecx=i+4
and edi, 15;edi=a>>cl&15
imul edi, edx;edi*edx;edi=(a>>cl)*edx
lea edx, DWORD PTR [edx+edx*4];edx=edx*5
add eax, edi;eax=eax+(a>>cl)*edx
add edx, edx;edx=edx*2=edx*10
cmp ecx, 28;ecx=28?
jle SHORT $LL3@f
pop edi
pop esi
ret 0
_f ENDPfunction f(int a)//这里应该是unsigned int
{
int eax=0;
int temp=1;
for(int i=0;i<=28;i+=4,temp*=10)
{
eax+=((a>>i)&0xf)*j;
}
return eax;
}逆向得到的源码,这是一个把BCD封装的32位二进制值转换为常规格式的10进制的函数
BCD(Binary-Coded Decimal,二进制编码的十进制)表示法是一种表达十进制数字的方法,每个十进制数字(0-9)都用一个固定长度的二进制数表示。
源码如下
#include <stdio.h>
unsigned int f(unsigned int a)
{
int i=0;
int j=1;
unsigned int rt=0;
for (;i<=28; i+=4, j*=10)
rt+=((a>>i)&0xF) * j;
return rt;
};例如34代表0011 0100
请查阅MSDN资料,找到MessageBox()函数使用了哪些标志位。
#include <windows.h>
int main()
{
MessageBox(NULL, "hello, world!", "caption",
MB_TOPMOST | MB_ICONINFORMATION | MB_HELP | MB_YESNOCANCEL);
};_m$ = 8 ; size = 4
_n$ = 12 ; size = 4
_f PROC
; 将 ecx 设置为变量 n 的值;ecx=12
mov ecx, DWORD PTR _n$[esp-4]
; 将 eax 和 edx 清零
xor eax, eax;eax=0
xor edx, edx;edx=0
; 测试 ecx 是否为零,如果为零则跳转到 $LN2@f 位置
test ecx, ecx
je SHORT $LN2@f;loop exit?
; 保存 esi 寄存器原值到栈
push esi
; 将变量 m 的值赋给 esi
mov esi, DWORD PTR _m$[esp];esi=m
$LL3@f:
; 测试 ecx 的最低位(即 cl 的最低位)
test cl, 1
; 如果最低位为 0 则跳转到 $LN1@f 位置
je SHORT $LN1@f
; 如果最低位为 1,则将 esi 加到 eax 中,并考虑进位加到 edx 中
add eax, esi;eax=eax+m
adc edx, 0
$LN1@f:
; 将 esi 左移一位(即乘 2)
add esi, esi;m*2
; 将 ecx 右移一位(即除 2)
shr ecx, 1;n/=2
; 如果 ecx 不为零,则继续循环
jne SHORT $LL3@f
; 恢复被保存的 esi 寄存器值
pop esi
$LN2@f:
; 返回到调用者
ret 0
_f ENDPm=8;
n=12;
function f()
{
int eax=0;
for(;n!=0;n/2,m*2)
{
if((n&1)==1);相当于是(m*(2^3*1)==(m*(2^3)*1))
{
eax+=m;
}
}
return eax;
}逻辑还原了,但是还是没看出来是干嘛的
看源码的功能是把32位数相乘(这个是乘法优化的算法),返回64位的积
#include <stdio.h>
#include <stdint.h>
// source code taken from
//http://www4.wittenberg.edu/academics/mathcomp/shelburne/comp255/notes/binarymultiplication.pdf
uint64_t mult (uint32_t m, uint32_t n)
{
uint64_t p = 0; // initialize product p to 0
while (n != 0) // while multiplier n is not 0
{
if (n & 1) // test LSB of multiplier
p = p + m; // if 1 then add multiplicand m
m = m << 1; // left shift multiplicand
n = n >> 1; // right shift multiplier
}
return p;
}Chap20 线性同余法与伪随机数
线性同余法是生成随机数的最简方法,虽然目前的随机函数都不用了,但是原理简单(只涉及乘法、加法和与运算)
#include <stdint.h>
// constants from the Numerical Recipes book
#define RNG_a 1664525
#define RNG_c 1013904223
static uint32_t rand_state;
void my_srand (uint32_t init)
{
rand_state=init;
}
int my_rand ()
{
rand_state=rand_state*RNG_a;
rand_state=rand_state+RNG_c;
return rand_state & 0x7fff;
}第一个函数用于初始化内部状态,第二个函数生成伪随机数
这里的&可以控制位数
x86
Optimizing msvs
_BSS SEGMENT
_rand_state DD 01H DUP (?)
_BSS ENDS
_init$ = 8
_srand PROC
mov eax, DWORD PTR _init$[esp-4]
mov DWORD PTR _rand_state, eax
ret 0
_srand ENDP
_TEXT SEGMENT
_rand PROC
imul eax, DWORD PTR _rand_state, 1664525
add eax, 1013904223 ; 3c6ef35fH
mov DWORD PTR _rand_state, eax
and eax, 32767 ; 00007fffH
ret 0
_rand ENDP
_TEXT ENDSx64中 mysrand直接使用ecx寄存器获取了所需参数,没有通过栈读取参数
多数随机函数都采用梅森旋转算法(Mersenne twister)。
Chap21 结构体
systemtime
本节是以Win32描述系统时间的SYSTEMTIME结构体(来源WinBase.h)为例的
typedef struct _SYSTEMTIME {
WORD wYear;
WORD wMonth;
WORD wDayOfWeek;
WORD wDay;
WORD wHour;
WORD wMinute;
WORD wSecond;
WORD wMilliseconds;
} SYSTEMTIME, *PSYSTEMTIME;#include <windows.h>
#include <stdio.h>
void main()
{
SYSTEMTIME t;
GetSystemTime (&t);
printf ("%04d-%02d-%02d %02d:%02d:%02d\n",
t.wYear, t.wMonth, t.wDay,
t.wHour, t.wMinute, t.wSecond);
return;
};MSVS 2010(启用/GS选项)
_t$ = -16 ; size = 16
_main PROC
push ebp
mov ebp, esp
sub esp, 16
lea eax, DWORD PTR _t$[ebp]
push eax
call DWORD PTR __imp__GetSystemTime@4
movzx ecx, WORD PTR _t$[ebp+12] ; wSecond
push ecx
movzx edx, WORD PTR _t$[ebp+10] ; wMinute
push edx
movzx eax, WORD PTR _t$[ebp+8] ; wHour
push eax
movzx ecx, WORD PTR _t$[ebp+6] ; wDay
push ecx
movzx edx, WORD PTR _t$[ebp+2] ; wMonth
push edx
movzx eax, WORD PTR _t$[ebp] ; wYear
push eax
push OFFSET $SG78811 ; ’%04d-%02d-%02d %02d:%02d:%02d’, 0aH, 00H
call _printf
add esp, 28
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP-
函数在这个栈中为结构体申请了16字节空间(这个结构体由8个WORD型数据构成),每个
WORD型数据占用2字节传递给函数的是SYSTEMTIME结构体的指针。但是换个角度看,这也是
wYear字段的指针。GetSystemTime()函数首先会在结构体的首地址写入年份信息,然后再把指针调整2个字节并写入月份信息,如此类推写入全部信息。
用onlydbg查看这个结构体在内存中的分布
从t指针开始的位置的内容依次是:
DE 07 0C 00 02 00 09 00 16 00 1D 00 34 00 D4 03这两个空间的每两个字节代表结构体的一个字段,由于采用了小端字节序,所以就同一个WORD型数据而言,低地址在前,高地址在后
| 十六进制数 | 十进制含义 | 字段名 |
|---|---|---|
| 0x07DE | 2014 | wYear |
| 0x000C | 12 | wMonth |
| 0x0002 | 2 | wDayOfWeek |
| 0x0009 | 9 | wDay |
| 0x0016 | 22 | wHour |
| 0x001D | 29 | wMinute |
| 0x0034 | 52 | wSecond |
| 0x03D4 | 980 | wMilliSeconds |
以数组替代结构体
由于结构体中的各个元素,在内存中一次排列,我们可以验证其在内存中的存储状况和数组相同
#include <windows.h>
#include <stdio.h>
void main()
{
WORD array[8];
GetSystemTime (array);
printf ("%04d-%02d-%02d %02d:%02d:%02d\n",
array[0] /* wYear */, array[1] /* wMonth */, array[3] /* wDay */,
array[4] /* wHour */, array[5] /* wMinute */, array[6] /* wSecond */);
return;
};会弹警告,但是仍然能编译
$SG78573 DB '%04d-%02d-%02d %02d:%02d:%02d', 0aH, 00H
_array$ = -16;size=16
_main PROC
Push ebp
mov ebp, esp
sub esp, 16
lea eax, DWORD PTR _array$[ebp]
push eax
call DWORD PTR __imp__GetSystemTime@4
movzx ecx, WORD PTR _array$[ebp+12] ; wSecond
push ecx
movzx edx, WORD PTR _array$[ebp+10] ; wMinute
push edx
movzx eax, WORD PTR _array$[ebp+8] ; wHoure
push eax
movzx ecx, WORD PTR _array$[ebp+6] ; wDay
push ecx
movzx edx, WORD PTR _array$[ebp+2] ; wMonth
push edx
movzx eax, WORD PTR _array$[ebp] ; wYear
push eax
push OFFSET $SG78573
call _printf
add esp, 28
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP即便调整了数据结构,可以发现汇编代码相差无几
仅从汇编指令分析,很难判断出到底源程序使用的是多变量的结构体还是数组。
好在正常人不会做这种别扭的替换。毕竟结构体的可读性、易用性都比数组强,也方便编程人员替换结构体中的字段。
malloc()
在很多情况,都用heap来存储结构体,需要借助malloc函数
#include <windows.h>
#include <stdio.h>
void main()
{
SYSTEMTIME *t;
t=(SYSTEMTIME *)malloc (sizeof (SYSTEMTIME));
GetSystemTime (t);
printf ("%04d-%02d-%02d %02d:%02d:%02d\n",
t->wYear, t->wMonth, t->wDay,
t->wHour, t->wMinute, t->wSecond);
free (t);
return;
};msvs /ox
_main PROC
push esi
push 16
call _malloc;eax=ptr(t)
add esp, 4
mov esi, eax
push esi
call DWORD PTR __imp__GetSystemTime@4;
movzx eax, WORD PTR [esi+12] ; wSecond
movzx ecx, WORD PTR [esi+10] ; wMinute
movzx edx, WORD PTR [esi+8] ; wHour
push eax
movzx eax, WORD PTR [esi+6] ; wDay
push ecx
movzx ecx, WORD PTR [esi+2] ; wMonth
push edx
movzx edx, WORD PTR [esi] ; wYear
push eax
push ecx
push edx
push OFFSET $SG78833
call _printf
push esi
call _free
add esp, 32
xor eax, eax
pop esi
ret 0
_main ENDP- malloc接收的参数16就是
sizeof(systemtime),malloc()函数根据参数指定的大小分配一块空间,并把空间的指针传递给EAX寄存器
UNIX: struct tm
#include <stdio.h>
#include <time.h>
void main()
{
struct tm t;
time_t unix_time;
unix_time=time(NULL);
localtime_r (&unix_time, &t);
printf ("Year: %d\n", t.tm_year+1900);
printf ("Month: %d\n", t.tm_mon);
printf ("Day: %d\n", t.tm_mday);
printf ("Hour: %d\n", t.tm_hour);
printf ("Minutes: %d\n", t.tm_min);
printf ("Seconds: %d\n", t.tm_sec);
};main proc near
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 40h
mov dword ptr [esp], 0 ; first argument for time()
call time
mov [esp+3Ch], eax
lea eax, [esp+3Ch] ; take pointer to what time() returned
lea edx, [esp+10h] ; at ESP+10h struct tm will begin
mov [esp+4], edx ; pass pointer to the structure begin
mov [esp], eax ; pass pointer to result of time()
call localtime_r
mov eax, [esp+24h] ; tm_year
lea edx, [eax+76Ch] ; edx=eax+1900
mov eax, offset format ; "Year: %d\n"
mov [esp+4], edx
mov [esp], eax
call printf
mov edx, [esp+20h] ; tm_mon
mov eax, offset aMonthD ; "Month: %d\n"
mov [esp+4], edx
mov [esp], eax
call printf
mov edx, [esp+1Ch] ; tm_mday
mov eax, offset aDayD ; "Day: %d\n"
mov [esp+4], edx
mov [esp], eax
call printf
mov edx, [esp+18h] ; tm_hour
mov eax, offset aHourD ; "Hour: %d\n"
mov [esp+4], edx
mov [esp], eax
call printf
mov edx, [esp+14h] ; tm_min
mov eax, offset aMinutesD ; "Minutes: %d\n"
mov [esp+4], edx
mov [esp], eax
call printf
mov edx, [esp+10h]
mov eax, offset aSecondsD ; "Seconds: %d\n"
mov [esp+4], edx ; tm_sec
mov [esp], eax
call printf
leave
retn
main endp- 需要注意的是“lea edx, [eax+76Ch]”指令。它给EAX寄存器里的值加上0x76C(1900),而不会修改任何标志位。
与上文类似,可以用WORD数组代替这个结构体,但是我们甚至也可以用字节型数组来代替
#include <stdio.h>
#include <time.h>
void main()
{
struct tm t;
time_t unix_time;
int i, j;
unix_time=time(NULL);
localtime_r (&unix_time, &t);
for (i=0; i<9; i++)
{
for (j=0; j<4; j++)
printf ("0x%02X ", ((unsigned char*)&t)[i*4+j]);
printf ("\n");
};
};只要控制好每个接受的参数的数组的合适位置即可
结构体的字段封装
#include <stdio.h>
struct s
{
char a;
int b;
char c;
int d;
};
void f(struct s s)
{
printf ("a=%d; b=%d; c=%d; d=%d\n", s.a, s.b, s.c, s.d);
};
int main()
{
struct s tmp;
tmp.a=1;
tmp.b=2;
tmp.c=3;
tmp.d=4;
f(tmp);
};msvs 2012 /GS /Ob0
1 _tmp$ = -16
2 _main PROC
3 push ebp
4 mov ebp, esp
5 sub esp, 16
6 mov BYTE PTR _tmp$[ebp], 1 ; set field a
7 mov DWORD PTR _tmp$[ebp+4], 2 ; set field b
8 mov BYTE PTR _tmp$[ebp+8], 3 ; set field c
9 mov DWORD PTR _tmp$[ebp+12], 4 ; set field d
10 sub esp, 16 ; allocate place for temporary structure
11 mov eax, esp
12 mov ecx, DWORD PTR _tmp$[ebp] ; copy our structure to the temporary one
13 mov DWORD PTR [eax], ecx
14 mov edx, DWORD PTR _tmp$[ebp+4]
15 mov DWORD PTR [eax+4], edx
16 mov ecx, DWORD PTR _tmp$[ebp+8]
17 mov DWORD PTR [eax+8], ecx
18 mov edx, DWORD PTR _tmp$[ebp+12]
19 mov DWORD PTR [eax+12], edx
20 call _f
21 add esp, 16
22 xor eax, eax
23 mov esp, ebp
24 pop ebp
25 ret 0
26 _main ENDP
27
28 _s$ = 8 ; size = 16
29 ?f@@YAXUs@@@Z PROC ; f
30 push ebp
31 mov ebp, esp
32 mov eax, DWORD PTR _s$[ebp+12]
33 push eax
34 movsx ecx, BYTE PTR _s$[ebp+8]
35 push ecx
36 mov edx, DWORD PTR _s$[ebp+4]
37 push edx
38 movsx eax, BYTE PTR _s$[ebp]
39 push eax
40 push OFFSET $SG3842
41 call _printf
42 add esp, 20
43 pop ebp
44 ret 0
45 ?f@@YAXUs@@@Z ENDP ; f
46 _TEXT ENDS-
虽然我们在代码里一次性分配了结构体tmp,并依次给它的四个字段赋值,但是可执行程序的指令有些不同:它将结构体的指针复制到临时地址(第10行指令分配的空间里),然后通过临时的中间变量把结构体的四个值赋值给临时结构体(第12~19行的指令),还把指针也复制出来供f()调用。
-
这主要是因为编译器无法判断f()函数是否会修改结构体的内容。借助中间变量,编译器可以保证main()函数里tmp结构体的值不受被调用方函数的影响。
-
另外,这个程序里结构体的字段向4字节边界对齐。也就是说它的char型数据也和int型数据一样占4字节存储空间。这主要是为了方便CPU从内存读取数据,提高读写和缓存的效率。
这样的缺点是浪费存储空间,我们可以启用编译器的/Zp1 (/Zp[n]表示向n个字节的边界对齐)选项。
- 如果某个结构体被多个源文件、目标文件(object files)调用,那么在编译这些程序时,结构封装格式和数据对其规范(/Zp[n])必须完全匹配。
在向被调用方函数传递结构体时(不是传递结构体的指针),传递参数的过程相当于依次传递结构体的各字段。即是说,如果结构体各字段的定义不变,那么f()函数的源代码可改写为:
void f(char a, int b, char c, int d)
{
printf ("a=%d; b=%d; c=%d; d=%d\n", a, b, c, d);
};结构体的嵌套
#include <stdio.h>
struct inner_struct
{
int a;
int b;
};
struct outer_struct
{
char a;
int b;
struct inner_struct c;
char d;
int e;
};
void f(struct outer_struct s)
{
printf ("a=%d; b=%d; c.a=%d; c.b=%d; d=%d; e=%d\n",
s.a, s.b, s.c.a, s.c.b, s.d, s.e);
};
int main()
{
struct outer_struct s;
s.a=1;
s.b=2;
s.c.a=100;
s.c.b=101;
s.d=3;
s.e=4;
f(s);
};MSVC 2010(启用/Ox /Ob0选项)
$SG2802 DB ’a=%d; b=%d; c.a=%d; c.b=%d; d=%d; e=%d’, 0aH, 00H
_TEXT SEGMENT
_s$ = 8
_f PROC
mov eax, DWORD PTR _s$[esp+16]
movsx ecx, BYTE PTR _s$[esp+12]
mov edx, DWORD PTR _s$[esp+8]
push eax
mov eax, DWORD PTR _s$[esp+8]
push ecx
mov ecx, DWORD PTR _s$[esp+8]
push edx
movsx edx, BYTE PTR _s$[esp+8]
push eax
push ecx
push edx
push OFFSET $SG2802 ; ’a=%d; b=%d; c.a=%d; c.b=%d; d=%d; e=%d’
call _printf
add esp, 28
ret 0
_f ENDP
_s$ = -24
_main PROC
sub esp, 24
push ebx
push esi
push edi
mov ecx, 2
sub esp, 24
mov eax, esp
mov BYTE PTR _s$[esp+60], 1;s.a=1
mov ebx, DWORD PTR _s$[esp+60]
mov DWORD PTR [eax], ebx
mov DWORD PTR [eax+4], ecx
lea edx, DWORD PTR [ecx+98]
lea esi, DWORD PTR [ecx+99]
lea edi, DWORD PTR [ecx+2]
mov DWORD PTR [eax+8], edx
mov BYTE PTR _s$[esp+76], 3
mov ecx, DWORD PTR _s$[esp+76]
mov DWORD PTR [eax+12], esi
mov DWORD PTR [eax+16], ecx
mov DWORD PTR [eax+20], edi
call _f
add esp, 24
pop edi
pop esi
xor eax, eax
pop ebx
add esp, 24
ret 0
_main ENDP- 由汇编代码可以看出,内嵌结构体会被编译器展开形成一维结构体
- 内存中的构造如下:
- (outer_struct.a)值为1的字节,其后3字节是随机脏数据。
- (outer_struct.b) 32 位word型数据2。
- (outer_struct.a)32 位word型数据0x64(100)。
- (outer_struct.b)32 位word型数据0x65(101)。
- (outer_struct.d)值为3的字节,以及其后3字节的脏数据。
- (outer_struct.e)32 位word型数据4。
结构体的位操作
以CPUID指令为例。该指令用于获取CPU及其特性信息。
如果在调用指令之前设置EAX寄存器的值为1,那么CPUID指令将会按照下列格式在EAX寄存器里存储CPU的特征信息。

C/C++语言可以精确操作结构体中的位域。这能够帮助程序员大幅度地节省程序的内存消耗。
#include <stdio.h>
#ifdef __GNUC__
static inline void cpuid(int code, int *a, int *b, int *c, int *d) {
asm volatile("cpuid":"=a"(*a),"=b"(*b),"=c"(*c),"=d"(*d):"a"(code));
}
#endif
#ifdef _MSC_VER
#include <intrin.h>
#endif
struct CPUID_1_EAX
{
unsigned int stepping:4;
unsigned int model:4;
unsigned int family_id:4;
unsigned int processor_type:2;
unsigned int reserved1:2;
unsigned int extended_model_id:4;
unsigned int extended_family_id:8;
unsigned int reserved2:4;
};
int main()
{
struct CPUID_1_EAX *tmp;
int b[4];
#ifdef _MSC_VER
__cpuid(b,1);
#endif
#ifdef __GNUC__
cpuid (1, &b[0], &b[1], &b[2], &b[3]);
#endif
tmp=(struct CPUID_1_EAX *)&b[0];
printf ("stepping=%d\n", tmp->stepping);
printf ("model=%d\n", tmp->model);
printf ("family_id=%d\n", tmp->family_id);
printf ("processor_type=%d\n", tmp->processor_type);
printf ("extended_model_id=%d\n", tmp->extended_model_id);
printf ("extended_family_id=%d\n", tmp->extended_family_id);
return 0;
};在CPUID将返回值存储到EAX/EBX/ECX/EDX之后,程序使用数组b[]收集相关信息。然后,我们通过指向结构体CPUID_1_EAX的指针,从数组b[]中获取EAX寄存器里的值。
我们也可以用结构体模拟出浮点数,并且在程序中替代float类型,但是没什么意义,略过
Chap22 Union共用体
伪随机数生成
-
利用union结构可以不用除法就生成介于0~1之间的随机数
可采用共用体类型(union)的数据表示单精度浮点数(float)。创建一个union型变量,然后把它当作float型或uint32_t型数据进行读取。
-
单精度浮点数(float)型数据由符号位、有效数字和指数三部分构成。这种数据结构决定,只要随机填充有效数字位就可以生成随机的单精度数
-
依据有关规范,随机浮点数的指数部分不可以是0。那么我们不妨把指数部分直接设置为01111111(即十进制的1),用随机数字填充有效数字部分,再把符号位设置为零(表示正数)。
-
再把它减去1就可以得到一个标准的随机函数。
#nclude <stdio.h>
#include <stdint.h>
#include <time.h>
// integer PRNG definitions, data and routines:
//constants from the Numerical Recipes book
const uint32_t RNG_a=1664525;
const uint32_t RNG_c=1013904223;
uint32_t RNG_state; // global variable
void my_srand(uint32_t i)
{
RNG_state=i;
};
uint32_t my_rand()
{
RNG_state=RNG_state*RNG_a+RNG_c;
return RNG_state;
};
// FPU PRNG definitions and routines:
union uint32_t_float
{
uint32_t i;
float f;
};
float float_rand()
{
union uint32_t_float tmp;
tmp.i=my_rand() & 0x007fffff | 0x3F800000;
return tmp.f-1;
};
// test
int main()
{
my_srand(time(NULL)); // PRNG initialization
for (int i=0; i<100; i++)
printf ("%f\n", float_rand());
return 0;
};$SG4232 DB '%f', 0aH, 00H
__real@3ff0000000000000 DQ 03ff0000000000000r ;1
tv140 = -4
_tmp$ = -4
?float_rand@@YAMXZ PROC
push ecx
call ?my_rand@@YAIXZ
; EAX=pseudorandom value
and eax, 8388607 ; 007fffffH
or eax, 1065353216 ; 3f800000H
; EAX=pseudorandom value & 0x007fffff | 0x3f800000
; store it into local stack:
mov DWORD PTR _tmp$[esp+4], eax
; reload it as float point number:
fld DWORD PTR _tmp$[esp+4]
; subtract 1.0:
fsub QWORD PTR __real@3ff0000000000000
; store value we got into local stack and reload it:
fstp DWORD PTR tv130[esp+4] ; \ these instructions are redundant
fld DWORD PTR tv130[esp+4] ; /
pop ecx
ret 0
?float_rand@@YAMXZ ENDP
_main PROC
push esi
xor eax, eax
call _time
push eax
call ?my_srand@@YAXI@Z
add esp, 4
mov esi, 100
$LL3@main:
call ?float_rand@@YAMXZ
sub esp, 8
fstp QWORD PTR [esp]
push OFFSET $SG4238
call _printf
add esp, 12
dec esi
jne SHORT $LL3@main
xor eax, eax
pop esi
ret 0
_main ENDP如果使用MSVC 2012编译器进行编译,那么可执行程序则会使用面向FPU的SIMD指令。
计算机器精度
单精度浮点数的“机器精度/machine epsilon”指的是相对误差的上限,即FPU操作的最小值。因此,浮点数的数据位越多,误差越小、精度越高。故而单精度float型数据的最高精度为2−23=1.19e−7,而双精度double型的最高精度为2−52=2.22e−16。
#include <stdio.h>
#include <stdint.h>
union uint_float
{
uint32_t i;
float f;
};
float calculate_machine_epsilon(float start)
{
union uint_float v;
v.f=start;
v.i++;
return v.f-start;
};
void main()
{
printf ("%g\n", calculate_machine_epsilon(1.0));
};上述程序从IEEE 754格式的浮点数中提取小数部分,把这部分当作整数处理并且给它加上1。运算的中间值是“输入值+机器精度”。通过测算输入值(单精度型数值)与中间值的差值来测算具体float型数据的机器精度。
程序使用union型数据结构解析IEEE 754格式的float型浮点数,并利用这种数据结构把float数据的小数部分提取为整数“1”实际上加到浮点数小数部分中去了。当然,这可能造成溢出,可能把最高位的进位加到浮点数的指数部分。
X86 asm
tv130 = 8
_v$ = 8
_start$ = 8
_calculate_machine_epsilon PROC
fld DWORD PTR _start$[esp-4];1.0
fst DWORD PTR _v$[esp-4] ;冗余代码
inc DWORD PTR _v$[esp-4]
fsubr DWORD PTR _v$[esp-4];_v-start
fstp DWORD PTR tv130[esp-4] ;冗余代码
fld DWORD PTR tv130[esp-4] ;冗余代码
ret 0
_calculate_machine_epsilon ENDP- 首先存储地址
- 接着
inc指令把输入值的小数部分当做整数数据处理,小数部分+1,利用FSUBR计算差值,从而得到相对误差
快速平方根计算
快速平方根计算也是利用了浮点数解释为整数的思想
/* Assumes that float is in the IEEE 754 single precision floating point format
* and that int is 32 bits. */
float sqrt_approx(float z)
{
int val_int = *(int*)&z; /* Same bits, but as an int */
/*
* To justify the following code, prove that
*
* ((((val_int / 2^m) - b) / 2) + b) * 2^m = ((val_int - 2^m) / 2) + ((b + 1) / 2) * 2^m)
*
*where
*
*b = exponent bias
* m = number of mantissa bits
*
*
.
*/
val_int -= 1 << 23; /* Subtract 2^m. */
val_int >>= 1; /* Divide by 2. */
val_int += 1 << 29; /* Add ((b + 1) / 2) * 2^m. */
return *(float*)&val_int; /* Interpret again as float */
}- 通过整数表示直接处理原始浮点值的比特。
- 坐标调整指数部分来实现平方根近似。
- 通过右移操作和添加偏移量的方式,提供了一个快速且有效的近似结果。不是很重要
Chap23 函数指针
函数指针和其他指针没有太大区别。它代表的地址为函数代码段的起始地址。
在函数指针(地址)以函数参数的形式传递给另一个函数,继而被用来调用该指针所指向的函数时,这种函数指针的所指向的函数就是“回调函数”/callback function
此类指针主要应用于:
- 标准C函数库里的
qsort()函数和atexit()函数[2]。 - *NIX系统里的信号(Signals)[3]。
- 启动线程的CreateThread()(windows函数)和pthread_create()(POSIX函数)。
- Win32的多种函数,例如EnumChildWindows()[4]。
- Linux内核。例如,Linux以callback的方式调用文件系统的驱动函数:http://lxr.free-electrons.com/source/include/linux/fs.h?v=3.14#L1525。
- GCC插件:https://gcc.gnu.org/onlinedocs/gccint/Plugin-API.html#Plugin-API。
- Linux窗口管理程序定义快捷方式的dwm表。当键盘接收到可匹配的特定键时,对应的快捷方式就通过callback调用相应函数。请参见GitHub(https://github.com/cdown/dwm/ blob/master/config.def.h#L117),callback方法要比大量使用switch()语句的方法更为简单。
其中,qsort()函数是C/C++编译器函数库自带的快速排序函数。无论待排序的数据是何种数据类型,只要编写出比较两个元素的函数,那么就可以用qsort()函数以callback的方式调用比较函数。例如,我们可声明比较函数为:
int (*compare)(const void *, const void *) 1 /* ex3 Sorting ints with qsort */
2
3 #include <stdio.h>
4 #include <stdlib.h>
5
6 int comp(const void * _a, const void * _b)
7 {
8 const int *a=(const int *)_a;
9 const int *b=(const int *)_b;
10
11 if (*a==*b)
12 return 0;
13 else
14 if (*a < *b)
15 return -1;
16 else
17 return 1;
18 }
19
20 int main(int argc, char* argv[])
21 {
22 int numbers[10]={1892,45,200,-98,4087,5,-12345,1087,88,-100000};
23 int i;
24
25 /* Sort the array */
26 qsort(numbers,10,sizeof(int),comp) ;
27 for (i=0;i<9;i++)
28 printf("Number = %d\n",numbers[ i ]) ;
29 return 0;
30 }msvs 2010 asm启用选项/Ox /GS- /MD
__a$ = 8 ; size = 4
__b$ = 12 ; size = 4
_comp PROC
mov eax, DWORD PTR __a$[esp-4]
mov ecx, DWORD PTR __b$[esp-4]
mov eax, DWORD PTR [eax]
mov eax, DWORD PTR [ecx]
cmp eax, ecx
jne SHORT $LN4@comp
xor eax, eax
ret 0
$LN4@comp:
xor edx, edx
cmp eax, ecx
setge dl
lea eax, DWORD PTR [edx+edx-1]
ret 0
_comp ENDP
_numbers$ = -40 ; size = 40
_argc$ = 8 ; size = 4
_argv$ = 12 ; size = 4
_main PROC
sub esp, 40 ; 00000028H
push esi
push OFFSET _comp
push 4
lea eax, DWORD PTR _numbers$[esp+52]
push 10 ; 0000000aH
push eax
mov DWORD PTR _numbers$[esp+60], 1892 ; 00000764H
mov DWORD PTR _numbers$[esp+64], 45 ; 0000002dH
mov DWORD PTR _numbers$[esp+68], 200 ; 000000c8H
mov DWORD PTR _numbers$[esp+72], -98 ; ffffff9eH
mov DWORD PTR _numbers$[esp+76], 4087 ; 00000ff7H
mov DWORD PTR _numbers$[esp+80], 5
mov DWORD PTR _numbers$[esp+84], -12345 ; ffffcfc7H
mov DWORD PTR _numbers$[esp+88], 1087 ; 0000043fH
mov DWORD PTR _numbers$[esp+92], 88 ; 00000058H
mov DWORD PTR _numbers$[esp+96], -100000 ; fffe7960H
call _qsort
add esp, 16 ; 00000010H这一部分比较普通,可以看到在传递第4个参数的时候传递的是标签_comp的地址关键是看qsort如何调用comp()
qsort位于MSVCR80.dll
.text:7816CBF0 ; void __cdecl qsort(void *, unsigned int, unsigned int, int (__cdecl *)(const ↙
↘ void *, const void *))
.text:7816CBF0 public _qsort
.text:7816CBF0 _qsort proc near
.text:7816CBF0
.text:7816CBF0 lo = dword ptr -104h
.text:7816CBF0 hi = dword ptr -100h
.text:7816CBF0 var_FC = dword ptr -0FCh
.text:7816CBF0 stkptr = dword ptr -0F8h
.text:7816CBF0 lostk = dword ptr -0F4h
.text:7816CBF0 histk = dword ptr -7Ch
.text:7816CBF0 base = dword ptr 4
.text:7816CBF0 num = dword ptr 8
.text:7816CBF0 width = dword ptr 0Ch
.text:7816CBF0 comp = dword ptr 10h
.text:7816CBF0
.text:7816CBF0 sub esp, 100h
…
.text:7816CCE0 loc_7816CCE0: ; CODE XREF: _qsort+B1
.text:7816CCE0 shr eax, 1
.text:7816CCE2 imul eax, ebp
.text:7816CCE5 add eax, ebx
.text:7816CCE7 mov edi, eax
.text:7816CCE9 push edi
.text:7816CCEA push ebx
.text:7816CCEB call [esp+118h+comp];call comp
.text:7816CCF2 add esp, 8
.text:7816CCF5 test eax, eax
.text:7816CCF7 jle short loc_7816CD04在执行qsort()的过程中,系统会把控制权传递给comp参数指向的函数指针的地址。在调用它之前,comp()函数所需的两个参数已经传递到位。在执行它之后,排序已经完成。
Chap24 32位系统处理64位数据
32位系统的通用寄存器GPR都只能容纳32位数据,所以这种平台必须把64位数据转换为一对32位数据才能进行运算。
#include <stdint.h>
uint64_t f ()
{
return 0x1234567890ABCDEF;
};x86
_f PROC
mov eax, -1867788817 ; 90abcdefH
mov edx, 305419896 ; 12345678H
ret 0
_f ENDP32位系统用寄存器组合EDX:EAX来传64位数据
参数传递及加减运算
#include <stdint.h>
uint64_t f_add (uint64_t a, uint64_t b)
{
return a+b;
};
void f_add_test ()
{
#ifdef __GNUC__
printf ("%lld\n", f_add(12345678901234, 23456789012345));
#else
printf ("%I64d\n", f_add(12345678901234, 23456789012345));
#endif
};
uint64_t f_sub (uint64_t a, uint64_t b)
{
return a-b;
};_a$ = 8 ; size = 8
_b$ = 16 ; size = 8
_f_add PROC
mov eax, DWORD PTR _a$[esp-4]
add eax, DWORD PTR _b$[esp-4]
mov edx, DWORD PTR _a$[esp]
adc edx, DWORD PTR _b$[esp]
ret 0
_f_add ENDP
_f_add_test PROC
push 5461 ; 00001555H
push 1972608889 ; 75939f79H
push 2874 ; 00000b3aH
push 1942892530 ; 73ce2ff_subH
call _f_add
push edx
push eax
push OFFSET $SG1436 ; ’%I64d’, 0aH, 00H
call _printf
add esp, 28
ret 0
_f_add_test ENDP
_f_sub PROC
mov eax, DWORD PTR _a$[esp-4]
sub eax, DWORD PTR _b$[esp-4]
mov edx, DWORD PTR _a$[esp]
sbb edx, DWORD PTR _b$[esp]
ret 0
_f_sub ENDP-
在
f1_test()函数,每个64位数据被拆分为了2个32位数据。在内存中,高32位数据在前,低32位在后。加减法运算的处理方法也完全相同
在进行加法运算时,先对低32位相加。如果产生了进位,就设置CF标识位。然后
ADC指令对高32位进行运算,如果此时CF标识位的值为1,则再把32位的运算结果加上1 -
减法运算也是分步进行的。第一次的减法运算可能影响CF标识位。第二次减法运算会根据CF标识位把借位代入计算结果。
在32位系统中,函数在返回64位数据时都使用EDX:EAX寄存器对。
乘法和除法运算
#include <stdint.h>
uint64_t f_mul (uint64_t a, uint64_t b)
{
return a*b;
};
uint64_t f_div (uint64_t a, uint64_t b)
{
return a/b;
};
uint64_t f_rem (uint64_t a, uint64_t b)
{
return a % b;
};msvs x86
_a$ = 8 ; size = 8
_b$ = 16 ; size = 8
_f_mul PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _b$[ebp+4]
push eax
mov ecx, DWORD PTR _b$[ebp]
push ecx
mov edx, DWORD PTR _a$[ebp+4]
push edx
mov eax, DWORD PTR _a$[ebp]
push eax
call __allmul ; long long multiplication
pop ebp
ret 0
_f_mul ENDP
_a$ = 8 ; size = 8
_b$ = 16 ; size = 8
_f_div PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _b$[ebp+4]
push eax
mov ecx, DWORD PTR _b$[ebp]
push ecx
mov edx, DWORD PTR _a$[ebp+4]
push edx
mov eax, DWORD PTR _a$[ebp]
push eax
call __aulldiv ; unsigned long long division
pop ebp
ret 0
_f_div ENDP
_a$ = 8 ; size = 8
_b$ = 16 ; size = 8
_f_rem PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _b$[ebp+4]
push eax
mov ecx, DWORD PTR _b$[ebp]
push ecx
mov edx, DWORD PTR _a$[ebp+4]
push edx
mov eax, DWORD PTR _a$[ebp]
push eax
call __aullrem ; unsigned long long remainder
pop ebp
ret 0
_f_rem ENDP乘除运算复杂很多。所以编译器通常借助标准库函数来处理乘除运算。
但还是都用EDX:EAX传递数据,本来乘除用汇编指令进行,改为用函数处理
而gcc会把乘法运算进行内部处理展开
_f_mul:
push ebx
mov edx, DWORD PTR [esp+8]
mov eax, DWORD PTR [esp+16]
mov ebx, DWORD PTR [esp+12]
mov ecx, DWORD PTR [esp+20]
imul ebx, eax
imul ecx, edx
mul edx
add ecx, ebx
add edx, ecx
pop ebx
ret右移
#include <stdint.h>
uint64_t f (uint64_t a)
{
return a>>7;
};optimizing msvs x86
_a$ = 8 ; size = 8
_f PROC
mov eax, DWORD PTR _a$[esp-4]
mov edx, DWORD PTR _a$[esp]
shrd eax, edx, 7
shr edx, 7
ret 0
_f ENDPoptimizing gcc
_f:
mov edx, DWORD PTR [esp+8]
mov eax, DWORD PTR [esp+4]
shrd eax, edx, 7
shr edx, 7
retSHRD指令。这个指令不仅可以把EAX里的低32位数据右移7位运算,而且还能从EDX寄存器里读取高32位中的低7位、用它填补到低32位数据的高位。
可以发现,32位处理64位数据右移动时分为两步
- 先处理低位,利用
SHRD指令 - 再处理高位,
SHR EDX,7,把高32位数据右移
32位数据转换为64位数据
#include <stdint.h>
int64_t f (int32_t a)
{
return a;
};_a$ = 8
_f PROC
mov eax, DWORD PTR _a$[esp-4]
cdq
ret 0
_f ENDPCDQ(Convert Doubleword to Quadword)是 x86 汇编语言中的一条指令,用于符号扩展寄存器 EAX 到寄存器 EDX:EAX。它通常用于将一个32位有符号整数扩展为64位有符号整数。
CDQ 指令将寄存器 EAX 的最高有效位(即符号位)复制到 EDX 的所有位:
- 如果
EAX的最高有效位是0(表示正数),那么EDX的所有位都被设置为0。 - 如果
EAX的最高有效位是1(表示负数),那么EDX的所有位都被设置为1。
if EAX >= 0 then
EDX := 0;
else
EDX := 0xFFFFFFFF;从而达到了设置符号位的效果
*Chap25 SIMD

-
SIMD意为“单指令流多数据流”,其全称是“Single Instruction, Multiple Data”。顾名思义,这类指令可以一次处理多个数据。在x86的CPU里,SIMD子系统和FPU都由专用模块实现 -
-x86 CPU通过MMX指令率先整合了SIMD的运算功能。支持这种技术的CPU里都有8个64位寄存器,即MM0~MM7。每个MMX寄存器都是8字节寄存器,可以容纳2个32位数据,或者4个16位数据。使用SIMD指令进行操作数的计算时,它可以把8个8位数据分为4组数据同时运算。 -
平面图像可视为一种由二维数组构成的数据结构。在美工人员调整图像亮度的时候,图像编辑程序得对每个像素的亮度系数进行加减法的运算。简单地说,图像的每个像素都有灰度系数,而且灰度系统是8位数据(1个字节)。因而,每执行一个SIMD指令就能够同时调整8个像素的灰度(即亮度)。为了满足这种需要,处理器厂商后来专门推出了基于SIMD技术的饱和度调整指令。这种饱和度调整指令甚至有越界保护功能,能够避免亮度调整时可能会产生的因子上溢(overflow)和下溢(underflow)等问题。
-
SSE技术是SIMD的扩展技术,它把SIMD寄存器扩展为128位寄存器。支持SSE技术的CPU已经有了单独的SIMD通用寄存器,不再复用FPU的寄存器。AVX是另外一种SIMD技术,它的通用寄存器都是256位寄存器。
-
SIMD具体应用- 内存复制和内存比较等用途
- 用于DES的运算。
DES(Data Encryption Standard)是分组对称密码算法,采用了64位的分组和56位的密钥,将64位的输入经过一系列变换得到64位的输出。如果在电路的与、或、非门和导线实现DES模块,电路规模将会是非常庞大。基于并行分组密码算法的Bitslice DES[1]应运而生。这种算法可由单指令并行处理技术/SIMD实现。我们已经知道,x86平台的unsigned int型数据占用32位空间。因此,在进行unsigned int型数据的64位数据和56位密钥的演算时,可以以把64位中间运算结果和运算密钥都分为2个32位数据,再进行分步的并行处理。
矢量化
矢量化泛指将多个标量数组计算为(转换成)一个矢量数组的技术。进行这种计算时,循环体从输入数组中取值,进行某种运算后生成最终数组。这种算法只对数组中的单个元素进行一次运算。“(并行)矢量化技术”是矢量化处理的并行计算技术。
- 用于加法运算
int f (int sz, int *ar1, int *ar2, int *ar3)
{
for (int i=0; i<sz; i++)
ar3[i]=ar1[i]+ar2[i];
return 0;
};icl intel.cpp /QaxSSE2 /Faintel.asm /Ox使用win32 intel编译器
; 函数声明及其参数
; int __cdecl f(int, int *, int *, int *)
public ?f@@YAHHPAH00@Z
?f@@YAHHPAH00@Z proc near
var_10 = dword ptr -10h ; 临时变量,用于存放临时数据
sz = dword ptr 4 ; 参数1,整数 size
ar1 = dword ptr 8 ; 参数2,整数指针 ar1
ar2 = dword ptr 0Ch ; 参数3,整数指针 ar2
ar3 = dword ptr 10h ; 参数4,整数指针 ar3
push edi ; 保存寄存器 edi 的状态
push esi ; 保存寄存器 esi 的状态
push ebx ; 保存寄存器 ebx 的状态
push esi ; 再次保存寄存器 esi 的状态
mov edx, [esp+10h+sz] ; 将参数 sz 赋值给 edx
test edx, edx ; 检查 sz 是否为零或负
jle loc_15B ; 如果 sz <= 0,跳转到 loc_15B 结束函数
mov eax, [esp+10h+ar3] ; 将参数 ar3 赋值给 eax
cmp edx, 6 ; 检查 sz 是否小于等于 6
jle loc_143 ; 如果是,跳转到 loc_143
cmp eax, [esp+10h+ar2] ; 比较 ar3 和 ar2
jbe short loc_36 ; 如果 ar3 <= ar2,跳转到 loc_36
; 如果 ar3 > ar2 并且 sz > 6,进行进一步的计算和条件分支
mov esi, [esp+10h+ar2] ; 将 ar2 赋值给 esi
sub esi, eax ; esi = ar2 - ar3
lea ecx, ds:0[edx*4] ; ecx = sz * 4
neg esi ; esi = -(ar2 - ar3)
cmp ecx, esi ; 比较 ecx 和 esi
jbe short loc_55 ; 如果 ecx <= esi,跳转到 loc_55
loc_36:
cmp eax, [esp+10h+ar2] ; 比较 ar3 和 ar2
jnb loc_143 ; 如果 ar3 >= ar2,跳转到 loc_143
mov esi, [esp+10h+ar2] ; 将 ar2 赋值给 esi
sub esi, eax ; esi = ar2 - ar3
lea ecx, ds:0[edx*4] ; ecx = sz * 4
cmp esi, ecx ; 比较 esi 和 ecx
jb loc_143 ; 如果 esi < ecx,跳转到 loc_143
loc_55:
cmp eax, [esp+10h+ar1] ; 比较 ar3 和 ar1
jbe short loc_67 ; 如果 ar3 <= ar1,跳转到 loc_67
mov esi, [esp+10h+ar1] ; 将 ar1 赋值给 esi
sub esi, eax ; esi = ar1 - ar3
neg esi ; esi = -(ar1 - ar3)
cmp ecx, esi ; 比较 ecx 和 esi
jbe short loc_7F ; 如果 ecx <= esi,跳转到 loc_7F
loc_67:
cmp eax, [esp+10h+ar1] ; 比较 ar3 和 ar1
jnb loc_143 ; 如果 ar3 >= ar1,跳转到 loc_143
mov esi, [esp+10h+ar1] ; 将 ar1 赋值给 esi
sub esi, eax ; esi = ar1 - ar3
cmp esi, ecx ; 比较 esi 和 ecx
jb loc_143 ; 如果 esi < ecx,跳转到 loc_143
loc_7F:
mov edi, eax ; 将 ar3 赋值给 edi
and edi, 0Fh ; 检查 ar3 是否是16字节对齐
jz short loc_9A ; 如果对齐,跳转到 loc_9A
test edi, 3 ; 检查 edi 是否是4字节对齐
jnz loc_162 ; 如果不是,跳转到 loc_162
neg edi ; edi = -edi
add edi, 10h ; edi += 16
shr edi, 2 ; edi /= 4
loc_9A:
lea ecx, [edi+4] ; ecx = edi + 4
cmp edx, ecx ; 比较 sz 和 ecx
jl loc_162 ; 如果 sz < ecx,跳转到 loc_162
mov ecx, edx ; ecx = sz
sub ecx, edi ; ecx -= edi
and ecx, 3 ; ecx &= 3
neg ecx ; ecx = -ecx
add ecx, edx ; ecx += sz
test edi, edi ; 检查 edi 是否为零
jbe short loc_D6 ; 如果 edi <= 0,跳转到 loc_D6
mov ebx, [esp+10h+ar2] ; 将 ar2 赋值给 ebx
mov [esp+10h+var_10], ecx; 将 ecx 赋值给临时变量
mov ecx, [esp+10h+ar1] ; 将 ar1 赋值给 ecx
xor esi, esi ; 清空 esi
loc_C1:
mov edx, [ecx+esi*4] ; 将 ar1[esi] 赋值给 edx
add edx, [ebx+esi*4] ; 将 ar2[esi] 加到 edx
mov [eax+esi*4], edx ; 将结果存到 ar3[esi]
inc esi ; esi++
cmp esi, edi ; 比较 esi 和 edi
jb short loc_C1 ; 如果 esi < edi,跳转到 loc_C1
mov ecx, [esp+10h+var_10]; 将临时变量赋值回 ecx
mov edx, [esp+10h+sz] ; 将 sz 赋值给 edx
loc_D6:
mov esi, [esp+10h+ar2] ; 将 ar2 赋值给 esi
lea esi, [esi+edi*4] ; esi += edi * 4
test esi, 0Fh ; 检查 esi 是否16字节对齐
jz short loc_109 ; 如果对齐,跳转到 loc_109
mov ebx, [esp+10h+ar1] ; 将 ar1 赋值给 ebx
mov esi, [esp+10h+ar2] ; 将 ar2 赋值给 esi
loc_ED:
movdqu xmm1, xmmword ptr [ebx+edi*4] ; 将 ar1[edi] 赋值给 xmm1
movdqu xmm0, xmmword ptr [esi+edi*4] ; 将 ar2[edi] 赋值给 xmm0
paddd xmm1, xmm0 ; xmm1 += xmm0
movdqa xmmword ptr [eax+edi*4], xmm1 ; 将结果存到 ar3[edi]
add edi, 4 ; edi += 4
cmp edi, ecx ; 比较 edi 和 ecx
jb short loc_ED ; 如果 edi < ecx,跳转到 loc_ED
jmp short loc_127 ; 跳转到 loc_127
loc_109:
mov ebx, [esp+10h+ar1] ; 将 ar1 赋值给 ebx
mov esi, [esp+10h+ar2] ; 将 ar2 赋值给 esi
loc_111:
movdqu xmm0, xmmword ptr [ebx+edi*4] ; 将 ar1[edi] 赋值给 xmm0
paddd xmm0, xmmword ptr [esi+edi*4] ; xmm0 += ar2[edi]
movdqa xmmword ptr [eax+edi*4], xmm0 ; 将结果存到 ar3[edi]
add edi, 4 ; edi += 4
cmp edi, ecx ; 比较 edi 和 ecx
jb short loc_111 ; 如果 edi < ecx,跳转到 loc_111
loc_127:
cmp ecx, edx ; 比较 ecx 和 edx
jnb short loc_15B ; 如果 ecx >= edx,跳转到 loc_15B
mov esi, [esp+10h+ar1] ; 将 ar1 赋值给 esi
mov edi, [esp+10h+ar2] ; 将 ar2 赋值给 edi
loc_133:
mov ebx, [esi+ecx*4] ; 将 ar1[ecx] 赋值给 ebx
add ebx, [edi+ecx*4] ; 将 ar2[ecx] 加到 ebx
mov [eax+ecx*4], ebx ; 将结果存到 ar3[ecx]
inc ecx ; ecx++
cmp ecx, edx ; 比较 ecx 和 edx
jb short loc_133 ; 如果 ecx < edx,跳转到 loc_133
jmp short loc_15B ; 跳转到 loc_15B
loc_143:
mov esi, [esp+10h+ar1] ; 将 ar1 赋值给 esi
mov edi, [esp+10h+ar2] ; 将 ar2 赋值给 edi
xor ecx, ecx ; 清空 ecx
loc_14D:
mov ebx, [esi+ecx*4] ; 将 ar1[ecx] 赋值给 ebx
add ebx, [edi+ecx*4] ; 将 ar2[ecx] 加到 ebx
mov [eax+ecx*4], ebx ; 将结果存到 ar3[ecx]
inc ecx ; ecx++
cmp ecx, edx ; 比较 ecx 和 edx
jb short loc_14D ; 如果 ecx < edx,跳转到 loc_14D
loc_15B:
xor eax, eax ; eax = 0,返回0
pop ecx ; 恢复寄存器 ecx
pop ebx ; 恢复寄存器 ebx
pop esi ; 恢复寄存器 esi
pop edi ; 恢复寄存器 edi
retn ; 返回
loc_162:
xor ecx, ecx ; ecx = 0
jmp short loc_127 ; 跳转到 loc_127
?f@@YAHHPAH00@Z endp
MOVDQU(Move Unaligned Double Quadword)从内存加载16字节数据,并复制到XMM寄存器的指令PADDD(Add Packed Integers)是对4对32位数进行加法运算,并把运算结果存储到第一个操作符的指令。此外,该指令不会设置任何标志位,在溢出时只保留运算结果的低32位,也不会报错。如果PADDD的某个操作数是内存中的某个值,那么这个值的地址必须与16字节边界对齐,否则将报错MOVDQA(Move Aligned Double Quadword)的功能MOVDQU相同,只是要求存储操作数的内存地址必须向16字节边界对齐,否则报错。除了这点区别之外,两个指令完全相同。此外,MOVDQA的运行速度要比MOVDQU快。
-
用于内存复制
#include <stdio.h> void my_memcpy (unsigned char* dst, unsigned char* src, size_t cnt) { size_t i; for (i=0; i<cnt; i++) dst[i]=src[i]; };生成的代码属实晦涩难懂,看不懂
SIMD实现strlen()
在C/C++源程序中插入特定的宏即可调用SIMD指令。在MSVC编译器的库文件之中,intrin.h文件就使用了这种宏。
我们可以把字符串进行分组处理,使用SIMD指令实现strlen()函数。这种算法比常规实现算法快2~2.5倍。它每次把16个字符加载到1个XMM寄存器里,然后检测字符串的结束标志—数值为零的结束符
Chap26 64位平台
x86-64框架是一种兼容x86指令集的64位微处理器架构。
从逆向工程的角度来说,这种框架的主要区别在于:
-
除了位于FPU和SIMD的寄存器之外,几乎所有的寄存器都变为64位寄存器。所有指令都可以通过R-字头的助记符(寄存器名称)调用64位寄存器。而且x86-64框架的CPU要比x86框架的CPU多出8个通用寄存器。这些通用寄存器分别是:RAX、RBX、RCX、RDX、RBP、RSP、RSI、RDI、R8、R9、R10、R11、R12、R13、R14、R15。
-
它向下兼容,允许程序使用GPR的32位寄存器的助记符、操作该寄存器的低32位数据。例如说,程序可以通过助记符EAX访问RAX寄存器的低32位。

-
64位寄存器特有的R8~R15寄存器不仅有相应的(低)32位助记符,即R8D~R15D(低32位),而且还有相应的(低)16位助记符R8W~R15W。
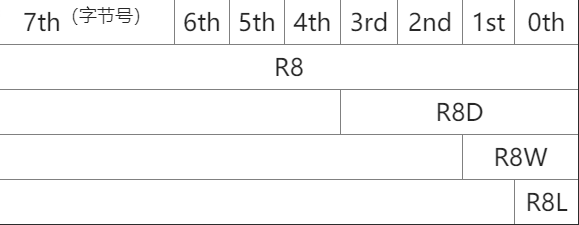
-
x86-64框架的CPU有16个SIMD寄存器,即XMM0~XMM15。它的SIMD寄存器比x86 CPU多出一倍。
*Chap27 SIMD与浮点数的并行运算
*Chap28 ARM指令详解
*Chap29 MIPS的特点
Part.3 硬件基础
Chap30 有符号数的表示方法
-
有符号数通常以二进制补码[1]的形式存储于应用程序里。
-
为了正确操作有符号数和无符号数,条件转移指令(参见本书第12章)特地分为JG/JL系列(signed型)和JA/JBE系列(unsigned型)两套指令
-
同一个数值即可以表示有符号数,也可以表示无符号数。
-
C/C++的有符号型数据有:
- int64_t(从−9223372036854775806至9223372036854775807),即从0x8000000000000000至0x7FFFFFFFFFFFFFFF)
- int(取值范围从−2147483646至2147483647,即0x80000000至0x7FFFFFFF)。
- char(取值范围从−127至128,即从0x7F至0x80)。
- ssize_t。
无符号型数据有:
- uint64_t(从0至18446744073709551615/0xFFFFFFFFFFFFFFFF):
- unsigned int(取值范围从0至4294967295,即从0至0xFFFFFFFF)。
- unsigned char(取值范围从0至255,即从0至0xFF)。
- size_t。
-
有符号数的最高数权位是符号位:1代表负数,0代表正数。
-
从数据宽度较小的数据转换为数据宽度较大的数据是可行的。
-
负数的补码和原码的双向转换过程是相同的,都是逐位求非再加1。这种运算过程简单易记:同一个值的正负数是相反的值,所以要求非;求非之后再加1则是因为中间的“零”占了一个数的位置。
-
加减运算不区分有符号数和无符号数,它们的加减运算指令完全相同。但是乘除法运算还是有区别的:在x86指令集里,有符号数的乘除指令是IMUL/IDIV,而无符号数的指令是MUL/DIV。
-
此外,有符号数的操作指令更多一些。例如CBW/CWD/CWDE/CDQ/CDQE(附录A.6.3)、MOVSX(15.1.1节),SAR(附录A.6.3)。
Chap31 字节序
- 小端字节序(Little-Endian)指低数权字节数据存放在内存低地址,高数权字节数据存放在高地址
- 大端字节序(Big-Endian)指高数权字节数据存放在低地址,低字节数据存放在高地址处的内存分布方式
大端字节序
在采用大端字节序时,0x12345678在内存中的存储方式如下所示。
| 内存地址 | 字节值 |
|---|---|
| +0 | 0x12 |
| +1 | 0x34 |
| +2 | 0x56 |
| +3 | 0x78 |
Motorola 68k、IBM POWER系列CPU采用大端字节序。
小端字节序
在采用小端字节序时,0x12345678在内存中的存储方式如下所示。
| 内存地址 | 字节值 |
|---|---|
| +0 | 0x78 |
| +1 | 0x56 |
| +2 | 0x34 |
| +3 | 0x12 |
Intel x86系列CPU采用小端字节序。
正是因为MIPS的硬件平台可能采用两种不同的字节序,所以MIPS Linux又分为采用大端字节序的MIPS Linux和采用小端字节序的mipsel Linux。在采取一种字节序的平台上编译出来的程序,不可能在另一种字节序的平台上运行。
双模二元数据格式
ARM、PowerPC、SPARC、MIPS、IA64等CPU采用双模二元数据格式(Bi-endian),它们即可以工作于小端字节序也可以切换到大端字节序。
转换字节序
BSWAP指令可在汇编层面转换数据的字节序
TCP/IP数据序的封装规范采用大端字节序,所以采用小端字节序平台的系统就需要使用专门的转换字节序的函数
常用的字节序转换函数是htonl()和htons()。htonl()(host-to-network long)和htons()(host-to-network short)(把主机字节顺序转为网络字节顺序)
在TCP/IP的术语里,大端字节序又称为“网络字节顺序(Network Byte Order)”,网络主机采用的字节序叫作“主机字节顺序”。x86和其他一些平台的主机字节序是小端字节序,但是IBM POWER等著名服务器系列均采用大端字节序。因此,在主机字节顺序为大端字节序的平台上使用htonl()或htons()函数转换字节序,其实不会进行真正意义上的字节重排。
Chap32 内存布局
C/C++把内存划分为许多区域,主要的内存区域有:
- 全局内存空间,又称为“
(全局)静态存储区static memory allocation”编程人员不需要为全局变量和静态变量明确划分存储空间凡是由源程序声明的全局变量、全局数组,编译器都能够在数据段或常量段为其分配适当的存储空间。由于整个程序都可以访问这个区域的数据,所以人们认为使用这种存储空间数据会破坏程序的结构化体系。此外,在全局内存区存储数据之前,必须事先声明其确切的容量。因而这个空间不适用于存储缓存或动态数组。在全局内存空间出现的缓冲区溢出问题,往往将覆盖在内存中相邻位置的变量或缓存(请参阅本书7.2节的案例)。 栈空间,即分配给栈的存储区域。它是由编译器自动分配、释放的存储区域,常用于存放函数的参数和局部变量。在特定情况下,局部变量可被其他函数访问(局部变量的指针作为参数传递给被调用方函数)。在指令层面,“分配和释放栈空间的实质就是调整SP寄存器的值,因而分配和释放栈空间的操作速度非常快。编译器只能为那些在编译阶段确定存储空间的局部变量分配栈空间。因此,无法事先预判存储空间的缓冲型数据类型,即缓冲区和动态数组(除非使用alloc()函数)不会被分配到栈空间里。在栈空间发生的缓冲区溢出问题,通常会篡改栈里的重要数据堆空间,即“动态内存分配区。C语言的malloc()/free()函数或C++的new/delete语句即可分配、释放堆空间)。“不必事先声明堆空间的大小”即“可在程序启动以后再确定数据块的容量”这一特征构成了其独特的便利性。另外,程序员还可以动态调整(realloc()函数)内存块的大小,只是调整堆空间的操作速度不很理想。在内存分配操作中,申请、释放堆空间的操作是速度最慢的操作:在分配、释放堆空间时,进行这种操作的程序必须支持并且更新所有控制结构。在这个区域发生的缓冲区溢出经常会覆盖堆空间的数据结构体。堆空间管理不当还会发生内存泄露问题:所有被分配的堆空间都应当被明确地释放,否则就会出现内存泄露问题。但是程序员可能会出现“忘记释放堆空间”的问题,还有发生释放不彻底的问题。另外,“在调用free()函数释放空间之后再次直接使用这块内存区域”的指令同样会带来非常严重的安全问题(请参阅本书21.2节的案例)。
Chap33 CPU
分支预测
现在的主流编译器基本都不怎么分配条件转移指令了(因为效率低)。
虽然目前的分支预测功能并不完美,但是编译器还是在向这一方向发展。
ARM平台出现的条件执行指令(例如ADRcc)及x86平台出现的CMOVcc指令,都是这一趋势的明证。
CMOVcc指令集(Conditional Move Instructions)是 x86 汇编语言中的一类条件传送指令。这些指令用于根据条件代码寄存器(通常是CPU的标志寄存器)的状态来决定是否执行寄存器之间的条件数据移动。cc表示不同的条件代码,例如E表示等于,NE表示不等于等。
数据相关性
当代的CPU多数都能并行执行指令(OOE/乱序执行技术)。但是,要充分利用CPV的乱序执行功能、尽可能频繁地同期执行多条指令,首先就要降低各指令之间的数据相关性。所以,编译器尽可能地分配那些不怎么影响CPU标识的指令。
因为LEA指令并不像其他数学运算指令那样影响标识位,所以编译器越来越多地使用这种指令。
Chap34 hash
- 哈希(hash)函数能够生成可靠程度较高的校验和(Checksum),可充分满足数据检验的需要。
- CRC32算法就是一种不太复杂的哈希算法。
- 哈希值是一种固定长度的信息摘要,不可能根据哈希值逆向“推测”出信息原文。所以,无论CRC32算法计算的信息原文有多长,它只能生成32位的校验和。
- 但是从加密学的角度看,我们可以轻易地伪造出满足同一CRC32哈希值的多个信息原文。当然,防止伪造就是加密哈希函数(Cryptographic hash function)的任务了。
- 此外,人们普遍使用MD5、SHA1等哈希算法生成用户密码的摘要(哈希值),然后再把密码摘要存储在数据库里。
实际上网上论坛等涉及用户密码的数据库,存储的密码信息差不多都是用户密码的哈希值;否则一旦发生数据库泄露等问题,入侵人员将能够轻易地获取密码原文。不仅如此,当用户登录网站的时候,网络论坛等应用程序检验的也不是密码原文,它们检验的还是密码哈希值:如果用户名和密码哈希值与数据库里的记录匹配,它将授予登录用户相应的访问权限。另外,常见的密码破解工具通常都是通过穷举密码的方法,查找符合密码哈希值的密码原文而已。其他类型的密码破解工具就要复杂得多。
- 单向函数(one-way function))是一种具有下述特点的单射函数:对于每一个输入,函数值都容易计算(多项式时间);但是根据函数值对原始输入进行逆向推算却比较困难(无法在多项式时间内使用确定性图灵机计算)。
Part.4 一些高级的例子
Chap35 温度转换
这是从华氏度转换成摄氏度的计算公式,再加上一些简单的出错处理
#include <stdio.h>
#include <stdlib.h>
int main()
{
int celsius, fahr;
printf ("Enter temperature in Fahrenheit:\n");
if (scanf ("%d", &fahr)!=1)
{
printf ("Error while parsing your input\n");
exit(0);
};
celsius = 5 * (fahr-32) / 9;
if (celsius<-273)
{
printf ("Error: incorrect temperature!\n");
exit(0);
};
printf ("Celsius: %d\n", celsius);
};x86 构架下msvs 2012优化
$SG4228 DB 'Enter temperature in Fahrenheit:', 0aH, 00H
$SG4230 DB '%d', 00H
$SG4231 DB 'Error while parsing your input', 0aH, 00H
$SG4233 DB 'Error: incorrect temperature!', 0aH, 00H
$SG4234 DB 'Celsius: %d', 0aH, 00H
_fahr$ = -4 ; size = 4
_main PROC
push ecx
push esi
mov esi, DWORD PTR __imp__printf
push OFFSET $SG4228 ; 'Enter temperature in Fahrenheit:'
call esi ; call printf()
lea eax, DWORD PTR _fahr$[esp+12]
push eax
push OFFSET $SG4230 ; '%d'
call DWORD PTR __imp__scanf
add esp, 12 ; 0000000cH
cmp eax, 1
je SHORT $LN2@main
push OFFSET $SG4231 ; 'Error while parsing your input'
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN9@main:
$LN2@main:
mov eax, DWORD PTR _fahr$[esp+8]
add eax, -32 ; ffffffe0H
lea ecx, DWORD PTR [eax+eax*4]
mov eax, 954437177 ; 38e38e39H
imul ecx
sar edx, 1
mov eax, edx
shr eax, 31 ; 0000001fH
add eax, edx ;eax/9
cmp eax, -273 ; fffffeefH
jge SHORT $LN1@main
push OFFSET $SG4233 ; 'Error: incorrect temperature!'
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN10@main:
$LN1@main:
push eax
push OFFSET $SG4234 ; 'Celsius: %d'
call esi ; call printf()
add esp, 8
; return 0 - by C99 standard
xor eax, eax
pop esi
pop ecx
ret 0
$LN8@main:
_main ENDP- 程序首先把
printf()函数的内存地址保存到ESI寄存器,方便后续调用 - 使用加法
ADD EAX,-32来代替减法 - 这里用乘法来代替了除9,可以提高效率,参见chap41
- 如果主函数
main()没有明确的返回值,在程序退出时默认为0
x64 构架下的msvs2012优化
xor ecx, ecx
call QWORD PTR __imp_exit
int 3在x64中,每次调用exit()函数之后都有一个int 3指令
INT 3是调试器debugger的断点设置指令。
当程序执行exit()函数之后,它就不会再返回到原程序,而是直接退出了。编译器大概认为,在发生异常退出的情况下,通常人们应当使用调试器分析异常情况吧。
浮点数运算
将以上代码改为浮点数计算版本
#include <stdio.h>
#include <stdlib.h>
int main()
{
double celsius, fahr;
printf ("Enter temperature in Fahrenheit:\n");
if (scanf ("%lf", &fahr)!=1)
{
printf ("Error while parsing your input\n");
exit(0);
};
celsius = 5 * (fahr-32) / 9;
if (celsius<-273)
{
printf ("Error: incorrect temperature!\n");
exit(0);
};
printf ("Celsius: %lf\n", celsius);
};msvs 2010 x86
$SG4038 DB 'Enter temperature in Fahrenheit:', 0aH, 00H
$SG4040 DB '%lf', 00H
$SG4041 DB 'Error while parsing your input', 0aH, 00H
$SG4043 DB 'Error: incorrect temperature!', 0aH, 00H
$SG4044 DB 'Celsius: %lf', 0aH, 00H
__real@c071100000000000 DQ 0c071100000000000r ; -273
__real@4022000000000000 DQ 04022000000000000r ; 9
__real@4014000000000000 DQ 04014000000000000r ; 5
__real@4040000000000000 DQ 04040000000000000r ; 32
_fahr$ = -8 ; size = 8
_main PROC
sub esp, 8
push esi
mov esi, DWORD PTR __imp__printf
push OFFSET $SG4038 ; 'Enter temperature in Fahrenheit:'
call esi ; call printf()
lea eax, DWORD PTR _fahr$[esp+16];eax=fahr
push eax
push OFFSET $SG4040 ; '%lf'
call DWORD PTR __imp__scanf
add esp, 12 ; 0000000cH
cmp eax, 1
je SHORT $LN2@main
push OFFSET $SG4041 ; 'Error while parsing your input'
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN2@main:
fld QWORD PTR _fahr$[esp+12];st[0]=fahr
fsub QWORD PTR __real@4040000000000000 ; 32
fmul QWORD PTR __real@4014000000000000 ; 5
fdiv QWORD PTR __real@4022000000000000 ; 9
fld QWORD PTR __real@c071100000000000 ; -273
fcomp ST(1);比较st[0] [1]
fnstsw ax
test ah, 65 ; 00000041H
jne SHORT $LN1@main
push OFFSET $SG4043 ; 'Error: incorrect temperature!'
fstp ST(0)
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN1@main:
sub esp, 8
fstp QWORD PTR [esp]
push OFFSET $SG4044 ; 'Celsius: %lf'
call esi
add esp, 12 ; 0000000cH
; return 0 - by C99 standard
xor eax, eax
pop esi
add esp, 8
ret 0
$LN10@main:
_main ENDP-
fcomp ST(1)与cmp类似,ST(1)和ST(0)比较后会设置status wordtest ah 65与jne结合可以达到判断>=的情况
然而MSVS 2012分配的却是SIMD指令
$SG4228 DB 'Enter temperature in Fahrenheit:', 0aH, 00H
$SG4230 DB '%lf', 00H
$SG4231 DB 'Error while parsing your input', 0aH, 00H
$SG4233 DB 'Error: incorrect temperature!', 0aH, 00H
$SG4234 DB 'Celsius: %lf', 0aH, 00H
__real@c071100000000000 DQ 0c071100000000000r ; -273
__real@4040000000000000 DQ 04040000000000000r ; 32
__real@4022000000000000 DQ 04022000000000000r ; 9
__real@4014000000000000 DQ 04014000000000000r ; 5
_fahr$ = -8 ; size = 8
_main PROC
sub esp, 8
push esi
mov esi, DWORD PTR __imp__printf
push OFFSET $SG4228 ; 'Enter temperature in Fahrenheit:'
call esi ; call printf()
lea eax, DWORD PTR _fahr$[esp+16]
push eax
push OFFSET $SG4230 ; '%lf'
call DWORD PTR __imp__scanf
add esp, 12 ; 0000000cH
cmp eax, 1
je SHORT $LN2@main
push OFFSET $SG4231 ; 'Error while parsing your input'
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN9@main:
$LN2@main:
movsd xmm1, QWORD PTR _fahr$[esp+12]
subsd xmm1, QWORD PTR __real@4040000000000000 ; 32
movsd xmm0, QWORD PTR __real@c071100000000000 ; -273
mulsd xmm1, QWORD PTR __real@4014000000000000 ; 5
divsd xmm1, QWORD PTR __real@4022000000000000 ; 9
comisd xmm0, xmm1
jbe SHORT $LN1@main
push OFFSET $SG4233 ; 'Error: incorrect temperature!'
call esi ; call printf()
add esp, 4
push 0
call DWORD PTR __imp__exit
$LN10@main:
$LN1@main:
sub esp, 8
movsd QWORD PTR [esp], xmm1
push OFFSET $SG4234 ; 'Celsius: %lf'
call esi ; call printf()
add esp, 12 ; 0000000cH
; return 0 - by C99 standard
xor eax, eax
pop esi
add esp, 8
ret 0
$LN8@main:
_main ENDP-
这里比较简单,就是把
xmm1当做一个普通的寄存器(可以看做是多个fpu)就可以了x86的指令集确实支持SIMD指令,浮点数运算也毫无问题。大概是这种方式的计算指令比较简单,所以微软的编译器分配了SIMD指令。
Chap36 斐波那契数列
#include <stdio.h>
void fib (int a, int b, int limit)
{
printf ("%d\n", a+b);
if (a+b > limit)
return;
fib (b, a+b, limit);
};
int main()
{
printf ("0\n1\n1\n");
fib (1, 1, 20);
};msvs 2010 x86 asm
_TEXT SEGMENT
_a$ = 8 ; size = 4
_b$ = 12 ; size = 4
_limit$ = 16 ; size = 4
_fib PROC;fib(a,b)
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp];eax=a
add eax, DWORD PTR _b$[ebp];eax=a+b
push eax;a+b,入栈
push OFFSET $SG2750 ; "%d"
call DWORD PTR __imp__printf
add esp, 8
mov ecx, DWORD PTR _limit$[ebp];ecx=limits
push ecx
mov edx, DWORD PTR _a$[ebp]
add edx, DWORD PTR _b$[ebp]
push edx;a+b入栈
mov eax, DWORD PTR _b$[ebp];eax=b
push eax
call _fib,fib(b,a+b)
add esp, 12
pop ebp
ret 0
_fib ENDP
_main PROC
push ebp
mov ebp, esp
push OFFSET $SG2753 ; "0\n1\n1\n"
call DWORD PTR __imp__printf
add esp, 4
push 20
push 1
push 1
call _fib
add esp, 12
xor eax, eax
pop ebp
ret 0
_main ENDP分析栈里的内容
0035F940 00FD1039 RETURN to fib.00FD1039 from fib.00FD1000
0035F944 00000008 1st argument: a
0035F948 0000000D 2nd argument: b
0035F94C 00000014 3rd argument: limit
0035F950 /0035F964 saved EBP register
0035F954 |00FD1039 RETURN to fib.00FD1039 from fib.00FD1000
0035F958 |00000005 1st argument: a
0035F95C |00000008 2nd argument: b
0035F960 |00000014 3rd argument: limit
0035F964 ]0035F978 saved EBP register
0035F968 |00FD1039 RETURN to fib.00FD1039 from fib.00FD1000
0035F96C |00000003 1st argument: a
0035F970 |00000005 2nd argument: b
0035F974 |00000014 3rd argument: limit
0035F978 ]0035F98C saved EBP register
0035F97C |00FD1039 RETURN to fib.00FD1039 from fib.00FD1000
0035F980 |00000002 1st argument: a
0035F984 |00000003 2nd argument: b
0035F988 |00000014 3rd argument: limit
0035F98C ]0035F9A0 saved EBP register
0035F990 |00FD1039 RETURN to fib.00FD1039 from fib.00FD1000
0035F994 |00000001 1st argument: a
0035F998 |00000002 2nd argument: b
0035F99C |00000014 3rd argument: limit
0035F9A0 ]0035F9B4 saved EBP register
0035F9A4 |00FD105C RETURN to fib.00FD105C from fib.00FD1000
0035F9A8 |00000001 1st argument: a \
0035F9AC |00000001 2nd argument: b | prepared in main() for f1()
0035F9B0 |00000014 3rd argument: limit /
0035F9B4 ]0035F9F8 saved EBP register
0035F9B8 |00FD11D0 RETURN to fib.00FD11D0 from fib.00FD1040
0035F9BC |00000001 main() 1st argument: argc \
0035F9C0 |006812C8 main() 2nd argument: argv | prepared in CRT for main()
0035F9C4 |00682940 main() 3rd argument: envp /- 本例属于递归函数。递归函数的栈一般是这样的"三明治结构"
- 栈的最底部,一个是
main()为f1()作准备,另外一个是CRT为main()做准备 - 在上述程序中,limit(阈值)参数总是保持不变(十六进制的14,也就是十进制的20),而两个参数a和b在每次调用函数的时候都是不同的值。
- 此外栈也存储了RA和保存EBP(扩展堆栈指针)的值。OllyDbg能基于EBP的值判断栈的存储结构,因此它能够用括弧标注栈帧。换而言之,在每个括弧里的一组数值都形成了一个相对独立的栈结构,即栈帧(stack frame)。栈帧就是每次函数调用期间的数据实体。
- 另一方面,即使从技术方面看每个被调用方函数确实可以访问栈帧之外的栈存储空间,但是正常情况下不应当访问栈帧之外的数据(当然除了获取函数参数的操作以外)。对于没有bug(缺陷)的函数来说,上述命题的确成立。每一个 EBP值都是前一个栈帧的地址。因此调试程序能够把数据栈识别为栈帧,并能识别出每次调用函数时传递的参数值。
程序的最后部分,main()有3个参数。其中argc(参数总数)为1
Chap37 CRC32
这是一个基于表查询技术实现的CRC32校验值的计算程序:
/* By Bob Jenkins, (c) 2006, Public Domain */
#include <stdio.h>
#include <stddef.h>
#include <string.h>
typedef unsigned long ub4;
typedef unsigned char ub1;
static const ub4 crctab[256] = {
0x00000000, 0x77073096, 0xee0e612c, 0x990951ba, 0x076dc419, 0x706af48f,
0xe963a535, 0x9e6495a3, 0x0edb8832, 0x79dcb8a4, 0xe0d5e91e, 0x97d2d988,
0x09b64c2b, 0x7eb17cbd, 0xe7b82d07, 0x90bf1d91, 0x1db71064, 0x6ab020f2,
0xf3b97148, 0x84be41de, 0x1adad47d, 0x6ddde4eb, 0xf4d4b551, 0x83d385c7,
0x136c9856, 0x646ba8c0, 0xfd62f97a, 0x8a65c9ec, 0x14015c4f, 0x63066cd9,
0xfa0f3d63, 0x8d080df5, 0x3b6e20c8, 0x4c69105e, 0xd56041e4, 0xa2677172,
0x3c03e4d1, 0x4b04d447, 0xd20d85fd, 0xa50ab56b, 0x35b5a8fa, 0x42b2986c,
0xdbbbc9d6, 0xacbcf940, 0x32d86ce3, 0x45df5c75, 0xdcd60dcf, 0xabd13d59,
0x26d930ac, 0x51de003a, 0xc8d75180, 0xbfd06116, 0x21b4f4b5, 0x56b3c423,
0xcfba9599, 0xb8bda50f, 0x2802b89e, 0x5f058808, 0xc60cd9b2, 0xb10be924,
0x2f6f7c87, 0x58684c11, 0xc1611dab, 0xb6662d3d, 0x76dc4190, 0x01db7106,
0x98d220bc, 0xefd5102a, 0x71b18589, 0x06b6b51f, 0x9fbfe4a5, 0xe8b8d433,
0x7807c9a2, 0x0f00f934, 0x9609a88e, 0xe10e9818, 0x7f6a0dbb, 0x086d3d2d,
0x91646c97, 0xe6635c01, 0x6b6b51f4, 0x1c6c6162, 0x856530d8, 0xf262004e,
0x6c0695ed, 0x1b01a57b, 0x8208f4c1, 0xf50fc457, 0x65b0d9c6, 0x12b7e950,
0x8bbeb8ea, 0xfcb9887c, 0x62dd1ddf, 0x15da2d49, 0x8cd37cf3, 0xfbd44c65,
0x4db26158, 0x3ab551ce, 0xa3bc0074, 0xd4bb30e2, 0x4adfa541, 0x3dd895d7,
0xa4d1c46d, 0xd3d6f4fb, 0x4369e96a, 0x346ed9fc, 0xad678846, 0xda60b8d0,
0x44042d73, 0x33031de5, 0xaa0a4c5f, 0xdd0d7cc9, 0x5005713c, 0x270241aa,
0xbe0b1010, 0xc90c2086, 0x5768b525, 0x206f85b3, 0xb966d409, 0xce61e49f,
0x5edef90e, 0x29d9c998, 0xb0d09822, 0xc7d7a8b4, 0x59b33d17, 0x2eb40d81,
0xb7bd5c3b, 0xc0ba6cad, 0xedb88320, 0x9abfb3b6, 0x03b6e20c, 0x74b1d29a,
0xead54739, 0x9dd277af, 0x04db2615, 0x73dc1683, 0xe3630b12, 0x94643b84,
0x0d6d6a3e, 0x7a6a5aa8, 0xe40ecf0b, 0x9309ff9d, 0x0a00ae27, 0x7d079eb1,
0xf00f9344, 0x8708a3d2, 0x1e01f268, 0x6906c2fe, 0xf762575d, 0x806567cb,
0x196c3671, 0x6e6b06e7, 0xfed41b76, 0x89d32be0, 0x10da7a5a, 0x67dd4acc,
0xf9b9df6f, 0x8ebeeff9, 0x17b7be43, 0x60b08ed5, 0xd6d6a3e8, 0xa1d1937e,
0x38d8c2c4, 0x4fdff252, 0xd1bb67f1, 0xa6bc5767, 0x3fb506dd, 0x48b2364b,
0xd80d2bda, 0xaf0a1b4c, 0x36034af6, 0x41047a60, 0xdf60efc3, 0xa867df55,
0x316e8eef, 0x4669be79, 0xcb61b38c, 0xbc66831a, 0x256fd2a0, 0x5268e236,
0xcc0c7795, 0xbb0b4703, 0x220216b9, 0x5505262f, 0xc5ba3bbe, 0xb2bd0b28,
0x2bb45a92, 0x5cb36a04, 0xc2d7ffa7, 0xb5d0cf31, 0x2cd99e8b, 0x5bdeae1d,
0x9b64c2b0, 0xec63f226, 0x756aa39c, 0x026d930a, 0x9c0906a9, 0xeb0e363f,
0x72076785, 0x05005713, 0x95bf4a82, 0xe2b87a14, 0x7bb12bae, 0x0cb61b38,
0x92d28e9b, 0xe5d5be0d, 0x7cdcefb7, 0x0bdbdf21, 0x86d3d2d4, 0xf1d4e242,
0x68ddb3f8, 0x1fda836e, 0x81be16cd, 0xf6b9265b, 0x6fb077e1, 0x18b74777,
0x88085ae6, 0xff0f6a70, 0x66063bca, 0x11010b5c, 0x8f659eff, 0xf862ae69,
0x616bffd3, 0x166ccf45, 0xa00ae278, 0xd70dd2ee, 0x4e048354, 0x3903b3c2,
0xa7672661, 0xd06016f7, 0x4969474d, 0x3e6e77db, 0xaed16a4a, 0xd9d65adc,
0x40df0b66, 0x37d83bf0, 0xa9bcae53, 0xdebb9ec5, 0x47b2cf7f, 0x30b5ffe9,
0xbdbdf21c, 0xcabac28a, 0x53b39330, 0x24b4a3a6, 0xbad03605, 0xcdd70693,
0x54de5729, 0x23d967bf, 0xb3667a2e, 0xc4614ab8, 0x5d681b02, 0x2a6f2b94,
0xb40bbe37, 0xc30c8ea1, 0x5a05df1b, 0x2d02ef8d,
};
/* how to derive the values in crctab[] from polynomial 0xedb88320 */
void build_table()
{
ub4 i, j;
for (i=0; i<256; ++i) {
j = i;
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
printf("0x%.8lx, ", j);
if (i%6 == 5) printf("\n");
}
}
/* the hash function */
ub4 crc(const void *key, ub4 len, ub4 hash)
{
ub4 i;
const ub1 *k = key;
for (hash=len, i=0; i<len; ++i)
hash = (hash >> 8) ^ crctab[(hash & 0xff) ^ k[i]];
return hash;
}
/* To use, try "gcc -O crc.c -o crc; crc < crc.c" */
int main()
{
char s[1000];
while (gets(s)) printf("%.8lx\n", crc(s, strlen(s), 0));
return 0;
}- 对于加密算法的实现,我们往往只关注关键函数的详细细节。对于CRC32效验算法,我们就要特别关注
crc()的实现。注意for()语句的两个初始指令hash=len和i=0。当然,在C/C++语言里,我们可以一次指定两条循环初始指令,而在最终的汇编指令层面,就会出现两条初始化指令
_key$ = 8 ; size = 4
_len$ = 12 ; size = 4
_hash$ = 16 ; size = 4
_crc PROC
mov edx, DWORD PTR _len$[esp-4]
xor ecx, ecx ; ecx=0,,,i will be stored in ECX
mov eax, edx;eax=len
test edx, edx
jbe SHORT $LN1@crc;edx<=len?
push ebx
push esi
mov esi, DWORD PTR _key$[esp+4] ; ESI = key
push edi
$LL3@crc:
; work with bytes using only 32-bit registers. byte from address key+i we store into EDI
movzx edi, BYTE PTR [ecx+esi];;edi=key[i]
mov ebx, eax ; EBX = (hash = len)
and ebx, 255 ; EBX = hash & 0xff
; XOR EDI, EBX (EDI=EDI^EBX) - this operation uses all 32 bits of each register
; but other bits (8-31) are cleared all time, so its OK'
; these are cleared because, as for EDI, it was done by MOVZX instruction above
; high bits of EBX was cleared by AND EBX, 255 instruction above (255 = 0xff)
xor edi, ebx;edi=key[i]^(hash&0xff)
; EAX=EAX>>8; bits 24-31 taken "from nowhere" will be cleared
shr eax, 8;eax=len=hash>>8
; EAX=EAX^crctab[EDI*4] - choose EDI-th element from crctab[] table
xor eax, DWORD PTR _crctab[edi*4];eax=(hash>>8)^crctab[(hash&0xff)^key[i]]
inc ecx ; i++
cmp ecx, edx ; i<len ?
jb SHORT $LL3@crc ; yes
pop edi
pop esi
pop ebx
$LN1@crc:
ret 0
_crc ENDP采用优化的方式(/Ox)来编译,这里只列出crc()函数
gcc 4.4.1 -O3编译
public crc
crc proc near
key = dword ptr 8
hash = dword ptr 0Ch
push ebp
xor edx, edx;edx=i;i=0
mov ebp, esp
push esi
mov esi, [ebp+key];esi=key
push ebx
mov ebx, [ebp+hash];ebx=hash
test ebx, ebx
mov eax, ebx;eax=ebx=hash
jz short loc_80484D3;ebx=0?
nop ; padding
lea esi, [esi+0] ; padding; works as NOP (ESI does not changing here)
loc_80484B8:
mov ecx, eax ;ecx=hash ; save previous state of hash to ECX
xor al, [esi+edx] ; AL=(hash&0xff)^key[i]
add edx, 1 ; i++
shr ecx, 8 ; ECX=hash>>8
movzx eax, al ; EAX=*(key+i)&0xff
mov eax, dword ptr ds:crctab[eax*4] ; EAX=crctab[EAX]
xor eax, ecx ; hash=EAX^ECX
cmp ebx, edx;len>=i?
ja short loc_80484B8;
loc_80484D3:
pop ebx
pop esi
pop ebp
retn
crc endp
\遇到这种,汇编不算复杂,耐心分析即可
Chap38 网络地址计算
-
IPv4下的TCP/IP地址由4个数字组成,每个数字都在0~255(十进制)之间。所以IPv4的地址可以表示为4字节数据。因此IPv4的主机地址、子网掩码和网络地址都可以表示为一个32位的整数。
-
使用者的角度来看,子网掩码由4位数字组成,写出来大致就是255.255.255.0这类形式的数字。但是网络工程师或者系统管理员更喜欢使用更为紧凑的表示方法,也就是CIDR[1]规范的“/8”“/16”一类的表示方法。CIDR格式的子网掩码从子网掩码的MSB(最高数权位)开始计数,统计子网掩码里面有多少个1并将统计数字转换为10进制数。CIDK规范的掩码 数字空间 可用地址(个) 十进制子网掩码 十六进制子网掩码 /30 4 2 255.255.255.252 fffffffc /29 8 6 255.255.255.248 fffffff8 /28 16 14 255.255.255.240 fffffff0 /27 32 30 255.255.255.224 ffffffe0 /26 64 62 255.255.255.192 ffffffc0 /24 256 254 255.255.255.0 ffffff00 C类网段 /23 512 510 255.255.254.0 fffffe00 /22 1024 1022 255.255.252.0 fffffc00 /21 2048 2046 255.255.248.0 fffff800 /20 4096 4094 255.255.240.0 fffff000 /19 8192 8190 255.255.224.0 ffffe000 /18 16384 16382 255.255.192.0 ffffc000 /17 32768 32766 255.255.128.0 ffff8000 /16 65536 65534 255.255.0.0 ffff0000 B类网段 /8 16777216 16777214 255.0.0.0 ff000000 A类网段
这是一个简单的例子,将子网掩码应用到主机地址
#include <stdio.h>
#include <stdint.h>
uint32_t form_IP (uint8_t ip1, uint8_t ip2, uint8_t ip3, uint8_t ip4)
{
return (ip1<<24) | (ip2<<16) | (ip3<<8) | ip4;
};
void print_as_IP (uint32_t a)
{
printf ("%d.%d.%d.%d\n",
(a>>24)&0xFF,
(a>>16)&0xFF,
(a>>8)&0xFF,
(a)&0xFF);
};
// bit=31..0
uint32_t set_bit (uint32_t input, int bit)
{
return input=input|(1<<bit);
};
uint32_t form_netmask (uint8_t netmask_bits)
{
uint32_t netmask=0;
uint8_t i;
for (i=0; i<netmask_bits; i++)
netmask=set_bit(netmask, 31-i);
return netmask;
};
void calc_network_address (uint8_t ip1, uint8_t ip2, uint8_t ip3, uint8_t ip4, uint8_t netmask_bits)
{
uint32_t netmask=form_netmask(netmask_bits);
uint32_t ip=form_IP(ip1, ip2, ip3, ip4);
uint32_t netw_adr;
printf ("netmask=");
print_as_IP (netmask);
netw_adr=ip&netmask;
printf ("network address=");
print_as_IP (netw_adr);
};
int main()
{
calc_network_address (10, 1, 2, 4, 24); // 10.1.2.4, /24
calc_network_address (10, 1, 2, 4, 8); // 10.1.2.4, /8
calc_network_address (10, 1, 2, 4, 25); // 10.1.2.4, /25
calc_network_address (10, 1, 2, 64, 26); // 10.1.2.4, /26
};msvs 2012 /Ob0优化
1 _ip1$ = 8 ; size = 1
2 _ip2$ = 12 ; size = 1
3 _ip3$ = 16 ; size = 1
4 _ip4$ = 20 ; size = 1
5 _netmask_bits$ = 24 ; size = 1
6 _calc_network_address PROC
7 push edi
8 push DWORD PTR _netmask_bits$[esp]
9 call _form_netmask
10 push OFFSET $SG3045 ; 'netmask='
11 mov edi, eax
12 call DWORD PTR __imp__printf
13 push edi
14 call _print_as_IP
15 push OFFSET $SG3046 ; 'network address='
16 call DWORD PTR __imp__printf
17 push DWORD PTR _ip4$[esp+16]
18 push DWORD PTR _ip3$[esp+20]
19 push DWORD PTR _ip2$[esp+24]
20 push DWORD PTR _ip1$[esp+28]
21 call _form_IP
22 and eax, edi ; network address = host address & netmask
23 push eax
24 call _print_as_IP
25 add esp, 36
26 pop edi
27 ret 0
28 _calc_network_address ENDP- 第22行,
and eax,edi是关键运算,即network address = host address & netmask
``form_IP()`将IP的四个字节转换成一个32位数值
- 给返回值分配一个变量并赋值为0
- 取数权最低的第4个字节,与返回值0进行
or操作即可得到含第4字节信息的32位置 - 取第3个字节,左移8位,以生成0x0000bb00(其中bb就是这步读取的第三字节)这种形式的数值。此后与返回值进行OR/或运算。如果上一步的值如果是0x000000aa的话,在执行OR或操作后,就会得到0x0000bbaa这样的返回值。
- 依此类推。取第2个字节,左移16位,生成0x00cc0000这样一个含有第2字节的32位值,再进行OR/或运算。由于以上一步的返回值应当是0x0000bbaa,因此本次运算的结果会是0x00ccbbaa。
- 同理。取最高位,左移24位,以生成0xdd000000这样一个含有第一字节信息的32位值,再进行OR/或运算。由于上一步的返回值是0x00ccbbaa,因此最终的结果的值就是0xddccbbaa这样的32位值了。
msvs 2012 /Ox
; denote ip1 as "dd", ip2 as "cc", ip3 as "bb", ip4 as "aa".
_ip1$ = 8 ; size = 1
_ip2$ = 12 ; size = 1
_ip3$ = 16 ; size = 1
_ip4$ = 20 ; size = 1
_form_IP PROC
movzx eax, BYTE PTR _ip1$[esp-4]
; EAX=000000dd
movzx ecx, BYTE PTR _ip2$[esp-4]
; ECX=000000cc
shl eax, 8
; EAX=0000dd00
or eax, ecx
; EAX=0000ddcc
movzx ecx, BYTE PTR _ip3$[esp-4]
; ECX=000000bb
shl eax, 8
; EAX=00ddcc00
or eax, ecx
; EAX=00ddccbb
movzx ecx, BYTE PTR _ip4$[esp-4]
; ECX=000000aa
shl eax, 8
; EAX=ddccbb00
or eax, ecx
; EAX=ddccbbaa
ret 0
_form_IP ENDP- 这里进行了优化,与常规过程略有一点不同
- 这个实现过程可以描述为:每个字节都写入到其返回值的最低8个比特位,并且EAX每次左移一个字节,并与其做异或操作,重复4次
print_as_IP()
MSVS 2010 /Ob0
_a$ = 8 ; size = 4
_print_as_IP PROC
mov ecx, DWORD PTR _a$[esp-4]
; ECX=ddccbbaa
movzx eax, cl
; EAX=000000aa
push eax
mov eax, ecx
; EAX=ddccbbaa
shr eax, 8
; EAX=00ddccbb
and eax, 255
; EAX=000000bb
push eax
mov eax, ecx
; EAX=ddccbbaa
shr eax, 16
; EAX=0000ddcc
and eax, 255
; EAX=000000cc
push eax
; ECX=ddccbbaa
shr ecx, 24
; ECX=000000dd
push ecx
push OFFSET $SG3020 ; '%d.%d.%d.%d'
call DWORD PTR __imp__printf
add esp, 20
ret 0
_print_as_IP ENDP- 与上文相反,将一个32位的数值切分称4个字节,只需要将输入的数值分别位移24位,16位,8位,0位
- 这里与非优化过程的区别在于不会重新加载输入值
form_netmask()函数和set_bit()函数
_input$ = 8 ; size = 4
_bit$ = 12 ; size = 4
_set_bit PROC
mov ecx, DWORD PTR _bit$[esp-4]
mov eax, 1
shl eax, cl
or eax, DWORD PTR _input$[esp-4]
ret 0
_set_bit ENDP
_netmask_bits$ = 8 ; size = 1
_form_netmask PROC
push ebx
push esi
movzx esi, BYTE PTR _netmask_bits$[esp+4]
xor ecx, ecx
xor bl, bl
test esi, esi
jle SHORT $LN9@form_netma
xor edx, edx
$LL3@form_netma:
mov eax, 31
sub eax, edx
push eax
push ecx
call _set_bit
inc bl
movzx edx, bl
add esp, 8
mov ecx, eax
cmp edx, esi
jl SHORT $LL3@form_netma
$LN9@form_netma:
pop esi
mov eax, ecx
pop ebx
ret 0
_form_netmask ENDPset_bit()函数的功能十分单一。它将输入值左移既定的比特位,接着将位移运算的结果与输入值进行或OR运算。而后form_mask()函数通过循环语句重复调用set_bit()函数,借助循环控制变量netmask_bits设置子网掩码里数值为1的各个比特位。
Chap39 循环:几个迭代?
多数循环语句只有一个迭代器,但是在汇编层面,一个迭代器也可能对应多个数据实体
例如
#include <stdio.h>
void f(int *a1, int *a2, size_t cnt)
{
size_t i;
// copy from one array to another in some weird scheme
for (i=0; i<cnt; i++)
a1[i*3]=a2[i*7];
};每次迭代都有两次乘法,这是很耗时的计算,如果细看程序代码,可以发现程序中的矩阵的参数是跳跃的,我们能比较容易地不用乘法将它计算出来
msvs 2013 x64
f PROC
; RDX=a1
; RCX=a2
; R8=cnt
test r8, r8 ; cnt==0? exit then
je SHORT $LN1@f
npad 11
$LL3@f:
mov eax, DWORD PTR [rdx];eax=a1
lea rcx, QWORD PTR [rcx+12];a2=a2[i+3]
lea rdx, QWORD PTR [rdx+28];a1=a1[i+7]
mov DWORD PTR [rcx-12], eax;a2=a1
dec r8;r8--
jne SHORT $LL3@f
$LN1@f:
ret 0
f ENDP这里有三个迭代变量,分别是cnt变量,以及两个数列参数,数列参数每次迭代都增加12或者28
可以用C语言重写代码
void f(int *a1, int *a2, size_t cnt)
{
size_t i;
size_t idx1=0; idx2=0;
// copy from one array to another in some weird scheme
for (i=0; i<cnt; i++)
{
a1[idx1]=a2[idx2];
idx1+=3;
idx2+=7;
};
};这个程序可在每次迭代更新3个迭代参数,而不是1个。另外,编译器变相实现了两个乘法操作。
GCC 4.9做的更好,只有两个迭代
; RDI=a1
; RSI=a2
; RDX=cnt
f:
test rdx, rdx ; cnt==0? exit then
je .L1
; calculate last element address in "a2" and leave it in RDX
lea rax, [0+rdx*4]
; RAX=RDX*4=cnt*4
sal rdx, 5
; RDX=RDX<<5=cnt*32
sub rdx, rax
; RDX=RDX-RAX=cnt*32-cnt*4=cnt*28
add rdx, rsi
; RDX=RDX+RSI=a2+cnt*28
.L3:
mov eax, DWORD PTR [rsi]
add rsi, 28
add rdi, 12
mov DWORD PTR [rdi-12], eax
cmp rsi, rdx
jne .L3
.L1:
rep ret- 这里
counter直接没了 - 数组
a2的最后一个参数在循环开始前就已经计算好了(cnt*7) - 循环结束的条件直接是可预先计算的临界索引
重写后的C代码如下
#include <stdio.h>
void f(int *a1, int *a2, size_t cnt)
{
size_t i;
size_t idx1=0; idx2=0;
size_t last_idx2=cnt*7;
// copy from one array to another in some weird scheme
for (;;)
{
a1[idx1]=a2[idx2];
idx1+=3;
idx2+=7;
if (idx2==last_idx2)
break;
};
};INTEL C++ 2011实例
f PROC
; parameter 1: rcx = a1
; parameter 2: rdx = a2
; parameter 3: r8 = cnt
.B1.1:: ; Preds .B1.0
test r8, r8 ;8.14
jbe exit ; Prob 50% ;8.14
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.2:: ; Preds .B1.1
cmp r8, 6 ;8.2
jbe just_copy ; Prob 50% ;8.2
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.3:: ; Preds .B1.2
cmp rcx, rdx ;9.11
jbe .B1.5 ; Prob 50% ;9.11
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.4:: ; Preds .B1.3
mov r10, r8 ;9.11
mov r9, rcx ;9.11
shl r10, 5 ;9.11
lea rax, QWORD PTR [r8*4] ;9.11
sub r9, rdx ;9.11
sub r10, rax ;9.11
cmp r9, r10 ;9.11
jge just_copy2 ; Prob 50% ;9.11
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.5:: ; Preds .B1.3 .B1.4
cmp rdx, rcx ;9.11
jbe just_copy ; Prob 50% ;9.11
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.6:: ; Preds .B1.5
mov r9, rdx ;9.11
lea rax, QWORD PTR [r8*8] ;9.11
sub r9, rcx ;9.11
lea r10, QWORD PTR [rax+r8*4] ;9.11
cmp r9, r10 ;9.11
jl just_copy ; Prob 50% ;9.11
; LOE rdx rcx rbx rbp rsi rdi r8 r12 r13 r14 r15 xmm6 xmm7 xmm8 ↙
↘ xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
just_copy2:: ; Preds .B1.4 .B1.6
; R8 = cnt
; RDX = a2
; RCX = a1
xor r10d, r10d ;8.2
xor r9d, r9d ;
xor eax, eax ;
; LOE rax rdx rcx rbx rbp rsi rdi r8 r9 r10 r12 r13 r14 r15 xmm6 xmm7 ↙
↘ xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.8:: ; Preds .B1.8 just_copy2
mov r11d, DWORD PTR [rax+rdx] ;3.6
inc r10 ;8.2
mov DWORD PTR [r9+rcx], r11d ;3.6
add r9, 12 ;8.2
add rax, 28 ;8.2
cmp r10, r8 ;8.2
jb .B1.8 ; Prob 82% ;8.2
jmp exit ; Prob 100% ;8.2
; LOE rax rdx rcx rbx rbp rsi rdi r8 r9 r10 r12 r13 r14 r15 xmm6 xmm7 ↙
↘ xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
just_copy:: ; Preds .B1.2 .B1.5 .B1.6
; R8 = cnt
; RDX = a2
; RCX = a1
xor r10d, r10d ;8.2
xor r9d, r9d ;
xor eax, eax ;
; LOE rax rdx rcx rbx rbp rsi rdi r8 r9 r10 r12 r13 r14 r15 xmm6 ↙
↘ xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
.B1.11:: ; Preds .B1.11 just_copy
mov r11d, DWORD PTR [rax+rdx] ;3.6
inc r10 ;8.2
mov DWORD PTR [r9+rcx], r11d ;3.6
add r9, 12 ;8.2
add rax, 28 ;8.2
cmp r10, r8 ;8.2
jb .B1.11 ; Prob 82% ;8.2
; LOE rax rdx rcx rbx rbp rsi rdi r8 r9 r10 r12 r13 r14 r15 xmm6 ↙
↘ xmm7 xmm8 xmm9 xmm10 xmm11 xmm12 xmm13 xmm14 xmm15
exit:: ; Preds .B1.11 .B1.8 .B1.1
ret ;10.1- 上述程序首先根据输入参数确定分支,接着执行相应的例程。虽然它看起来就像是检查数组交叉分叉,但是编译器采用的是一种非常著名的内存块复制例程(其实每块实现的功能貌似是一样的,但是实现方法不太一样,这里计算了概率)的优化方法。仔细分析就会发现,它所复制的例程居然完全相同。这或许是Intel C++编译器的某种不足吧。然而无论怎样,最后生成的程序功能正常。
- 虽然很复杂,但是还是能实现功能(基本上只用分析一个块就能大概知道功能了)
Chap40 达夫装置
达夫装置是一种综合了多种控制语句的循环展开技术,可大幅度地减少代码的分支总数。
这种循环展开技术巧妙地利用了swtich语句的滑梯(fallthrough)效应。
本章对Tom Duff的原始程序进行了轻度简化。
现在假设我们要编写一个清除一块连续内存的函数。当然,我们可以使用循环语句、逐个字节的复写数据。但是现代的计算机内存总线都很宽,以字节为单位地清除效率会非常低。若以4字节或8字节为操作单位进行io操作,那么操作效率会高一些。由于本例演示的是64位应用程序,所以我们就以8字节为单位进行操作,不过,我们又当如何应对那些不足8字节的内存空间?毕竟我们的函数也可能清除容量不足8字节的内存空间
合理的算法
- 首先统计目标空间含有多少个连续的8字节空间,继而以8字节为操作单位将其清除
- 然后统计那些大小不足8字节的尾数,即上一步除法计算的余数,然后逐字节地将之清零
#include <stdint.h>
#include <stdio.h>
void bzero(uint8_t* dst, size_t count)
{
int i;
if (count&(~7))
// work out 8-byte blocks
for (i=0; i<count>>3; i++)
{
*(uint64_t*)dst=0;
dst=dst+8;
};
// work out the tail
switch(count & 7)
{
case 7: *dst++ = 0;
case 6: *dst++ = 0;
case 5: *dst++ = 0;
case 4: *dst++ = 0;
case 3: *dst++ = 0;
case 2: *dst++ = 0;
case 1: *dst++ = 0;
case 0: // do nothing
break;
}
}- 第一部分比较简单,就是用64位的零填充所有8字节的内存块
- 第二部分的难点在于其循环展开技术,利用了
Switch函数的滑梯效应,功能就是将变量count与数字7进行逻辑与运算,得到尾数,然后把他们逐个清零。如果尾数为0,那么直接跳转至函数尾声 - 达夫装置就是循环展开技术的一种特例。在老式设备上,它显然比普通循环的运行速度更高。然而,对于现代的大多数CPU来说,一些体积短小的循环语句反而会比循环展开体的执行速度更快。也许对于目前低成本的嵌入式MCU(微控单元,例如单片机)处理器而言,达夫设备更有意义一些。
Optimizing msvs 2012
dst$ = 8
count$ = 16
bzero PROC
test rdx, -8;rdx=count;&(~7)后设置标志位
je SHORT $LN11@bzero
; work out 8-byte blocks
xor r10d, r10dl;r10=0
mov r9, rdx;r9==count
shr r9, 3;r9=count>>3
mov r8d, r10d;r8d:i=0
test r9, r9;if count ==0 ?
je SHORT $LN11@bzero
npad 5
$LL19@bzero:
inc r8d;i++
mov QWORD PTR [rcx], r10
add rcx, 8;rcx:dst+8
movsxd rax, r8d;rax
cmp rax, r9;if i == count ?
jb SHORT $LL19@bzero n? jmp
$LN11@bzero:
; work out the tail
and edx, 7
dec rdx
cmp rdx, 6
ja SHORT $LN9@bzero
lea r8, OFFSET FLAT:__ImageBase
mov eax, DWORD PTR $LN22@bzero[r8+rdx*4]
add rax, r8
jmp rax
$LN8@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN7@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN6@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN5@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN4@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN3@bzero:
mov BYTE PTR [rcx], 0
inc rcx
$LN2@bzero:
mov BYTE PTR [rcx], 0
$LN9@bzero:
fatret 0
npad 1
$LN22@bzero:
DD $LN2@bzero
DD $LN3@bzero
DD $LN4@bzero
DD $LN5@bzero
DD $LN6@bzero
DD $LN7@bzero
DD $LN8@bzero
bzero ENDP-
第一部分与源程序对应
-
第二部分的循环展开体:
switch语句通过转移指令直接跳到合适的位置,由于mov/inc指令对之间没有其他代码,所以switch语句在转移到指定标签后不会越过后续的转移标签,会执行完后续的转移标签 -
另外,我们可以继续优化这个程序,
MOV/INC指令对是占用固定的字节数(3+3=6字节),因此我们可以舍去switch语句的转移表结构,直接跳转到如下地址目前的RIP地址+输入值*6,这样就省掉了从转移表的查询操作,执行速度更快但是对于乘法来说,
6不是一个计算效率高的因子,可能比表查询的转移指令更慢
Chap41 除以9
实例
int f(int a)
{
return a/9;
};msvs x86
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
cdq ; sign extend EAX to EDX:EAX
mov ecx, 9
idiv ecx
pop ebp
ret 0
_f ENDP-
CDQ(Convert Double-word to Quad-word)是一个在x86汇编语言中使用的指令,适用于Intel 80386及后续的处理器。它的主要功能是将
一个32位的带符号双字(Double-word,通常指的是EAX寄存器的内容)扩展为一个64位的带符号Quad-word,用于存储在EDX:EAX寄存器对中,以支持某些需要64位操作的操作,比如除法和一些乘法运算。-
它检查EAX寄存器的最高位(第31位),这是一位标志数字的正负(正数为0,负数为1)。
-
根据EAX的最高位,CDQ会把该位的值复制到EDX寄存器的所有位上。如果EAX的最高位是0,那么EDX会被清零(00000000)。如果EAX的最高位是1(表示一个负数),那么EDX会被填充为FFFFFFFF(所有位都是1),这相当于在数学中对负数进行符号扩展,保持了数值的正确性。
eg. 8----> 0000 1000 -8-----> 1111 1000
-
-
iDIV指令是(带符号的)除法指令。它会从寄存器对EDX:EAX中提取被除数,从ECX寄存器中提取除数。计算结束以后,它把计算结果/商存储在EAX寄存器里,把余数存储在EDX寄存器。除法计算之后,商就位于EAX寄存器里,直接成为f()函数的返回值;因此没有其他值传递的操作。为了通知IDIV指令从EDX:EAX寄存器对中提取64位被除数·,为了通知IDIV从EDX:EAX寄存器对中提取64位被除数,编译器在IDIV指令之前分配了CDQ指令。IDIV指令就会进行MOVSX那样的符号位处理和数据拓展处理
开启优化后
_a$ = 8 ; size = 4
_f PROC
mov ecx, DWORD PTR _a$[esp-4]
mov eax, 954437177 ; 38e38e39H
imul ecx
sar edx, 1
mov eax, edx
shr eax, 31 ; 0000001fH
add eax, edx
ret 0
_f ENDPsar指令代表 “Shift Arithmetic Right”,即算术右移。这是一个用于处理带符号整数的数据移动操作。当执行sar指令时- 编译器用乘法指令来变相实现除法运算(乘法的效率高于除法)(这个是有相应的转换公式的)
在编译优化中,我们常常将其称为"强度减轻"的办法
原理
引入2的n次方之后,除法运算可转换为乘法运算:
-
这里的
M是魔术因子(Magic coefficient) -
除以2n的运算可以直接通过右移操作实现。如果n小于32,那么中间运算的积的低n位,通常位于EAX或RAX寄存器就会被位移运算直接抹去;如果n大于或等于32,那么积的高半部分(通常位于EDX或者RDX寄存器)的数值都会受到影响。
-
可见,参数n的取值直接决定了转换运算的计算精度。
-
在进行有符号数的除法运算时,符号位也对计算精度及n的取值产生了显著影响。
例如:
int f3_32_signed(int a)
{
return a/3;
};
unsigned int f3_32_unsigned(unsigned int a)
{
return a/3;
};-
在无符号数的计算过程中,魔术因子是
0xaaaaaaab,乘法的中间结果要除以2的33次方。 -
而在有符号数的计算过程中,魔术因子则是
0x55555556,乘法的中间结果要除以2的32次方。虽然这里没有进行除法运算,但是根据前面的讨论可知:商的有效位取自于EDX寄存器。 -
中间一步的乘法计算同样存在符号位的问题:积的高32位右移31位,将在EAX寄存器的最低数权位保留有符号数的符号位(正数为0,负数为1)。将符号位加入积的高32位值,可实现负数补码的“+1”修正
optimizing msvs 2012
_f3_32_unsigned PROC
mov eax, -1431655765 ; aaaaaaabH
mul DWORD PTR _a$[esp-4] ; unsigned multiply
; EDX=(input*0xaaaaaaab)/2^32
shr edx, 1
; EDX=(input*0xaaaaaaab)/2^33
mov eax, edx
ret 0
_f3_32_unsigned ENDP
_f3_32_signed PROC
mov eax, 1431655766 ; 55555556H
imul DWORD PTR _a$[esp-4] ; signed multiply
; take high part of product
; it is just the same as if to shift product by 32 bits right or to divide it by 2^32
mov eax, edx ; EAX=EDX=(input*0x55555556)/2^32
shr eax, 31 ; 0000001fH
add eax, edx ; add 1 if sign is negative
ret 0
_f3_32_signed ENDP- EAX乘立即数后,高位存储在
EDX,低位存储在EAX中 - EDX
中的值近似等于(input * 0xAAAAAAAB) >> 32 Why? - 常数
0xAAAAAAAB(即-1431655765)是一个特别设计的数,它在二进制表示上具有特定的性质,使得当它与一个32位无符号整数相乘时,其乘积的高32位能够提供该整数倒数的一个近似值。具体来说,这个数被设计用来配合32位整数的乘法运算,产生一个高位包含目标倒数信息的结果。 - 也就是说
EAX的值与aaaaaaabH相乘,产生的高位信息存储在EDX寄存器中,而这个高位信息包含了除数倒数的信息
More
其实,我们都知道,乘法和除法互为逆运算。因此下面的除法可以用乘法来代替。我们可以表述为
x/c=x*(1/c)
1/c可以称为乘法的逆运算,是c的倒数。可以用编译器来做提前运算。
mov eax, MAGICAL CONSTANT
imul input value
sar edx, SHIFTING COEFFICIENT ; signed division by 2xusing arithmetic shift right ;已经位移了32位后,又移动了多少位称为变位系数
mov eax, edx
shr eax, 31
add eax, edx我们如果根据这个变位系数求解除数呢?
-
记变位系数为
C,除数记为D除数可以表示为
-
例如
mov eax, 2021161081 ; 78787879H imul DWORD PTR _a$[esp-4] sar edx, 3 mov eax, edx shr eax, 31 ; 0000001fH add eax, edx利用公式可以计算除数得:
取整为17,除数就是17
-
类似的,在64位数据的除法运算中,只是不再采用2的32次方,而采用了2的64次方
uint64_t f1234(uint64_t a) { return a/1234; };f1234 PROC mov rax, 7653754429286296943 ; 6a37991a23aead6fH mul rcx shr rdx, 9 mov rax, rdx ret 0 f1234 ENDP
Chap42 str2num,atoi()函数
本章重新实现了标准的C函数atoi(),将字符串转换为整数
exmaple1
#include <stdio.h>
int my_atoi (char *s)
{
int rt=0;
while (*s)
{
rt=rt*10 + (*s-'0');
s++;
};
return rt;
};
int main()
{
printf ("%d\n", my_atoi ("1234"));
printf ("%d\n", my_atoi ("1234567890"));
};- 这个算法实现的是从左到右读取数字,并将每个读取的字符减去数字0的ASCII值,再乘以权值
optimizing msvs x64
my_atoi PROC
; 加载第一个字符到 R8D 寄存器中
movzx r8d, BYTE PTR [rcx] ; 把rcx指向的字节扩展为双字放入r8d
; EAX 用于存放结果(初始为0)
xor eax, eax ; 将eax清零,作为累加结果的起始值
; 检查第一个字符是否为字符串结束符(空字符)
test r8b, r8b ; 测试r8b是否为0
je SHORT $LN9@my_atoi ; 如果是,跳转到结束标签,因为没有有效数字
$LL2@my_atoi: ; 循环开始标签
; 计算当前结果的五倍(为后续与新数字相加做准备)
lea edx, DWORD PTR [rax+rax*4] ; edx = eax * 5
; 把下一个字符加载到 R8D 中
movzx r8d, BYTE PTR [rcx+1] ; 取下一个字节并扩展为双字放入r8d
; 指针 RCX 移动到字符串的下一个字符
lea rcx, QWORD PTR [rcx+1] ; rcx 指向下一个字符
; 结果(eax)加上新读取字符的值(转换为数字,减去'0'的ASCII码48)
lea eax, DWORD PTR [rax+rdx*2] ; eax = eax + edx * 2,这里实际是eax = rt * 10 + input_char
add eax, -48 ; 把字符转换为数字(减去'0'的ASCII值)
; 检查是否到达字符串末尾
test r8b, r8b ; 再次测试r8b,看是否为0
jne SHORT $LL2@my_atoi ; 不是则跳回循环开始继续处理
$LN9@my_atoi: ; 循环结束标签
; 函数返回,结果在EAX中
ret 0 ; 返回,不带参数
my_atoi ENDP某些情况下,MSVC编译器会刻意避开减法运算的SUB指令、转而分配“ADD某个负数”的指令来实现减法运算。
my_atoi:
; load input character into EDX
movsx edx, BYTE PTR [rdi]
; EAX is allocated for "rt" variable
xor eax, eax
; exit, if loaded character is null byte
test dl, dl
je .L4
.L3:
lea eax, [rax+rax*4]
; EAX=RAX*5=rt*5
; shift pointer to the next character:
add rdi, 1
lea eax, [rdx-48+rax*2]
; EAX=input character - 48 + RAX*2 = input character - '0' + rt*10
; load next character:
movsx edx, BYTE PTR [rdi]
; goto loop begin, if loaded character is not null byte
test dl, dl
jne .L3
rep ret
.L4:
rep retexample2
#include <stdio.h>
int my_atoi (char *s)
{
int negative=0;
int rt=0;
if (*s=='-')
{
negative=1;
s++;
};
while (*s)
{
if (*s<'0' || *s>'9')
{
printf ("Error! Unexpected char: '%c'\n", *s);
exit(0);
};
rt=rt*10 + (*s-'0');
s++;
};
if (negative)
return -rt;
return rt;
};
int main()
{
printf ("%d\n", my_atoi ("1234"));
printf ("%d\n", my_atoi ("1234567890"));
printf ("%d\n", my_atoi ("-1234"));
printf ("%d\n", my_atoi ("-1234567890"));
printf ("%d\n", my_atoi ("-a1234567890")); // error
};- 添加了转换负数的功能
optimizing gcc x64
.LC0:
.string "Error! Unexpected char: '%c'\n"
my_atoi:
sub rsp, 8
movsx edx, BYTE PTR [rdi]
; check for minus sign
cmp dl, 45 ; '-'
je .L22
xor esi, esi
test dl, dl
je .L20
.L10:
; ESI=0 here if there was no minus sign and 1 if it was
lea eax, [rdx-48]
; any character other than digit will result unsigned number greater than 9 after subtraction
; so if it is not digit, jump to L4, where error will be reported:
cmp al, 9
ja .L4
xor eax, eax
jmp .L6
.L7:
lea ecx, [rdx-48]
cmp cl, 9
ja .L4
.L6:
lea eax, [rax+rax*4]
add rdi, 1
lea eax, [rdx-48+rax*2]
movsx edx, BYTE PTR [rdi]
test dl, dl
jne .L7
; if there was no minus sign, skip NEG instruction
; if it was, execute it.
test esi, esi
je .L18
neg eax
.L18:
add rsp, 8
ret
.L22:
movsx edx, BYTE PTR [rdi+1]
lea rax, [rdi+1];跳过'-'
test dl, dl;'检测是否是''
je .L20
mov rdi, rax
mov esi, 1
jmp .L10
.L20:
xor eax, eax
jmp .L18
.L4:
; report error. character is in EDX
mov edi, 1
mov esi, OFFSET FLAT:.LC0 ; "Error! Unexpected char: '%c'\n"
xor eax, eax
call __printf_chk
xor edi, edi
call exit- 如果字符串的第一个字符是负号,那么就要在转换的最后阶段执行
neg指令,把结果转换为负数 - 编译器对于
if(\*s<'0'||\*s>'9')的处理比较巧妙,这是两个比较操作,但是我们可以只用一个比较指令就能完成这两步比较操作,将输入字符的值减去’0’字符的值,将结果视为无符号数,与9进行比较,如果大于就不符合
这里顺便提一下,安全研究人员经常研究各种异常情况。他们重点关注不合乎预期的输入值,通过这种数据诱使程序进行某种与设计思路相左的行为。因此,他们也会关注模糊测试方法。
Chap43 内联函数
在编译阶段,将会被编译器把函数体展开并嵌入到每一个调用点的函数,就是内联函数。
#include <stdio.h>
int celsius_to_fahrenheit (int celsius)
{
return celsius * 9 / 5 + 32;
};
int main(int argc, char *argv[])
{
int celsius=atol(argv[1]);
printf ("%d\n", celsius_to_fahrenheit (celsius));
};optimizing gcc 4.8.1
_main:
push ebp
mov ebp, esp
and esp, -16
sub esp, 16
call ___main
mov eax, DWORD PTR [ebp+12]
mov eax, DWORD PTR [eax+4]
mov DWORD PTR [esp], eax
call _atol
mov edx, 1717986919
mov DWORD PTR [esp], OFFSET FLAT:LC2 ; "%d\12\0"
lea ecx, [eax+eax*8]
mov eax, ecx
imul edx
sar ecx, 31
sar edx
sub edx, ecx
add edx, 32
mov DWORD PTR [esp+4], edx
call _printf
leave
ret- 这里利用了41章提到的利用乘法指令实现了除法运算,这个是有符号数
- 这里值得注意的是温度转换函数的函数体被直接展开了,放在了函数printf()的前面
- 这样不需要处理多余的函数调用和返回指令。更快
- 现在具有优化功能的编译器一般都能自动的把小型函数的函数体直接“嵌入”到调用方函数的代码里。当然我们也可以借助关键字“inline”强制编译器进行这种“嵌入”处理。
strcmp
bool is_bool (char *s)
{
if (strcmp (s, "true")==0)
return true;
if (strcmp (s, "false")==0)
return false;
assert(0);
};; 定义两个字符串常量
.LC0: .string "true" ; 字符串 "true"
.LC1: .string "false" ; 字符串 "false"
is_bool: ; 函数入口
.LFB0:
push edi ; 保存edi寄存器
mov ecx, 5 ; 设置比较长度为5("true"的长度)
push esi ; 保存esi寄存器
mov edi, OFFSET FLAT:.LC0 ; edi指向字符串"true"
sub esp, 20 ; 为局部变量分配空间
mov esi, DWORD PTR [esp+32] ; esi指向待检查的输入字符串
; 比较输入字符串与"true"
repz cmpsb ; 比较ecx个字节,直到发现差异或ecx减到0
je .L3 ; 如果字符串匹配(即输入为"true"),跳转到.L3
; 如果没匹配"true",则尝试匹配"false"
mov esi, DWORD PTR [esp+32] ; 重置esi指向输入字符串
mov ecx, 6 ; 设置比较长度为6("false"的长度)
mov edi, OFFSET FLAT:.LC1 ; edi指向字符串"false"
repz cmpsb ; 再次比较
; 使用seta和setb设置cl和dl,用于后续逻辑判断
seta cl ; 如果edi("false")在前面,cl=1;否则cl=0
setb dl ; dl总是设为1,因为setb总是设置位为1
xor eax, eax ; eax清零
cmp cl, dl ; 比较cl和dl
jne .L8 ; 如果cl不等于dl(意味着输入既不是"true"也不是"false"),跳转到.L8
.L8: ; 输入不符合预期,调用assert断言失败
mov DWORD PTR [esp], 0 ; 准备assert的第一个参数(通常为0)
call assert ; 调用assert函数
add esp, 20 ; 释放局部变量空间
pop esi ; 恢复esi
pop edi ; 恢复edi
ret ; 返回,表示错误
.L3: ; 输入字符串为"true"
add esp, 20 ; 释放局部变量空间
mov eax, 1 ; 设置eax为1,表示true
pop esi ; 恢复esi
pop edi ; 恢复edi
ret ; 返回,表示成功seta即set above.根据之前指令执行的结果设置寄存器的值。例如,在某些处理器的汇编语言中,seta可能意味着如果先前的比较指令结果是大于(Above),则设置某个寄存器的最低位为1(真),否则为0(假)。但这并不是标准的 x86 汇编指令集的一部分。SETB是汇编语言中的指令,用于设置(Set)一个比特位(Bit)为1。这个指令通常依据某些条件执行,比如在条件转移指令之后,根据处理器的状态标志(如Zero Flag, Carry Flag等)来决定是否设置目标位置的比特位。REPZ是 x86 汇编语言中的一个前缀指令,它是REPE(Repeat While Equal,当 ZF 标志位为1时重复)的同义词。在配合某些指令(如CMPSB、CMPSW、CMPSD、CMPSQ等)使用时,它会根据 Zero Flag (ZF) 的状态来控制循环的执行。CMPSB指令会比较EDI和ESI所指向的字节是否相等,并更新相关标志位(包括ZF,即零标志位,如果两个字节相等则ZF被置为1,否则为0)。REPZ会检查ZF标志位,如果ZF为1(即前一次比较结果为相等),则继续执行下一次比较,同时自动递减ECX寄存器(作为循环计数器)。- 循环会一直执行,直到ECX减到0或者ZF变为0(即遇到不相等的字节)为止。
这里的strcmp被展开了
msvs 2010 optimizing
$SG3454 DB 'true', 00H
$SG3456 DB 'false', 00H
_s$ = 8 ; size = 4
?is_bool@@YA_NPAD@Z PROC ; is_bool
push esi
mov esi, DWORD PTR _s$[esp];esi: address of s
mov ecx, OFFSET $SG3454 ; 'true';ecx:address of true
mov eax, esi;eax=esi eax:s
npad 4 ; align next label
$LL6@is_bool:
mov dl, BYTE PTR [eax];dl:s[i];比较第一个字符
cmp dl, BYTE PTR [ecx];s[i]==true[i]?
jne SHORT $LN7@is_bool
test dl, dl
je SHORT $LN8@is_bool;匹配成功
mov dl, BYTE PTR [eax+1];比较第二个字符
cmp dl, BYTE PTR [ecx+1]
jne SHORT $LN7@is_bool
add eax, 2;跳到两个以后
add ecx, 2
test dl, dl;再次处理空字符
jne SHORT $LL6@is_bool;进入下一次循环
$LN8@is_bool:;匹配成功
xor eax, eax
jmp SHORT $LN9@is_bool
$LN7@is_bool:;结束,跳转到匹配false,设置eax=1
sbb eax, eax;eax=0
sbb eax, -1;eax=1
$LN9@is_bool:
test eax, eax;eax=0?
jne SHORT $LN2@is_bool
mov al, 1
pop esi
ret 0
$LN2@is_bool:;处理false的部分
mov ecx, OFFSET $SG3456 ; 'false'
mov eax, esi
$LL10@is_bool:
mov dl, BYTE PTR [eax]
cmp dl, BYTE PTR [ecx]
jne SHORT $LN11@is_bool;如果匹配失败
test dl, dl
je SHORT $LN12@is_bool
mov dl, BYTE PTR [eax+1]
cmp dl, BYTE PTR [ecx+1]
jne SHORT $LN11@is_bool
add eax, 2
add ecx, 2
test dl, dl
jne SHORT $LL10@is_bool
$LN12@is_bool:
xor eax, eax
jmp SHORT $LN13@is_bool
$LN11@is_bool:;
sbb eax, eax;eax=0
sbb eax, -1;eax=1
$LN13@is_bool:
test eax, eax
jne SHORT $LN1@is_bool;如果eax!=0
xor al, al
pop esi
ret 0
$LN1@is_bool:;assert(0)
push 11
push OFFSET $SG3458
push OFFSET $SG3459
call DWORD PTR __imp___wassert
add esp, 12
pop esi
ret 0
?is_bool@@YA_NPAD@Z ENDP ; is_bool-
sbb指令代表 “Subtract with Borrow”(带借位减法),是一个算术运算指令。该指令执行时会从两个操作数的差值中再减去借位标志(Carry Flag,简称 CF)的值。借位标志通常用于表示前一个操作是否产生了借位(在无符号数运算中)或进位(在有符号数运算中表示负数溢出)。CF位为1表示有借位或进位,为0表示没有。sbb 1,2其中1是存放结果的目标位置,值会在执行后被更新;2是被减数,值与CF的值一起从1中减去即操作对象1 = 操作对象1 - 操作对象2 - CF -
在本例中:通过这两条指令,对于不同的CF值,将EAX寄存器设置成不同的值:
- CF 为 0:
EAX = 0 - 0 = 0和EAX -(-1) = 0+1 = 1; - CF 为 1:
EAX = 0 - 1 = -1和EAX -(-1) = -1 -(-1)= -1+1 = 0。
- CF 为 0:
-
可以发现这段代码的
strcmp是每两个字符为一组进行处理的
strlen
int strlen_test(char *s1)
{
return strlen(s1);
};_s1$ = 8 ; size = 4
_strlen_test PROC
mov eax, DWORD PTR _s1$[esp-4];eax=s[i]
lea edx, DWORD PTR [eax+1];edx=s[i+1]
$LL3@strlen_tes:
mov cl, BYTE PTR [eax];cl:s[i]
inc eax;eax++
test cl, cl;结束?
jne SHORT $LL3@strlen_tes
sub eax, edx;eax-edx
ret 0
_strlen_test ENDPstrlen并没有专门设置一个变量来计算长度,而是利用了地址计算- 如果读取到了空字符,
eax是s[len+1]的地址,而edx是s[1]的地址,相减恰好是长度
strcpy
void strcpy_test(char *s1, char *outbuf)
{
strcpy(outbuf, s1);
};_s1$ = 8 ; size = 4
_outbuf$ = 12 ; size = 4
_strcpy_test PROC
mov eax, DWORD PTR _s1$[esp-4];eax:s1
mov edx, DWORD PTR _outbuf$[esp-4];edx:outbuf
sub edx, eax;edx=outbuf-s1
npad 6 ; align next label
$LL3@strcpy_tes:
mov cl, BYTE PTR [eax]
mov BYTE PTR [edx+eax], cl
inc eax
test cl, cl
jne SHORT $LL3@strcpy_tes
ret 0
_strcpy_test ENDP- 这里只用了一个指针就实现了
strcpy - 首先计算两个字符串位置的偏移,然后令
s1[ptr+offset]=s1[ptr]从而实现了字符串的复制
memset
-
64字节的操作
在编译那些操作小体积内存块的memset()函数时,多数编译器不会分配标准的函数调用指令(call),反而会分配一堆的MOV指令,直接赋值。
f: mov QWORD PTR [rdi], 0 mov QWORD PTR [rdi+8], 0 mov QWORD PTR [rdi+16], 0 mov QWORD PTR [rdi+24], 0 ret即一次清空8个字节
QWORDquad word 4个word,8个字节 -
67字节的操作
即上文介绍的循环展开技术
#include <stdio.h> void f(char *out) { memset(out, 0, 67); };out$ = 8 f PROC xor eax, eax mov QWORD PTR [rcx], rax mov QWORD PTR [rcx+8], rax mov QWORD PTR [rcx+16], rax mov QWORD PTR [rcx+24], rax mov QWORD PTR [rcx+32], rax mov QWORD PTR [rcx+40], rax mov QWORD PTR [rcx+48], rax mov QWORD PTR [rcx+56], rax mov WORD PTR [rcx+64], ax mov BYTE PTR [rcx+66], al ret 0 f ENDP-
最后的3个字节被分成了一个word和一个byte
-
GCC还会分配REP STOSQ指令。这可能比一堆的MOV赋值指令更短,效率更高。
; 函数开始 f: ; 将 rdi 指向的内存区域的前 8 字节(64 位)置为 0;前8字节清0 mov QWORD PTR [rdi], 0 ; 将 rdi+59 处的 8 字节(64 位)置为 0 mov QWORD PTR [rdi+59], 0 ;后8字节清零 ; 将 rdi 的值复制到 rcx mov rcx, rdi ;rcx=rdi rdi:第一个字节的地址 ; rdi = rdi + 8,rdi 地址向后移动 8 字节 lea rdi, [rdi+8] ;rdi指向第9个字节 ; 将 eax 清零(eax = 0) xor eax, eax ; rdi 对齐到 8 字节边界,目的是为了处理内存的时候效率更高 and rdi, -8;rdi只可能减少,指向第1~9个字节的某个字节,与8字节对齐 ; 计算并且将 rcx 减去 rdi 的值 sub rcx, rdi ; 将 ecx 的值加上 67 add ecx, 67 ; 将 ecx 右移 3 位,相当于除以 8 shr ecx, 3;计算还要清空多少个8字节 ; 使用 rep stosq 指令,将 rax(值为 0)填充到 rdi 指向的内存,重复 ecx 次 rep stosq;清空,右移... ; 返回调用函数 retREP STOSQ指令是一条 x86 汇编指令,用于在内存中填充一个指定的区域。REP前缀与STOSQ指令结合使用,用来快速地将 RAX 寄存器中的值填充到一个内存区域。- STOSQ:该指令将 RAX 寄存器的值存储到由 RDI 寄存器指向的内存位置,并根据 DF(方向标志,Direction Flag)决定指针的递增或递减。每次将 64 位的 RAX 值存储到内存中。
- REP:
REP前缀用来指示STOSQ指令应重复执行,直到 RCX 寄存器的值变为零。具体来说,REP前缀会对STOSQ指令进行如下操作:- 先检查 RCX 是否为零。如果 RCX 为零,指令结束。
- 将 RAX 的值存储到 RDI 所指向的位置。
- 根据 DF 标志,RDI 递增或递减 8 位。
- 减少 RCX 的值。
- 循环直到 RCX 减到零。
-
memcpy
void memcpy_7(char *inbuf, char *outbuf)
{
memcpy(outbuf+10, inbuf, 7);
};- 在编译那些复制小尺寸内存块的
memcpy()函数时,多数编译器会分配一系列的MOV指令。
msvs optimize
_inbuf$ = 8 ; size = 4
_outbuf$ = 12 ; size = 4
_memcpy_7 PROC
mov ecx, DWORD PTR _inbuf$[esp-4];ecx:inbuf
mov edx, DWORD PTR [ecx];edx:inbuf
mov eax, DWORD PTR _outbuf$[esp-4];eax:outbuf
mov DWORD PTR [eax+10], edx;outbuf+10=inbuf;处理4字节
mov dx, WORD PTR [ecx+4];dx:inbuf->inbuf+4
mov WORD PTR [eax+14], dx;oubuf+14=inbuf+4;处理剩下的2个字节
mov cl, BYTE PTR [ecx+6] ;
mov BYTE PTR [eax+16], cl;处理剩下的一个字节
ret 0
_memcpy_7 ENDPgcc optimize
memcpy_7:
push ebx
mov eax, DWORD PTR [esp+8];eax:arg2,inbuf
mov ecx, DWORD PTR [esp+12];ecx:arg3,outbuf
mov ebx, DWORD PTR [eax];ebx=eax:arg2
lea edx, [ecx+10]
mov DWORD PTR [ecx+10], ebx
movzx ecx, WORD PTR [eax+4]
mov WORD PTR [edx+4], cx
movzx eax, BYTE PTR [eax+6]
mov BYTE PTR [edx+6], al
pop ebx
ret- 首先复制4个字节
- 再复制2个字节
- 最后复制1个字节
- 编译器还会通过赋值指令MOV复制结构体(structure)型数据。
- 大尺寸内存块的操作:不同的编译器会有不同的指令分配方案。
void memcpy_128(char *inbuf, char *outbuf)
{
memcpy(outbuf+10, inbuf, 128);
};
void memcpy_123(char *inbuf, char *outbuf)
{
memcpy(outbuf+10, inbuf, 123);
};optimize msvs
MSVC分配了单条MOVSD指令。在循环控制变量ECX的配合下,MOVSD可一步完成128个字节的数据复制。其原因显然是128能被4整除。
_inbuf$ = 8 ; size = 4
_outbuf$ = 12 ; size = 4
_memcpy_128 PROC
push esi
mov esi, DWORD PTR _inbuf$[esp]
push edi
mov edi, DWORD PTR _outbuf$[esp+4]
add edi, 10
mov ecx, 32
rep movsd
pop edi
pop esi
ret 0
_memcpy_128 ENDP这里rep movsd联用
-
rep 是一个前缀指令,指示CPU重复执行紧跟其后的指令,直到CX(16位和32位模式)或RCX(64位模式)寄存器的值减到零。在执行过程中,CX/RCX的值会在每次迭代后自动减1。
-
movsd 是“move double word”的缩写,它将DS段寄存器指向的源地址(ESI/RSI)中的一个双字(4字节)数据复制到ES段寄存器指向的目标地址(EDI/RDI)。在复制之后,根据方向标志(DF)的状态,ESI/RSI和EDI/RDI会自动递增(如果DF为0)或递减(如果DF为1),默认情况下,大多数字符串操作前会先执行
cld指令来清零DF,确保地址向前递增。 -
在复制123个字节的程序里,编译器首先通过MOVSD指令复制30个32字节(也就是120字节),然后依次通过MOVSW指令和MOVSB指令复制2个字节和1个字节。
_inbuf$ = 8 ; size = 4
_outbuf$ = 12 ; size = 4
_memcpy_123 PROC
push esi
mov esi, DWORD PTR _inbuf$[esp]
push edi
mov edi, DWORD PTR _outbuf$[esp+4]
add edi, 10
mov ecx, 30
rep movsd
movsw
movsb
pop edi
pop esi
ret 0
_memcpy_123 ENDPGCC
GCC则分配了一个大型的通用的函数。这个函数适用于任意大小的内存块复制操作。
; memcpy_123 函数开始
.LFB3:
; 保存edi和esi寄存器,因为它们将被用于数据复制
push edi
push esi
; 设置一个计数器eax = 123,用于控制复制或其他操作的循环
mov eax, 123
; 获取目标地址(edx)和源地址(esi)从栈中
mov edx, DWORD PTR [esp+16] ; 目标地址
mov esi, DWORD PTR [esp+12] ; 源地址
; 调整目标地址edi,预先增加10字节偏移
lea edi, [edx+10]
; 检查目标地址edi是否为奇数或偶数对齐,以便进行相应的对齐处理
test edi, 1 ; 检查奇数对齐
jne .L24 ; 不是偶数对齐则跳转处理
test edi, 2 ; 检查4字节对齐
jne .L25 ; 不是4字节对齐则跳转处理
.L7: ; 主复制循环开始
; 计算需要复制的双字(4字节)数量,并清除edx准备作为计数器
mov ecx, eax
xor edx, edx
shr ecx, 2 ; 将eax除以4,得到双字数量
; 复制双字数据,如果有剩余字节则单独处理
test al, 2 ; 检查是否有需要处理的剩余2字节
rep movsd ; 批量复制双字
je .L8 ; 如果没有剩余字节,跳转到结尾
; 处理剩余的2字节数据
movzx edx, WORD PTR [esi]
mov WORD PTR [edi], dx
mov edx, 2
.L8: ; 检查并处理单字节对齐情况
test al, 1 ; 检查是否有需要处理的剩余1字节
je .L5 ; 如果没有剩余字节,跳转到恢复寄存器并返回
; 处理最后一个字节
movzx eax, BYTE PTR [esi+edx]
mov BYTE PTR [edi+edx], al
.L5: ; 恢复esi和edi寄存器
pop esi
pop edi
; 函数返回
ret
; 以下为对齐处理分支
.L24:
; 对目标地址edi为奇数时的特殊处理
...
.L25:
; 对目标地址edi为非4字节对齐时的特殊处理
...
.LFE3: ; 函数结束标签通用内存复制函数通常的工作原理如下:首先计算块有多少个字(32位),然后用MOVSD指令复制这些内存块,然后逐一复制剩余的字节。
更为复杂的内存复制函数则会利用SIMD指令集进行复制,这种复制还会涉及内存地址对齐的问题。
memcmp
void memcpy_1235(char *inbuf, char *outbuf)
{
memcmp(outbuf+10, inbuf, 1235);
};无论内存块的尺寸是多大,MSVC 2010都会插入相同的通用比较函数。
; 定义输入参数位置
_buf1$ = 8 ; _buf1$位于栈上的位置,大小为4字节
_buf2$ = 12 ; _buf2$位于栈上的位置,大小为4字节
_memcmp_1235 PROC
; 加载缓冲区2的地址到edx
mov edx, DWORD PTR _buf2$[esp-4]
; 加载缓冲区1的地址到ecx
mov ecx, DWORD PTR _buf1$[esp-4]
; 保存edi和esi,为后续使用准备
push esi
push edi
; 初始化计数器esi为1235
mov esi, 1235
; 目标缓冲区地址预偏移10字节
add edx, 10
$LL4@memcmp_123: ; 主循环开始
; 比较当前位置的双字(4字节)
mov eax, DWORD PTR [edx] ; eax = *buf2 + 10
cmp eax, DWORD PTR [ecx] ; 比较eax和*buf1
jne SHORT $LN10@memcmp_123 ; 若不同,跳转到差异处理
; 如果相等,计数器递减,指针前进
sub esi, 4
add ecx, 4
add edx, 4
; 检查计数器是否大于等于4,若小于则结束循环
cmp esi, 4
jae SHORT $LL4@memcmp_123
$LN10@memcmp_123: ; 发现差异后的处理
; 比较剩余字节,逐字节比较直到找到差异或结束
movzx edi, BYTE PTR [ecx] ; 比较第一个字节
movzx eax, BYTE PTR [edx]
sub eax, edi
jne SHORT $LN7@memcmp_123
movzx eax, BYTE PTR [edx+1] ; 比较第二个字节
movzx edi, BYTE PTR [ecx+1]
sub eax, edi
jne SHORT $LN7@memcmp_123
movzx eax, BYTE PTR [edx+2] ; 比较第三个字节
movzx edi, BYTE PTR [ecx+2]
sub eax, edi
jne SHORT $LN7@memcmp_123
; 如果esi不小于3,说明至少比较了4字节,比较第四个字节
cmp esi, 3
jbe SHORT $LN6@memcmp_123
movzx eax, BYTE PTR [edx+3]
movzx ecx, BYTE PTR [ecx+3]
sub eax, ecx
$LN7@memcmp_123: ; 结果处理
sar eax, 31 ; 设置结果正负(通过移位实现)
pop edi
or eax, 1 ; 确保结果非零
pop esi
ret 0 ; 返回结果
$LN6@memcmp_123: ; 未发现差异,所有已检查字节均相同
pop edi
xor eax, eax ; eax = 0,表示无差异
pop esi
ret 0 ; 返回0,表示两个缓冲区内容相同
_memcmp_1235 ENDPChap44 C99标准的受限指针
-
什么是受限指针?
restrict是 C99 标准引入的一种类型限定符,用于指针声明中。它告诉编译器,一个指针是唯一访问某一对象的方式。这一限定符提供了更多的优化机会,尤其是对编译器而言,因为它消除了指针别名(pointer aliasing)的可能性。示例与解释
考虑一种情况,我们希望对两个数组进行元素相加:
void add_arrays(int *a, int *b, int *c, size_t n) { for (size_t i = 0; i < n; ++i) { c[i] = a[i] + b[i]; } }假设函数调用时
a、b和c可能指向同一内存区域的一部分。编译器在这种情况下必须很谨慎地生成代码,因为它无法确定内存区域是否重叠。使用
restrict通过使用
restrict,我们告诉编译器,每一个指针都分别指向不同的内存区域。这将允许编译器进行更积极的优化,从而提高性能:void add_arrays(int *restrict a, int *restrict b, int *restrict c, size_t n) { for (size_t i = 0; i < n; ++i) { c[i] = a[i] + b[i]; } }上述代码表示:
a指针指向的内存、不被b和c指向,b指针指向的内存、不被a和c指向,c指针指向的内存也不被a和b指向。作用
- 消除指针别名问题:通过
restrict,编译器能够确定这些指针不会指向重叠的内存区域。这减少了内存访问的复杂性。 - 提升优化机会:在没有
restrict的情况下,编译器必须假设这些指针可能指向同一个内存区域,这会降低优化的机会。而使用restrict之后,编译器可以更好地进行优化,比如在寄存器中缓存值等。
需要注意的地方
- 合法性约束:作为程序员,在使用
restrict时,必须保证这些指针确实指向不同的内存区域,否则会导致未定义行为。 - 应用场景:适用于那些性能敏感且确定指针不会重叠的场景。
总结
restrict关键字提供了一种方法,让程序员能够明确地告诉编译器指针的使用约束,这样编译器可以进行更激进的优化,从而提高程序的性能。但这也需要程序员遵循其约定,否则可能带来不可预见的问题。 - 消除指针别名问题:通过
void f1 (int* x, int* y, int* sum, int* product, int* sum_product, int* update_me, size_t s)
{
for (int i=0; i<s; i++)
{
sum[i]=x[i]+y[i];
product[i]=x[i]*y[i];
update_me[i]=i*123; // some dummy value
sum_product[i]=sum[i]+product[i];
};
};这个程序的功能十分简单,但是里面的指针问题却发人深思:同一块内存可以由多个指针来访问,因此同一个地址的数据可能会被多个指针轮番复写。
C语言编译器完全允许上述情况。因此,它分四个阶段处理每次迭代的各类数组:
- 制备sum[i];
- 制备product[i];
- 制备update_me[i];
- 制备sum_product[i]。在这个阶段,计算机将从内存里重新加载sum[i]和product[i]。
第四个阶段是否存在进一步优化的空间呢?既然前面已经计算好了sum[i]和product[i],那么后面我们应该就不必再从内存中读取它们的值了。
只是编译器本身并不能在第三个阶段确定前两个阶段的赋值没有被其他指令覆盖。换而言之,因为编译器不能判断该程序里是否存在指向相同内存区域的指针——即“指针别名(pointer aliasing)”,所以编译器不能确保该指针指向的内存没被改写。
C99标准中的受限指针[ISO07,6.7.3节](部分文献又称“严格别名”)的应运而生。编程人员可通过受限指针的strict修饰符向编译器承诺:被该关键字标记的指针是操作相关内存区域的唯一指针,没有其他指针重复指向这个指针所操作的内存区域。
用更为确切、更为正式的语言来说,关键字“restrict”表示该指针是访问既定对象的唯一指针,其他指针都不会重复操作既定对象。从另一个角度来看,一旦某个指针被标记为受限指针,那么编译器就认定既定对象只会被指定的受限指针操作。
void f2 (int* restrict x, int* restrict y, int* restrict sum, int* restrict product, int* ↙
↘ restrict sum_product,
int* restrict update_me, size_t s)
{
for (int i=0; i<s; i++)
{
sum[i]=x[i]+y[i];
product[i]=x[i]*y[i];
update_me[i]=i*123; // some dummy value
sum_product[i]=sum[i]+product[i];
};
};GCC X64 f1
f1:
push r15 r14 r13 r12 rbp rdi rsi rbx
mov r13, QWORD PTR 120[rsp]
mov rbp, QWORD PTR 104[rsp]
mov r12, QWORD PTR 112[rsp]
test r13, r13
je .L1
add r13, 1
xor ebx, ebx
mov edi, 1
xor r11d, r11d
jmp .L4
.L6:
mov r11, rdi
mov rdi, rax
.L4:
lea rax, 0[0+r11*4]
lea r10, [rcx+rax]
lea r14, [rdx+rax]
lea rsi, [r8+rax]
add rax, r9
mov r15d, DWORD PTR [r10]
add r15d, DWORD PTR [r14]
mov DWORD PTR [rsi], r15d ; store to sum[]
mov r10d, DWORD PTR [r10]
imul r10d, DWORD PTR [r14]
mov DWORD PTR [rax], r10d ; store to product[]
mov DWORD PTR [r12+r11*4], ebx ; store to update_me[]
add ebx, 123
mov r10d, DWORD PTR [rsi] ; reload sum[i]
add r10d, DWORD PTR [rax] ; reload product[i]
lea rax, 1[rdi]
cmp rax, r13
mov DWORD PTR 0[rbp+r11*4], r10d ; store to sum_product[]
jne .L6
.L1:
pop rbx rsi rdi rbp r12 r13 r14 r15
retGCC X64 f2
f2:
push r13 r12 rbp rdi rsi rbx
mov r13, QWORD PTR 104[rsp]
mov rbp, QWORD PTR 88[rsp]
mov r12, QWORD PTR 96[rsp]
test r13, r13
je .L7
add r13, 1
xor r10d, r10d
mov edi, 1
xor eax, eax
jmp .L10
.L11:
mov rax, rdi
mov rdi, r11
.L10:
mov esi, DWORD PTR [rcx+rax*4]
mov r11d, DWORD PTR [rdx+rax*4]
mov DWORD PTR [r12+rax*4], r10d ; store to update_me[]
add r10d, 123
lea ebx, [rsi+r11]
imul r11d, esi
mov DWORD PTR [r8+rax*4], ebx ; store to sum[]
mov DWORD PTR [r9+rax*4], r11d ; store to product[]
add r11d, ebx
mov DWORD PTR 0[rbp+rax*4], r11d ; store to sum_product[]
lea r11, 1[rdi]
cmp r11, r13
jne .L11
.L7:
pop rbx rsi rdi rbp r12 r13
retf1()函数和f2()函数的不同之处在于:在f1()函数中,sum[i]和product[i]数组在循环中会再次加载;而函数f2()则没有这种重新加载内存数值的操作。在改动后的程序里,因为我们向编译器“承诺”sum[i]和product[i]的值不会被其他指针复写,所以计算机会重复利用前几个阶段制备好的各项数据,不再从内存加载它们的值了。很明显,改进后的程序运行速度更快一些。
如果我们声明了某个指针是受限指针,而实际的程序又有其他指针操作这个受限指针操作的内存区域,将会发生什么情况?这真的就是程序员的事了,不过程序运行的结果肯定是错误的。
FORTRAN语言的编译器把所有指针都视为受限指针。因此,在C语言不支持C99标准的restrict修饰符而实际指针属于受限指针的时候,用FORTRAN语言编译出来的应用程序会比用C语言编译出来的程序运行得更快。
受限指针主要用于哪些领域?它主要用于操作多个大尺寸内存块的应用方面。例如,在超级计算机/HPC平台上经常进行的线性方程组求解就属于这种类型的应用。或许,这正是这种平台普遍采用FORTRAN语言的原因之一吧。
另一方面,在循环语句的迭代次数不是非常高的情况下,受限指针带来的性能提升就不会十分明显。
Chap45 打造无分支的abs()函数
int my_abs (int i)
{
if (i<0)
return -i;
else
return i;
};回顾第12章,我们可以用x86汇编指令打造一个无分支的版本
x64 gcc optimizing
my_abs:
mov edx, edi;edx=edi:i
mov eax, edi;eax=edi:i
sar edx, 31
; EDX is 0xFFFFFFFF here if sign of input value is minus
; EDX is 0 if sign of input value is plus (including 0)
; the following two instructions have effect only if EDX is 0xFFFFFFFF
; or idle if EDX is 0
xor eax, edx
sub eax, edx
retsar算术右移:算术右移31位,算术右移是带符号的操作,有符号数的最高有效位MSB就是其符号位。也就是说如果源操作数是负数,那么右移31位后得到的结果都会是0xffffffff- 当输入值是负数的时候,相当于
xor,0xffffffff,相当于逐位求非的非运算,而后面的sub指令完成了补码运算(因为此时edx的值是-1)
Chap46 变长参数函数
本章探究像printf和scanf一类的函数可以处理多个参数,这类函数是如何访问参数的
计算算术平均值
如果要编写一个计算算术平均值的函数,那么就需要在函数的参数声明部分指定所有的外来参数。但是C/C++的变长参数函数却无法事先知道外来参数的数量。为了方便起见,我们用“-1”作为最后一个参数兼其他参数的终止符。
C语言标准函数库的头文件stdarg.h定义了变长参数的处理方法(宏)。刚才提到的printf()函数和scanf()函数都使用了这个文件提供的宏。
#include <stdio.h>
#include <stdarg.h>
int arith_mean(int v, ...)
{
va_list args;
int sum=v, count=1, i;
va_start(args, v);
while(1)
{
i=va_arg(args, int);
if (i==-1) // terminator
break;
sum=sum+i;
count++;
}
va_end(args);
return sum/count;
};
int main()
{
printf ("%d\n", arith_mean (1, 2, 7, 10, 15, -1 /* terminator */));
};_v$ = 8
_arith_mean PROC NEAR
mov eax, DWORD PTR _v$[esp-4] ; load 1st argument into sum
push esi
mov esi, 1 ; count=1
lea edx, DWORD PTR _v$[esp] ; address of the 1st argument
$L838:
mov ecx, DWORD PTR [edx+4] ; load next argument
add edx, 4 ; shift pointer to the next argument
cmp ecx, -1 ; is it -1?
je SHORT $L856 ; exit if so
add eax, ecx ; sum = sum + loaded argument
inc esi ; count++
jmp SHORT $L838
$L856:
; calculate quotient
cdq
idiv esi;count
pop esi
ret 0
_arith_mean ENDP
$SG851 DB '%d', 0aH, 00H
_main PROC NEAR
push -1
push 15
push 10
push 7
push 2
push 1
call _arith_mean
push eax
push OFFSET FLAT:$SG851 ; '%d'
call _printf
add esp, 32
ret 0
_main ENDP-
CDQ(Convert Doubleword to Quadword)指令,将32位的EAX寄存器中的有符号整数的符号位扩展到64位的EDX:EAX寄存器对中。 -
main()函数里,各项参数从右到左依次逆序传递入栈。第一个入栈的是最后一项参数“-1”,而最后入栈的是第一项参数——格式化字符串。 -
函数
arith_mean()取出第一个参数的值,并将其保存在变量sum中。接着,将第二个参数的地址保存在寄存器EDX中,并取出其值,与前面的sum相加。如此循环往复,直到参数的终止符−1。 -
当找到了参数串的结尾后,程序再将所有数的算术和sum除以参数的个数(当然不包括终止符−1)。按照这种算法计算出来的商就是各参数的算术平均值。
-
==换句话说,在调用变长参数函数时,调用方函数先把不确定长度的参数堆积为数组,再通过栈把这个数组传递给变长函数参数。这就解释了为什么cdecl调用规范会要求将第一个参数最后一个推送入栈了。==因为如果不这样的话,被调用方函数会找不到第一个参数,这会导致printf()这样的函数因为找不到格式化字符串的地址而无法运行。
基于寄存器的调用规范
msvs x64
$SG3013 DB '%d', 0aH, 00H
v$ = 8
arith_mean PROC
mov DWORD PTR [rsp+8], ecx ; 1st argument
mov QWORD PTR [rsp+16], rdx ; 2nd argument
mov QWORD PTR [rsp+24], r8 ; 3rd argument
mov eax, ecx ; sum = 1st argument
lea rcx, QWORD PTR v$[rsp+8] ; pointer to the 2nd argument
mov QWORD PTR [rsp+32], r9 ; 4th argument
mov edx, DWORD PTR [rcx] ; load 2nd argument
mov r8d, 1 ; count=1
cmp edx, -1 ; 2nd argument is -1?
je SHORT $LN8@arith_mean ; exit if so
$LL3@arith_mean:
add eax, edx ; sum = sum + loaded argument
mov edx, DWORD PTR [rcx+8] ; load next argument
lea rcx, QWORD PTR [rcx+8] ; shift pointer to point to the argument after next
inc r8d ; count++
cmp edx, -1 ; is loaded argument -1?
jne SHORT $LL3@arith_mean ; go to loop begin if its not'
$LN8@arith_mean:
; calculate quotient
cdq
idiv r8d
ret 0
arith_mean ENDP
main PROC
sub rsp, 56
mov edx, 2
mov DWORD PTR [rsp+40], -1
mov DWORD PTR [rsp+32], 15
lea r9d, QWORD PTR [rdx+8]
lea r8d, QWORD PTR [rdx+5]
lea ecx, QWORD PTR [rdx-1]
call arith_mean
lea rcx, OFFSET FLAT:$SG3013
mov edx, eax
call printf
xor eax, eax
add rsp, 56
ret 0
main ENDP- 在这个程序中,寄存器负责传递函数的前4个参数,栈用来传递其余的2个参数。函数
arith_mean()首先将寄存器传递的4个参数存放在阴影空间里,把阴影空间和传递参数的栈合并成了统一而连续的参数数组
vprintf()
在编写日志(logging)函数的时候,多数人都会自己构造一种与printf类似的、处理“格式化字符串+一系列(但是数量可变)的内容参数”的变长参数函数。
另外一种常见的变长参数函数就是下文的这种die()函数。这是一种在显示提示信息之后随即退出整个程序的异常处理函数。它需要把不确定数量的输入参数打包、封装并传递给printf()函数。如何实现呢?这些函数名称前面有一个字母v的,这是因为它应当能够处理不确定数量(variable.可变的)的参数。以die()函数调用的vprintf()函数为例,它的输入变量就可分为两部分:一部分是格式化字符串,另一部分是带有多种类型数据变量列表va_list的指针。
#include <stdlib.h>
#include <stdarg.h>
void die (const char * fmt, ...)
{
va_list va;
va_start (va, fmt);
vprintf (fmt, va);
exit(0);
};va_list是一个指向数组的指针。
x64 msvs
_fmt$ = 8
_die PROC
; load 1st argument (format-string)
mov ecx, DWORD PTR _fmt$[esp-4]
; get pointer to the 2nd argument
lea eax, DWORD PTR _fmt$[esp]
push eax ; pass pointer
push ecx
call _vprintf
add esp, 8
push 0
call _exit
$LN3@die:
int 3
_die ENDPdie()函数实现的功能就是:取一个指向参数的指针,再将其传送给vprintf()函数。变长参数(序列)像数组那样被来回传递。
x64 gcc
fmt$ = 48
die PROC
; save first 4 arguments in Shadow Space
mov QWORD PTR [rsp+8], rcx
mov QWORD PTR [rsp+16], rdx
mov QWORD PTR [rsp+24], r8
mov QWORD PTR [rsp+32], r9
sub rsp, 40
lea rdx, QWORD PTR fmt$[rsp+8] ; pass pointer to the 1st argument
; RCX here is still points to the 1st argument (format-string) of die()
; so vprintf() will take it right from RCX
call vprintf
xor ecx, ecx
call exit
int 3
die ENDP与前例类似,rcx指向阴影空间,刚好是va_list的指针
Chap47 字符串剪切
当我们需要去除字符串的开始符号或者结束符号
本章介绍的程序,专门用于去除字符串的结尾部分的回车和换行字符CR/LF
#include <stdio.h>
#include <string.h>
char* str_trim (char *s)
{
char c;
size_t str_len;
// work as long as \r or \n is at the end of string
// stop if some other character there or its an empty string'
// (at start or due to our operation)
for (str_len=strlen(s); str_len>0 && (c=s[str_len-1]); str_len--)
{
if (c=='\r' || c=='\n')
s[str_len-1]=0;
else
break;
};
return s;
};
int main()
{
// test
// strdup() is used to copy text string into data segment,
// because it will crash on Linux otherwise,
// where text strings are allocated in constant data segment,
// and not modifiable.
printf ("[%s]\n", str_trim (strdup("")));
printf ("[%s]\n", str_trim (strdup("\n")));
printf ("[%s]\n", str_trim (strdup("\r")));
printf ("[%s]\n", str_trim (strdup("\n\r")));
printf ("[%s]\n", str_trim (strdup("\r\n")));
printf ("[%s]\n", str_trim (strdup("test1\r\n")));
printf ("[%s]\n", str_trim (strdup("test2\n\r")));
printf ("[%s]\n", str_trim (strdup("test3\n\r\n\r")));
printf ("[%s]\n", str_trim (strdup("test4\n")));
printf ("[%s]\n", str_trim (strdup("test5\r")));
printf ("[%s]\n", str_trim (strdup("test6\r\r\r")));
};msvs x64 optimizing
s$ = 8
str_trim PROC
; RCX is the first function argument and it always holds pointer to the string
; this is strlen() function inlined right here:
; set RAX to 0xFFFFFFFFFFFFFFFF (-1)
or rax, -1
$LL14@str_trim:
inc rax;rax++,rax:0
cmp BYTE PTR [rcx+rax], 0;rcx:s
jne SHORT $LL14@str_trim;检测当前字符是否为空字符串
; is string length zero? exit then
test eax, eax
$LN18@str_trim:
je SHORT $LN15@str_trim;eax=0则exit
; RAX holds string length
; here is probably disassembler (or assembler printing routine) error,
; LEA RDX... should be here instead of LEA EDX...
lea edx, DWORD PTR [rax-1]
; idle instruction: EAX will be reset at the next instructions execution'
mov eax, edx
; load character at address s[str_len-1]
movzx eax, BYTE PTR [rdx+rcx]
; save also pointer to the last character to R8
lea r8, QWORD PTR [rdx+rcx]
cmp al, 13 ; is it '\r'?
je SHORT $LN2@str_trim
cmp al, 10 ; is it '\n'?
jne SHORT $LN15@str_trim
$LN2@str_trim:;将换行等字符替换为0
; store 0 to that place
mov BYTE PTR [r8], 0
mov eax, edx
; check character for 0, but conditional jump is above...
test edx, edx
jmp SHORT $LN18@str_trim
$LN15@str_trim:
; return "s"
mov rax, rcx
ret 0
str_trim ENDP- 首先这段汇编的第一个特征就是
MSVS编译器对字符串长度函数strlen()进行了内联的展开和嵌入处理。编译器认为,内联处理后的执行效率会比常规的函数调用更好 - 内嵌处理之后,
strlen()函数的第一个指令是:OR RAX,0xffffffffffffffff。我们不清楚为何MSVC采用OR(或)指令,而没有采用MOV RAX, 0xffffffffffffffff指令直接赋值。当然,这两条指令执行的是相同操作:将所有位设置为1。因此这个数值就是赋值为−1。(原因是因为初始值为-1,生成的汇编代码会更短)
GCC X64 Non-Optimizing
str_trim:
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
; for() first part begins here
mov rax, QWORD PTR [rbp-24];rax=rdi:s
mov rdi, rax;rdi=s
call strlen;rax:s->len(s)
mov QWORD PTR [rbp-8], rax ; str_len
; for() first part ends here;[rbp-8]=len
jmp .L2
; for() body begins here
.L5:
cmp BYTE PTR [rbp-9], 13 ; c=='\r'?
je .L3
cmp BYTE PTR [rbp-9], 10 ; c=='\n'?
jne .L4
.L3:;处理换行
mov rax, QWORD PTR [rbp-8] ; str_len
lea rdx, [rax-1] ; EDX=str_len-1
mov rax, QWORD PTR [rbp-24] ; s
add rax, rdx ; RAX=s+str_len-1
mov BYTE PTR [rax], 0 ; s[str_len-1]=0
; for() body ends here
; for() third part begins here
sub QWORD PTR [rbp-8], 1 ; str_len--
; for() third part ends here
.L2:
; for() second part begins here
cmp QWORD PTR [rbp-8], 0 ; str_len==0?
je .L4 ; exit then
; check second clause, and load "c"
mov rax, QWORD PTR [rbp-8] ; RAX=str_len
lea rdx, [rax-1] ; RDX=str_len-1
mov rax, QWORD PTR [rbp-24] ; RAX=s
add rax, rdx ; RAX=s+str_len-1
movzx eax, BYTE PTR [rax] ; AL=s[str_len-1]
mov BYTE PTR [rbp-9], al ; store loaded char into "c"
cmp BYTE PTR [rbp-9], 0 ; is it zero?
jne .L5 ; yes? exit then
; for() second part ends here
.L4:
; return "s"
mov rax, QWORD PTR [rbp-24]
leave
ret执行完长度计算函数strlen()后,控制权将传递给标号为L2的语句。接着注意检查两个条件表达式。如果第一判断条件表达式为真,也就是说如果长度为0(str_len的值为0),那么计算机将不再检测第二个条件判断表达式。这种特性又称为“逻辑短路”
概括地说,这个函数的执行流程如下:
- 运行for()语句的第一部分,也就是调用strlen()函数的循环初始化指令。
- 跳转到标号L2;检测循环条件是否成立。
- 跳转到标号L5,进入循环体;
- 再执行for()语句,如果条件不成立,则直接退出。
- 执行for()语句的第三部分,将变量str_len递减。
- 再次跳转到标号L2,检测循环条件是否成立、进入循环……周而复始,直到循环条件不成立。
- 跳转到L4标号,准备退出。
- 制备返回值,即变量s。
x64 gcc optimizing
str_trim:
push rbx
mov rbx, rdi
; RBX will always be "s"
call strlen
; check for str_len==0 and exit if its so'
test rax, rax
je .L9
lea rdx, [rax-1]
; RDX will always contain str_len-1 value, not str_len
; so RDX is more like buffer index variable
lea rsi, [rbx+rdx] ; RSI=s+str_len-1
movzx ecx, BYTE PTR [rsi] ; load character
test cl, cl
je .L9 ; exit if its zero'
cmp cl, 10
je .L4
cmp cl, 13 ; exit if its not' '\n' and not '\r'
jne .L9
.L4:
; this is weird instruction. we need RSI=s-1 here.
; its possible to get it by' MOV RSI, EBX / DEC RSI
; but this is two instructions instead of one
sub rsi, rax
; RSI = s+str_len-1-str_len = s-1
; main loop begin
.L12:
test rdx, rdx
; store zero at address s-1+str_len-1+1 = s-1+str_len = s+str_len-1
mov BYTE PTR [rsi+1+rdx], 0
; check for str_len-1==0. exit if so.
je .L9
sub rdx, 1 ; equivalent to str_len--
; load next character at address s+str_len-1
movzx ecx, BYTE PTR [rbx+rdx]
test cl, cl ; is it zero? exit then
je .L9
cmp cl, 10 ; is it '\n'?
je .L12
cmp cl, 13 ; is it '\r'?
je .L12
.L9:
; return "s"
mov rax, rbx
pop rbx
retGCC的实现方式更为复杂。在循环体执行前的代码只执行一次,而且它还会检查结束符是不是回车和换行CR/LF。这难道不是多此一举吗?
一般来说,实现主循环体的流程是这样的:
① 循环开始,检查CR/LF结束符,进行判断。
② 保存零字符。
但是,GCC编译器会将这两步逆序执行。因此,第一步肯定不会是保存零字符,而是进行下述判断:
① 看看第一个字符是不是CR/LF,如果不是的话,就会退出。
② 循环开始,保存零字符。
③ 根据检查字符是不是CR/LF来决定程序的执行。
这样处理之后,主循环体就小了很多,更适用于目前的CPU了。这种代码的中间变量不是str_len,而是str_len-1。或许是因为后者更适用于用作缓冲区型数据的索引标号(数组下标)。很明显,GCC注意到了,str_len-1使用了两次。因此最好的办法是分配一个变量,其值总是比目前的字符串的长度小1,然后再将其递减(按照变量str_len的递减方式递减)。
Chap48 toupper()
本章介绍将小写字母转为大写字母的函数
char toupper (char c)
{
if(c>='a' && c<='z')
return c-'a'+'A';
else
return c;
}x64 msvs non-optimizing
1 c$ = 8
2 toupper PROC
3 mov BYTE PTR [rsp+8], cl;rsp+8:c
4 movsx eax, BYTE PTR c$[rsp];eax:c
5 cmp eax, 97;c=97?
6 jl SHORT $LN2@toupper <则exit
7 movsx eax, BYTE PTR c$[rsp];多余的
8 cmp eax, 122;c=122?
9 jg SHORT $LN2@toupper,>则exit
10 movsx eax, BYTE PTR c$[rsp]
11 sub eax, 32;将c-32
12 jmp SHORT $LN3@toupper
13 jmp SHORT $LN1@toupper ; compiler artefact
14 $LN2@toupper:
15 movzx eax, BYTE PTR c$[rsp] ; unnecessary casting
16 $LN1@toupper:
17 $LN3@toupper: ; compiler artefact
18 ret 0
19 toupper ENDP需要注意的是:程序第3行把输入的字节装载到64位栈的那条指令。输入值显然是占据了64位的低8位,而其高位(从第8位到第63位)则保持不变。我们可以在调试器debugger里看到这高56位是随机的噪音数据(也就是随机数)。因为所有指令都是以字节为操作对象,因此这种存储方案不会引发问题。第15行的最后一个MOVZX指令从本地栈里取出一个字节,把它无符号扩展为32位数据中,因此这高56位的噪音数据都会被填充为零
non optimizing gcc貌似更好,没有了多余的指令
toupper:
push rbp
mov rbp, rsp
mov eax, edi
mov BYTE PTR [rbp-4], al
cmp BYTE PTR [rbp-4], 96
jle .L2
cmp BYTE PTR [rbp-4], 122
jg .L2
movzx eax, BYTE PTR [rbp-4]
sub eax, 32
jmp .L3
.L2:
movzx eax, BYTE PTR [rbp-4]
.L3:
pop rbp
retoptimizing msvs
这里优化将两个比较分配为一个比较
toupper PROC
lea eax, DWORD PTR [rcx-97]
cmp al, 25
ja SHORT $LN2@toupper
movsx eax, cl
sub eax, 32
ret 0
$LN2@toupper:
movzx eax, cl
ret 0
toupper ENDPoptimizing gcc
不用跳转指令JUMP而是采用了CMOVcc指令
1 toupper:
2 lea edx, [rdi-97] ; 0x61
3 lea eax, [rdi-32] ; 0x20
4 cmp dl, 25
5 cmova eax, edi
6 ret-
指令格式:
cmova src, dst功能:如果当前的运算结果表明无符号数的比较中,源操作数(
src)大于或等于目标操作数(位于dst),那么这条指令会将src的内容无条件地移动到dst中。这里的“大于或等于”条件是基于EFLAGS寄存器中的零标志(ZF)和符号标志(SF)以及溢出标志(OF)的状态来决定的,确保了是针对无符号整数的比较。 -
也就是如果
dl的值大于25,即为负数的情况,返回原值 -
否则转为大写
Chap49 不正确的反汇编代码
x86环境下的从一开始就错误的反汇编
因为与opcode等长的有ARM以及MIPS指令集(每个指令的opcode要么是2字节要么是4字节),而x86架构下的opcode长度不同,如果x86程序从中间就开始解析指令,无论什么工具都会分析出错误的结果
例如
add [ebp-31F7Bh], cl
dec dword ptr [ecx-3277Bh]
dec dword ptr [ebp-2CF7Bh]
inc dword ptr [ebx-7A76F33Ch]
fdiv st(4), st
db 0FFh
dec dword ptr [ecx-21F7Bh]
dec dword ptr [ecx-22373h]
dec dword ptr [ecx-2276Bh]
dec dword ptr [ecx-22B63h]
dec dword ptr [ecx-22F4Bh]
dec dword ptr [ecx-23343h]
jmp dword ptr [esi-74h]
xchg eax, ebp
clc
std
db 0FFh
db 0FFh;在此之前的反汇编结果都是错误的
mov word ptr [ebp-214h], cs ; <- disassembler finally found right track here
mov word ptr [ebp-238h], ds
mov word ptr [ebp-23Ch], es
mov word ptr [ebp-240h], fs
mov word ptr [ebp-244h], gs
pushf
pop dword ptr [ebp-210h]
mov eax, [ebp+4]
mov [ebp-218h], eax
lea eax, [ebp+4]
mov [ebp-20Ch], eax
mov dword ptr [ebp-2D0h], 10001h
mov eax, [eax-4]
mov [ebp-21Ch], eax
mov eax, [ebp+0Ch]
mov [ebp-320h], eax
mov eax, [ebp+10h]
mov [ebp-31Ch], eax
mov eax, [ebp+4]
mov [ebp-314h], eax
call ds:IsDebuggerPresent
mov edi, eax
lea eax, [ebp-328h]
push eax
call sub_407663
pop ecx
test eax, eax
jnz short loc_402D7B我们该如果分辨出哪些是不正确的反汇编代码呢?
- 不寻常的指令集合,x86常见的指令是
PUSH,MOV,CALL,如果遇到了大杂烩的稀有指令拼盘并且不知所云的就肯定是错的(FPU指令,输入输出IN/OUT等等) - 又大又像是随机数的数值、偏移量以及立即数。
- 转移指令的偏移量不合逻辑,经常跳转到其他指令块的中间。
一些例子
x86的随机数噪声
mov bl, 0Ch
mov ecx, 0D38558Dh
mov eax, ds:2C869A86h
db 67h
mov dl, 0CCh
insb
movsb
push eax
xor [edx-53h], ah
fcom qword ptr [edi-45A0EF72h]
pop esp
pop ss
in eax, dx
dec ebx
push esp
lds esp, [esi-41h]
retf
rcl dword ptr [eax], cl
mov cl, 9Ch
mov ch, 0DFh
push cs
insb
mov esi, 0D9C65E4Dh
imul ebp, [ecx], 66h
pushf
sal dword ptr [ebp-64h], cl
sub eax, 0AC433D64h
out 8Ch, eax
pop ss
sbb [eax], ebx
aas
xchg cl, [ebx+ebx*4+14B31Eh]
jecxz short near ptr loc_58+1
xor al, 0C6h
inc edx
db 36h
pusha
stosb
test [ebx], ebx
sub al, 0D3h ; 'L'
pop eax
stosb
loc_58: ; CODE XREF: seg000:0000004A
test [esi], eax
inc ebp
das
db 64h
pop ecx
das
hlt
pop edx
out 0B0h, al
lodsb
push ebx
cdq
out dx, al
sub al, 0Ah
sti
outsd
add dword ptr [edx], 96FCBE4Bh
and eax, 0E537EE4Fh
inc esp
stosd
cdq
push ecx
in al, 0CBh
mov ds:0D114C45Ch, al
mov esi, 659D1985hx86-64的随机数噪声
lea esi, [rax+rdx*4+43558D29h]
loc_AF3: ; CODE XREF: seg000:0000000000000B46
rcl byte ptr [rsi+rax*8+29BB423Ah], 1
lea ecx, cs:0FFFFFFFFB2A6780Fh
mov al, 96h
mov ah, 0CEh
push rsp
lods byte ptr [esi]
db 2Fh ; /
pop rsp
db 64h
retf 0E993h
cmp ah, [rax+4Ah]
movzx rsi, dword ptr [rbp-25h]
push 4Ah
movzx rdi, dword ptr [rdi+rdx*8]
db 9Ah
rcr byte ptr [rax+1Dh], cl
lodsd
xor [rbp+6CF20173h], edx
xor [rbp+66F8B593h], edx
push rbx
sbb ch, [rbx-0Fh]
stosd
int 87h
db 46h, 4Ch
out 33h, rax
xchg eax, ebp
test ecx, ebp
movsd
leave
push rsp
db 16h
xchg eax, esi
pop rdi
loc_B3D: ; CODE XREF: seg000:0000000000000B5F
mov ds:93CA685DF98A90F9h, eax
jnz short near ptr loc_AF3+6
out dx, eax
cwde
mov bh, 5Dh ; ']'
movsb
pop rbpChap50 混淆技术
代码混淆技术是一种用于阻碍逆向工程分析人员解析程序代码(或功能)的指令处理技术。
字符串变换
在逆向工程的过程中字符串经常起到路标的作用。注意到这个问题的编程人员就会着手解决这个问题。他们会采用一些变换的手法,让他人不能直接通过IDA或者16进制编辑器直接搜索到字符串原文。
-
可以构造一个字符串
Mov byte ptr [ebx], 'h' mov byte ptr [ebx+1], 'e' mov byte ptr [ebx+2], 'l' mov byte ptr [ebx+3], 'l' mov byte ptr [ebx+4], 'o' mov byte ptr [ebx+5], ' ' mov byte ptr [ebx+6], 'w' mov byte ptr [ebx+7], 'o' mov byte ptr [ebx+8], 'r' mov byte ptr [ebx+9], 'l' mov byte ptr [ebx+10], 'd'更复杂的构造方法
mov ebx, offset username cmp byte ptr [ebx], 'j' jnz fail cmp byte ptr [ebx+1], 'o' jnz fail cmp byte ptr [ebx+2], 'h' jnz fail cmp byte ptr [ebx+3], 'n' jnz fail jz it_is_john我们用十六进制的文本编译器都不能直接搜索到字符串原文。
实际上这两种方法适用于那些无法利用数据段构造数据的情景。因为它们可以在文本段直接构造数据,所以也常见于各种PIC和shellcode。
sprintf(buf, "%s%c%s%c%s", "hel",'l',"o w",'o',"rld");加密存储字符串是另一种常见的处理方法。只是这样一来,就要在每次使用前对字符串解密。这个其实是主流的处理方法
可执行代码
插入垃圾代码
在正常执行指令序列中插入一些虽然可被执行但是没有任何作用的指令,本身就是一种代码混淆技术。
add eax, ebx
mul ecx采用混淆技术后的代码
xor esi, 011223344h ; garbage/?
add esi, eax ; garbage/?
add eax, ebx
mov edx, eax ; garbage
shl edx, 4 ; garbage
mul ecx
xor esi, ecx ; garbage在程序代码中插入的混淆指令,调用了源程序不会使用的ESI和EDX寄存器。混淆代码利用了源程序的中间之后,大幅度地增加了反编译的难度,何乐不为呢?(会导致程序运行效率下降,也是有代价的 )
用多个指令组合代替原来的一个指令
-
MOV op1,op2这个指令,可以使用组合指令代替PUSH op2,POP op1 -
JMP label指令可以用PUSH LABEL,RET代替 -
CALL label可以用三个指令代替:PUSH (call 指令后面的那个label),PUSH label和RET指令 -
PUSH op可以用一下的指令代替。SUB ESP,4或8;MOV [ESP],操作符
始终执行或从来不会执行的代码
在下面的代码中,假定此处ESI的值肯定是0,那么我们可以在fake luggage处插入任意长度和复杂度的指令,以达到混淆的目的。这种混淆技术称为不透明谓词(opaque predicate)。
mov esi, 1
... ; some code not touching ESI
dec esi
... ; some code not touching ESI
cmp esi, 0
jz real_code
; fake luggage
real_code:- 我们还可以看看其他的例子,(我们假定ESI始终会是0)
dd eax, ebx ; real code
mul ecx ; real code
add eax, esi ; opaque predicate. XOR, AND or SHL, etc, can be here instead of ADD.打乱指令序列
instruction 1
instruction 2
instruction 3上述三行正常执行的指令序列可以用如下所示的复杂结构代替:
begin: jmp ins1_label
ins2_label: instruction 2
jmp ins3_label
ins3_label: instruction 3
jmp exit:
ins1_label: instruction 1
jmp ins2_label
exit:使用间接指针
dummy_data1 db 100h dup (0)
message1 db 'hello world',0
dummy_data2 db 200h dup (0)
message2 db 'another message',0
func proc
...
mov eax, offset dummy_data1 ; PE or ELF reloc here
add eax, 100h
push eax
call dump_string
...
mov eax, offset dummy_data2 ; PE or ELF reloc here
add eax, 200h
push eax
call dump_string
...
func endp这样我们只能在IDA编译工具中看到dummy_data1和dummy_data2的reference(调用信息)。它不能正常显示调用的真实字符串
全局变量或者函数也可以这样混淆。
虚拟机以及伪代码
编程人员可以构建其自身的PL或者ISA解释器(类似VB.NET或者Java)。这样的话,反编译者就得花很多时间来理解这些解释器指令的意义以及细节。当然,他们基本上必须开发一种专用的反汇编或者反编译工具了。
Chap51* C++
类
一个简单的例子
从汇编层面看,C++类(class)的组织方式和结构体数据完全一致。
#include <stdio.h>
class c
{
private:
int v1;
int v2;
public:
c() // default ctor
{
v1=667;
v2=999;
};
c(int a, int b) // ctor
{
v1=a;
v2=b;
};
void dump()
{
printf ("%d; %d\n", v1, v2);
};
};
int main()
{
class c c1;
class c c2(5,6);
c1.dump();
c2.dump();
return 0;
};msvs x86
_c2$ = -16 ; size = 8
_c1$ = -8 ; size = 8
_main PROC
push ebp
mov ebp, esp
sub esp, 16
lea ecx, DWORD PTR _c1$[ebp]
call ??0c@@QAE@XZ ; c::c
push 6
push 5
lea ecx, DWORD PTR _c2$[ebp]
call ??0c@@QAE@HH@Z ; c::c
lea ecx, DWORD PTR _c1$[ebp]
call ?dump@c@@QAEXXZ ; c::dump
lea ecx, DWORD PTR _c2$[ebp]
call ?dump@c@@QAEXXZ ; c::dump
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP- 首先,程序为每个对象分配了8个字节内存,正好能存储2个变量
- 在初始化c1时,编译器调用了无参构造函数
??0c@@QAE@XZ - 在初始化c2时,编译器调用了无参构造函数
??0c@@QAE@HH@Z,并且传递了2个参数 - 在传递整个类对象的指针时,
this指针通过ecx寄存器传递给被调用方函数。这种调用规范应当符合thiscall规范 MSVS通过ECX寄存器传递this指针。不过,这种调用约定并没有统一的技术规范。GCC编译器以传递第一个函数的参数的方式传递this指针,其他的编译器多数都遵循了GCC的thiscall规范。- 这些函数为什么有很奇怪的名字,这实际上是编译器对函数名称进行的名称改变
- C++的类可能包含同名的但是参数不同的方法(类成员函数)。这就是所谓的多态性。当然不同的类可以有重名却不同的方法
- 名称改编是一种在编译过程中,用
ASCII字符串将函数,变量的名称重新改编的机制。改编后的方法(类成员函数)名称就被用作该程序内部的函数名。这完全是因为编译器的Linker和加载DLL的OS装载器均不能识别C++或OOP(面向对象的编程语言)的数据结构。 - 函数dump()调用了两次。我们再来看看构造函数的指令代码。
_this$ = -4 ; size = 4
??0c@@QAE@XZ PROC ; c::c, COMDAT
; _this$ = ecx
push ebp
mov ebp, esp
push ecx
mov DWORD PTR _this$[ebp], ecx
mov eax, DWORD PTR _this$[ebp]
mov DWORD PTR [eax], 667
mov ecx, DWORD PTR _this$[ebp]
mov DWORD PTR [ecx+4], 999
mov eax, DWORD PTR _this$[ebp]
mov esp, ebp
pop ebp
ret 0
??0c@@QAE@XZ ENDP ; c::c
_this$ = -4 ; size = 4
_a$ = 8 ; size = 4
_b$ = 12 ; size = 4
??0c@@QAE@HH@Z PROC ; c::c, COMDAT
; _this$ = ecx
push ebp
mov ebp, esp
push ecx
mov DWORD PTR _this$[ebp], ecx
mov eax, DWORD PTR _this$[ebp]
mov ecx, DWORD PTR _a$[ebp]
mov DWORD PTR [eax], ecx
mov edx, DWORD PTR _this$[ebp]
mov eax, DWORD PTR _b$[ebp]
mov DWORD PTR [edx+4], eax
mov eax, DWORD PTR _this$[ebp]
mov esp, ebp
pop ebp
ret 8
??0c@@QAE@HH@Z ENDP ; c::c- 构造函数本身就是一种函数,他们使用
ECX存储结构体指针,然后将指针赋值到其自己的局部变量里,第二步并不是必须的 - 构造函数不必返回返回值。事实上,从指令层面来来看,构造函数的返回值是一个新建立的对象的指针,即this指针。
再看看dump()
_this$ = -4 ; size = 4
?dump@c@@QAEXXZ PROC ; c::dump, COMDAT
; _this$ = ecx
push ebp
mov ebp, esp
push ecx
mov DWORD PTR _this$[ebp], ecx
mov eax, DWORD PTR _this$[ebp]
mov ecx, DWORD PTR [eax+4]
push ecx
mov edx, DWORD PTR _this$[ebp]
mov eax, DWORD PTR [edx]
push eax
push OFFSET ??_C@_07NJBDCIEC@?$CFd?$DL?5?$CFd?6?$AA@
call _printf
add esp, 12
mov esp, ebp
pop ebp
ret 0
?dump@c@@QAEXXZ ENDP ; c::dumpdump()函数从ECX寄存器读取一个指向数据结构(这个结构体含有2个int型数据)的指针,然后再把这两个整型数据传递给printf()函数。
MSVS optimizing
??0c@@QAE@XZ PROC ; c::c, COMDAT
; _this$ = ecx
mov eax, ecx
mov DWORD PTR [eax], 667
mov DWORD PTR [eax+4], 999
ret 0
??0c@@QAE@XZ ENDP ; c::c
_a$ = 8 ; size = 4
_b$ = 12 ; size = 4
??0c@@QAE@HH@Z PROC ; c::c, COMDAT
; _this$ = ecx
mov edx, DWORD PTR _b$[esp-4]
mov eax, ecx
mov ecx, DWORD PTR _a$[esp-4]
mov DWORD PTR [eax], ecx
mov DWORD PTR [eax+4], edx
ret 8
??0c@@QAE@HH@Z ENDP ; c::c
?dump@c@@QAEXXZ PROC ; c::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+4]
mov ecx, DWORD PTR [ecx]
push eax
push ecx
push OFFSET ??_C@_07NJBDCIEC@?$CFd?$DL?5?$CFd?6?$AA@
call _printf
add esp, 12
ret 0
?dump@c@@QAEXXZ ENDP ; c::dump-
在使用构造函数之后,栈指针不是通过
add esp,x指令到恢复其初始状态的。另一方面,构造函数的最后一条指令是指令ret 8而不是ret,ret 8相当于add esp,8与ret组合 -
此处不仅遵循了thiscall调用规范(参见51.1.1节),而且还同时遵循stdcall调用规范(64.2节)。Stdcall规范约定:应当由被调用方函数(而不是由调用方函数)恢复参数栈的初始状态。构造函数(也是本例中的被调用方函数)使用“add ESP,x”的指令把本地栈释放x字节,然后把程序控制权传递给调用方函数。
x86-64
在x86-64环境里的64位应用程序使用RCX,RDX,R8以及R9这4个寄存器传递函数的前4想参数,其他参数用栈处理。
调用那些涉及类成员函数的时候,==编译器会通过RCX寄存器传递类对象的this指针,用RDX寄存器传递函数的第一个参数,依此类推。==我们可以在类成员函数c(int a,int b)中看到这一点。
; void dump()
?dump@c@@QEAAXXZ PROC ; c::dump
mov r8d, DWORD PTR [rcx+4]
mov edx, DWORD PTR [rcx]
lea rcx, OFFSET FLAT:??_C@_07NJBDCIEC@?$CFd?$DL?5?$CFd?6?$AA@ ; '%d; %d'
jmp printf
?dump@c@@QEAAXXZ ENDP ; c::dump
; c(int a, int b)
??0c@@QEAA@HH@Z PROC ; c::c
mov DWORD PTR [rcx], edx ; 1st argument: a
mov DWORD PTR [rcx+4], r8d ; 2nd argument: b
mov rax, rcx
ret 0
??0c@@QEAA@HH@Z ENDP ; c::c
; default ctor
??0c@@QEAA@XZ PROC ; c::c
mov DWORD PTR [rcx], 667
mov DWORD PTR [rcx+4], 999
mov rax, rcx
ret 0
??0c@@QEAA@XZ ENDP ; c::c- 在x86-64环境下的
int数据仍然是32位数据。因此,上述程序仍然使用32位寄存器传递整型数据 - 类成员函数dump()还使用了JMP printf指令取代了CALL和RET指令。
gcc x86
gcc4.4.1的编译方式和MSVS2012的编译手段差不多
public main
main proc near
var_20 = dword ptr -20h
var_1C = dword ptr -1Ch
var_18 = dword ptr -18h
var_10 = dword ptr -10h
var_8 = dword ptr -8
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 20h
lea eax, [esp+20h+var_8]
mov [esp+20h+var_20], eax
call _ZN1cC1Ev
mov [esp+20h+var_18], 6
mov [esp+20h+var_1C], 5
lea eax, [esp+20h+var_10]
mov [esp+20h+var_20], eax
call _ZN1cC1Eii
lea eax, [esp+20h+var_8]
mov [esp+20h+var_20], eax
call _ZN1c4dumpEv
lea eax, [esp+20h+var_10]
mov [esp+20h+var_20], eax
call _ZN1c4dumpEv
mov eax, 0
leave
retn
main endp- 可以看到,类成员函数的名称是另一种风格的改变,被称为
GNU专用风格 类对象的this指针是以函数的第一个参数的方式传递的
首先查看第一个构造函数
public _ZN1cC1Ev ; weak
_ZN1cC1Ev proc near ; CODE XREF: main+10
arg_0 = dword ptr 8
push ebp
mov ebp, esp
mov eax, [ebp+arg_0]
mov dword ptr [eax], 667
mov eax, [ebp+arg_0]
mov dword ptr [eax+4], 999
pop ebp
retn
_ZN1cC1Ev endp可以看到,通过外部传来的第一个参数,即eax的值获得了结构指针,然后在相应地址修改了2个数值
第二个构造函数
public _ZN1cC1Eii
_ZN1cC1Eii proc near
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
push ebp
mov ebp, esp
mov eax, [ebp+arg_0]
mov edx, [ebp+arg_4]
mov [eax], edx
mov eax, [ebp+arg_0]
mov edx, [ebp+arg_8]
mov [eax+4], edx
pop ebp
retn
_ZN1cC1Eii endp与第一个构造函数类似,区别在于,赋值是传递给这个函数的参数
再来看看dump()函数
public _ZN1c4dumpEv
_ZN1c4dumpEv proc near
var_18 = dword ptr -18h
var_14 = dword ptr -14h
var_10 = dword ptr -10h
arg_0 = dword ptr 8
push ebp
mov ebp, esp
sub esp, 18h
mov eax, [ebp+arg_0];eax=this
mov edx, [eax+4];edx=this+1
mov eax, [ebp+arg_0]
mov eax, [eax]
mov [esp+18h+var_10], edx
mov [esp+18h+var_14], eax
mov [esp+18h+var_18], offset aDD ; "%d; %d\n"
call _printf
leave
retn
_ZN1c4dumpEv endp- 没有使用栈就将参数直接传递给了
printf函数
综合本节的各例可知,MSVC和GCC的区别在于函数名的名称编码风格以及传递this指针的具体方式 (MSVC通过ECX传递,而GCC以函数的第一个参数的方式传递)。
gcc-x86-64
在编译64位应用程序的时候,GCC通过RDI、RSI、RDX、RCX、R8以及R9这几个寄存器传递函数的前6个参数。它通过RDI寄存器,以第一个函数参数的形式传递this指针。另外,整数型int数据依然是32位数据。它还会不时使用转移指令JMP替代RET指令。
; default ctor
_ZN1cC2Ev:
mov DWORD PTR [rdi], 667
mov DWORD PTR [rdi+4], 999
ret
; c(int a, int b)
_ZN1cC2Eii:
mov DWORD PTR [rdi], esi
mov DWORD PTR [rdi+4], edx
ret
; dump()
_ZN1c4dumpEv:
mov edx, DWORD PTR [rdi+4]
mov esi, DWORD PTR [rdi]
xor eax, eax
mov edi, OFFSET FLAT:.LC0 ; "%d; %d\n"
jmp printf类继承
继承而来的类与前文的简单结构体类似,但是可以对父类进行拓展
#include <stdio.h>
class object
{
public:
int color;
object() { };
object (int color) { this->color=color; };
void print_color() { printf ("color=%d\n", color); };
};
class box : public object
{
private:
int width, height, depth;
public:
box(int color, int width, int height, int depth)
{
this->color=color;
this->width=width;
this->height=height;
this->depth=depth;
};
void dump()
{
printf ("this is box. color=%d, width=%d, height=%d, depth=%d\n", color, width, ↙
↘ height, depth);
};
};
class sphere : public object
{
private:
int radius;
public:
sphere(int color, int radius)
{
this->color=color;
this->radius=radius;
};
void dump()
{
printf ("this is sphere. color=%d, radius=%d\n", color, radius);
};
};
int main()
{
box b(1, 10, 20, 30);
sphere s(2, 40);
b.print_color();
s.print_color();
b.dump();
s.dump();
return 0;
};- 我们共同关注
dump()函数以及object::print_color()的指令代码,重点分析32位环境下有关数据类型的内存存储格局
msvs 2008 /Ob0
??_C@_09GCEDOLPA@color?$DN?$CFd?6?$AA@ DB 'color=%d', 0aH, 00H ; `string'
?print_color@object@@QAEXXZ PROC ; object::print_color, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx]
push eax
; 'color=%d', 0aH, 00H
push OFFSET ??_C@_09GCEDOLPA@color?$DN?$CFd?6?$AA@
call _printf
add esp, 8
ret 0
?print_color@object@@QAEXXZ ENDP ; object::print_color?dump@box@@QAEXXZ PROC ; box::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+12]
mov edx, DWORD PTR [ecx+8]
push eax
mov eax, DWORD PTR [ecx+4]
mov ecx, DWORD PTR [ecx]
push edx
push eax
push ecx
; 'this is box. color=%d, width=%d, height=%d, depth=%d', 0aH, 00H ; `string'
push OFFSET ??_C@_0DG@NCNGAADL@this?5is?5box?4?5color?$DN?$CFd?0?5width?$DN?$CFd?0@
call _printf
add esp, 20
ret 0
?dump@box@@QAEXXZ ENDP ; box::dump?dump@sphere@@QAEXXZ PROC ; sphere::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+4]
mov ecx, DWORD PTR [ecx]
push eax
push ecx
; 'this is sphere. color=%d, radius=%d', 0aH, 00H
push OFFSET ??_C@_0CF@EFEDJLDC@this?5is?5sphere?4?5color?$DN?$CFd?0?5radius@
call _printf
add esp, 12
ret 0
?dump@sphere@@QAEXXZ ENDP ; sphere::dump- 我们从上述汇编可以看出内存的基本排列
① 父类object对象的存储格局如下所示。
| offset | description |
|---|---|
| +0x0 | int color |
② 继承类对象:box和sphere(分别为盒子和球体)的存储格局分别如下面两张表所示。
box
| offset | description |
|---|---|
| +0x0 | int color |
| +0x4 | int width |
| +0x8 | int height |
| +0xC | int depth |
sphere
| offset | description |
|---|---|
| +0x0 | int color |
| +0x4 | int radius |
再来看看main
PUBLIC _main
_TEXT SEGMENT
_s$ = -24 ; size = 8
_b$ = -16 ; size = 16
_main PROC
sub esp, 24
;box b(1,10,20,30)
push 30
push 20
push 10
push 1
lea ecx, DWORD PTR _b$[esp+40]
call ??0box@@QAE@HHHH@Z ; box::box
;sphere s(2,40)
push 40
push 2
lea ecx, DWORD PTR _s$[esp+32]
call ??0sphere@@QAE@HH@Z ; sphere::sphere;构造函数
lea ecx, DWORD PTR _b$[esp+24]
call ?print_color@object@@QAEXXZ ; object::print_color
lea ecx, DWORD PTR _s$[esp+24]
call ?print_color@object@@QAEXXZ ; object::print_color
lea ecx, DWORD PTR _b$[esp+24]
call ?dump@box@@QAEXXZ ; box::dump
lea ecx, DWORD PTR _s$[esp+24]
call ?dump@sphere@@QAEXXZ ; sphere::dump
xor eax, eax
add esp, 24
ret 0
_main ENDP- 继承类必须在其基(父)类字段的后面加入自己的字段,因此基类和继承类的类成员函数可以共存。
- 当程序调用类成员对象
object::print_color()时,指向对象box和sphere的指针是通过this指针传递的。由于在所有继承类和基类中color字段的偏移量固定为0(offset+0x0),所有类对象的类成员函数object::print_color都可以正常运行 - 因此,无论是基类还是继承类调用object::print_color(),只要该方法所引用的字段的相对地址固定不变,那么该方法就可以正常运行。
- 假如基于box类创建一个继承类,那么编译器就会在
变量depth的后面追加您所添加新的变量,以确保基类box的各字段的相对地址在其继承类中固定不变。 - 当父类为box类的各继承类在调用各自的方法box::dump()时,它们都能检索到color、width、height以及depths字段的正确地址。因为各字段的相对地址不会发生变化。
gcc生成的代码与msvs类似,区别仍然是gcc不会使用ecx寄存器传递this指针,而是用函数的第一个参数的传递方式传递this指针
封装
封装(encapsulation)的作用是:把既定的数据和方法限定为类的私有信息,使得其他调用方只能访问类所定义的公共方法和公共数据、不能直接访问被封装起来的私有对象。
然而在指令层面,到底有没有划分私有对象和公开对象的界限呢?
其实完全没有。
#include <stdio.h>
class box
{
private:
int color, width, height, depth;
public:
box(int color, int width, int height, int depth)
{
this->color=color;
this->width=width;
this->height=height;
this->depth=depth;
};
void dump()
{
printf ("this is box. color=%d, width=%d, height=%d, depth=%d\n", color, width,height, depth);
};
};启用MSVC 2008的优化选项/Ox和/Ob0编译上述程序,再查看类函数box::dump()的代码。
?dump@box@@QAEXXZ PROC ; box::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+12]
mov edx, DWORD PTR [ecx+8]
push eax
mov eax, DWORD PTR [ecx+4]
mov ecx, DWORD PTR [ecx]
push edx
push eax
push ecx
; 'this is box. color=%d, width=%d, height=%d, depth=%d', 0aH, 00H
push OFFSET ??_C@_0DG@NCNGAADL@this?5is?5box?4?5color?$DN?$CFd?0?5width?$DN?$CFd?0@
call _printf
add esp, 20
ret 0
?dump@box@@QAEXXZ ENDP ; box::dump-
显然内存分布与先前是相同的
offset description +0x0 int color +0x4 int width +0x8 int height +0xC int depth -
所有字段都是无法被其他函数直接访问的私有变量,但是既然我们知道了这个对象的内存存储格局,我们其实可以写一个修改这些变量的程序
void hack_oop_encapsulation(class box * o) { o->width=1; // that code cant be compiled': // "error C2248: 'box::width' : cannot access private member declared in class 'box'" };这样写无法被成功编译,但事实上,我们可以将
Box数据类型转换为整型数组,进而编译并且直接修改相应字段void hack_oop_encapsulation(class box * o) { unsigned int *ptr_to_object=reinterpret_cast<unsigned int*>(o); ptr_to_object[1]=123; };最终
this is box. color=1, width=10, height=20, depth=30 this is box. color=1, width=123, height=20, depth=30 -
封装只能够在编译阶段保护类的私有对象。虽然C++编译器禁止外部代码直接访问那些被明确屏蔽的内部对象,但是通过适当的hack技术,我们确实能够突破编译器的限制策略。
多重继承
多类继承-指的是一个类可以同时继承多个父类的字段和方法
#include <stdio.h>
class box
{
public:
int width, height, depth;
box() { };
box(int width, int height, int depth)
{
this->width=width;
this->height=height;
this->depth=depth;
};
void dump()
{
printf ("this is box. width=%d, height=%d, depth=%d\n", width, height, depth);
};
int get_volume()
{
return width * height * depth;
};
};
class solid_object
{
public:
int density;
solid_object() { };
solid_object(int density)
{
this->density=density;
};
int get_density()
{
return density;
};
void dump()
{
printf ("this is solid_object. density=%d\n", density);
};
};
class solid_box: box, solid_object
{
public:
solid_box (int width, int height, int depth, int density)
{
this->width=width;
this->height=height;
this->depth=depth;
this->density=density;
};
void dump()
{
printf ("this is solid_box. width=%d, height=%d, depth=%d, density=%d\n", width,↙
↘ height, depth, density);
};
int get_weight() { return get_volume() * get_density(); };
};
int main()
{
box b(10, 20, 30);
solid_object so(100);
solid_box sb(10, 20, 30, 3);
b.dump();
so.dump();
sb.dump();
printf ("%d\n", sb.get_weight());
return 0;
};box::dump(),solid_object::dump()以及solid_box::dump()这3个类成员函数。
?dump@box@@QAEXXZ PROC ; box::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+8]
mov edx, DWORD PTR [ecx+4]
push eax
mov eax, DWORD PTR [ecx]
push edx
push eax
; 'this is box. width=%d, height=%d, depth=%d', 0aH, 00H
push OFFSET ??_C@_0CM@DIKPHDFI@this?5is?5box?4?5width?$DN?$CFd?0?5height?$DN?$CFd@
call _printf
add esp, 16
ret 0
?dump@box@@QAEXXZ ENDP ; box::dump?dump@solid_object@@QAEXXZ PROC ; solid_object::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx]
push eax
; 'this is solid_object. density=%d', 0aH
push OFFSET ??_C@_0CC@KICFJINL@this?5is?5solid_object?4?5density?$DN?$CFd@
call _printf
add esp, 8
ret 0
?dump@solid_object@@QAEXXZ ENDP ; solid_object::dump?dump@solid_box@@QAEXXZ PROC ; solid_box::dump, COMDAT
; _this$ = ecx
mov eax, DWORD PTR [ecx+12]
mov edx, DWORD PTR [ecx+8]
push eax
mov eax, DWORD PTR [ecx+4]
mov ecx, DWORD PTR [ecx]
push edx
push eax
push ecx
; 'this is solid_box. width=%d, height=%d, depth=%d, density=%d', 0aH
push OFFSET ??_C@_0DO@HNCNIHNN@this?5is?5solid_box?4?5width?$DN?$CFd?0?5hei@
call _printf
add esp, 20
ret 0
?dump@solid_box@@QAEXXZ ENDP ; solid_box::dump① 类box。如下表所示。
| offset | description |
|---|---|
| +0x0 | width |
| +0x4 | height |
| +0x8 | depth |
② 类solid_object。如下表所示。
| offset | description |
|---|---|
| +0x0 | density |
③ 类solid_box,可以看成是以上两个类的联合体。如下表所示。
| offset | description |
|---|---|
| +0x0 | width |
| +0x4 | height |
| +0x8 | depth |
| +0xC | density |
以上图表采用了偏移量与对应变量的方式展现3个类对象的内存存储结构。图中一共出现了4个变量,即长width、高height、宽depth以及密度density。
体积函数和密度函数不需要分析,与前例是一样的
关键多重继承的solod_box的get_weight函数
?get_weight@solid_box@@QAEHXZ PROC ; solid_box::get_weight, COMDAT
; _this$ = ecx
push esi
mov esi, ecx
push edi
lea ecx, DWORD PTR [esi+12]
call ?get_density@solid_object@@QAEHXZ ; solid_object::get_density
mov ecx, esi
mov edi, eax
call ?get_volume@box@@QAEHXZ ; box::get_volume
imul eax, edi
pop edi
pop esi
ret 0
?get_weight@solid_box@@QAEHXZ ENDP ; solid_box::get_weightget_weight调用了父类的两个方法- 在调用
get_volume计算体积的时候传递的是this指针 - 而在调用
get_density计算密度函数,传递的参数地址是this+12,(这个就相当于是solid_object类的this指针)这个地址对应的是solid_box类的solid_object字段 solid_object::get_density()认为,它处理的是常规的solid_object类,而box::get_volume()则可以正常访问原有数据类型的3个变量,如同直接操作box类一样。- 继承了其他的、多个类而生成的类对象,在内存之中就是一种联合体型的数据结构。它继承了原有父类的全部字段和方法。在这种继承类对象调用某个具体方法时,它传递的是与该方法原有基类相对地址相应的this指针。
虚拟方法
它允许在派生类中重写基类的方法。使用虚拟函数,可以使得基类的指针或引用在指向派生类对象时,调用派生类中重写的函数版本,而不是基类中的函数版本。这样就增强了代码的灵活性和可扩展性。
- 声明:在基类中,通过在函数声明前加上
virtual关键字来声明一个函数为虚拟函数 - 重写:在派生类,通过使用相同函数名,返回类型和参数列表来重写(Override)基类的虚拟函数。派生类
不需要再次使用virtual关键字,但可以使用override来明确表示该函数是重写基类的虚拟函数,有助于编译器检查 - 虚函数表:编译器会
为包含至少一个虚拟函数的类生成一个虚函数表(vtable),其中存储了该类所有虚拟函数的地址。每个具有虚拟函数的类实例都会有一个指向相应虚函数表的指针(通常作为对象的第一个成员)。 - 动态绑定:当通过基类指针或引用来调用一个虚拟函数时,实际调用哪个版本的函数是在运行时决定的,依据是指针或引用所指向的对象的实际类型。
#include <stdio.h>
class object
{
public:
int color;
object() { };
object (int color) { this->color=color; };
virtual void dump()
{
printf ("color=%d\n", color);
};
};
class box : public object
{
private:
int width, height, depth;
public:
box(int color, int width, int height, int depth)
{
this->color=color;
this->width=width;
this->height=height;
this->depth=depth;
};
void dump()
{
printf ("this is box. color=%d, width=%d, height=%d, depth=%d\n", color, width, height, depth);
};
};
class sphere : public object
{
private:
int radius;
public:
sphere(int color, int radius)
{
this->color=color;
this->radius=radius;
};
void dump()
{
printf ("this is sphere. color=%d, radius=%d\n", color, radius);
};
};
int main()
{
box b(1, 10, 20, 30);
sphere s(2, 40);
object *o1=&b;
object *o2=&s;
o1->dump();
o2->dump();
return 0;
};- 在这个例子中,类
object定义了一个虚拟函数dump(),它被继承类box和sphere中的同名函数覆盖了 - 在调用虚拟函数时,
编译器阶段可能无法确定对象的类型情况。当类中含有虚函数时,其基类的指针就可以指向任何派生类的对象,这时就有可能不知道基类指针到底指向的是哪个对象的情况。这时就要根据实时类型信息,确定应当调用的相应函数。
_s$ = -32 ; size = 12
_b$ = -20 ; size = 20
_main PROC
sub esp, 32
push 30
push 20
push 10
push 1
lea ecx, DWORD PTR _b$[esp+48]
call ??0box@@QAE@HHHH@Z ; box::box
push 40
push 2
lea ecx, DWORD PTR _s$[esp+40]
call ??0sphere@@QAE@HH@Z ; sphere::sphere
mov eax, DWORD PTR _b$[esp+32]
mov edx, DWORD PTR [eax]
lea ecx, DWORD PTR _b$[esp+32]
call edx;o1->dump
mov eax, DWORD PTR _s$[esp+32]
mov edx, DWORD PTR [eax]
lea ecx, DWORD PTR _s$[esp+32]
call edx;o2->dump
xor eax, eax
add esp, 32
ret 0
_main ENDP- 指向
dump函数的函数指针应当位于类对象object中的某个地方。我们在哪里去找新方法的函数地址呢?它必定由构造函数定义: main()函数没调用其他函数,因此这个指针肯定由构造函数定义。因此我们具体看看各个类的构造函数是如何实现的
box类的构造函数
??_R0?AVbox@@@8 DD FLAT:??_7type_info@@6B@ ; box 'RTTI Type Descriptor'
DD 00H
DB '.?AVbox@@', 00H
??_R1A@?0A@EA@box@@8 DD FLAT:??_R0?AVbox@@@8 ; box::'RTTI Base Class Descriptor at (0,-1,0,64)'
DD 01H
DD 00H
DD 0ffffffffH
DD 00H
DD 040H
DD FLAT:??_R3box@@8
??_R2box@@8 DD FLAT:??_R1A@?0A@EA@box@@8 ; box::'RTTI Base Class Array'
DD FLAT:??_R1A@?0A@EA@object@@8
??_R3box@@8 DD 00H ; box::'RTTI Class Hierarchy Descriptor'
DD 00H
DD 02H
DD FLAT:??_R2box@@8
??_R4box@@6B@ DD 00H ; box::'RTTI Complete Object Locator'
DD 00H
DD 00H
DD FLAT:??_R0?AVbox@@@8
DD FLAT:??_R3box@@8
??_7box@@6B@ DD FLAT:??_R4box@@6B@ ; box::`vftable'
DD FLAT:?dump@box@@UAEXXZ
_color$ = 8 ; size = 4
_width$ = 12 ; size = 4
_height$ = 16 ; size = 4
_depth$ = 20 ; size = 4
??0box@@QAE@HHHH@Z PROC ; box::box, COMDAT
; _this$ = ecx
push esi
mov esi, ecx
call ??0object@@QAE@XZ ; object::object
mov eax, DWORD PTR _color$[esp]
mov ecx, DWORD PTR _width$[esp]
mov edx, DWORD PTR _height$[esp]
mov DWORD PTR [esi+4], eax
mov eax, DWORD PTR _depth$[esp]
mov DWORD PTR [esi+16], eax
mov DWORD PTR [esi], OFFSET ??_7box@@6B@
mov DWORD PTR [esi+8], ecx
mov DWORD PTR [esi+12], edx
mov eax, esi
pop esi
ret 16
??0box@@QAE@HHHH@Z ENDP ; box::box??_R0?AVbox@@@8 DD FLAT:??_7type_info@@6B@: 这一行定义了类box的RTTI Type Descriptor,是运行时识别对象类型的元数据的一部分。它指向一个通用的type_info结构。??_R1A@?0A@EA@box@@8 DD ...: 这一部分定义了RTTI Base Class Descriptor,描述了类box的基类关系。这里显示box有一个基类,并提供了关于这个基类的偏移量、虚函数表指针等信息。??_R2box@@8 DD ...: RTTI Base Class Array,列出了box类的所有基类的RTTI Base Class Descriptor的地址。??_R3box@@8 DD ...: RTTI Class Hierarchy Descriptor,描述了类层次结构的信息,包括类的虚函数表数量和基类数组的地址。??_R4box@@6B@ DD ...: RTTI Complete Object Locator,提供了定位完整对象所需的信息,包括类型描述符、虚函数表等的地址。??_7box@@6B@ DD FLAT:??_R4box@@6B@: 这是类box的虚函数表(vtable)的开始,它指向了RTTI Complete Object Locator。DD FLAT:?dump@box@@UAEXXZ: 这一行在虚函数表中添加了一个条目,指向box类的一个虚函数(在这个例子中似乎是dump函数)。
分析这个构造函数的内存分布
-
第一个字段是某个
box::vftable的指针 -
在这个表中,我们看到
一个指向数据表box::RTTI Complete Object Locator的链接和一个指向类成员函数box::dump()的链接。它们的正规名称分别是虚拟方法表和RTTI。虚拟方法表存储着各方法的地址,RTTI表存储着类型的信息。另外,RTTI表为C++程序提供了“强制转换运算符”dynamic_cast (将基类类型的指针或引用安全地转换为派生类型的指针或引用)和“类型查询操作符”typeid。在上述指令调用类成员函数时,它所使用的类名称仍然是文本型字符串。基于代码中dump()函数的实例情况可知,在通过调用指向基类的指针(或引用)调用其虚拟函数(类实例::虚方法)时,指针最终会指向派生类实例的同名虚拟方法——构造函数会把指针实际指向的对象实例的类型信息存储在数据结构之中。 -
在内存数据表里检索虚拟方法的内存地址必定要消耗额外的CPU时间。因此虚拟方法的运行速度比一般的方法要慢一些。
总结
- 编译阶段:
- 生成虚函数表(VTable):当编译器遇到含有虚函数的类时,它会为该类生成一个虚函数表(VTable)。这个表是一个内存区域,其中存储了类中所有虚函数的地址。
- 插入虚函数表指针(VPtr):对于每个从含有虚函数的类派生出来的对象,编译器会在对象内存布局的开始位置(通常是第一个成员,但这也取决于编译器和平台(如果有构造函数就是在构造函数里)插入一个指向该类虚函数表的指针(VPtr)。
- 链接阶段:
- 地址分配:链接器会为每个函数分配最终的内存地址,包括虚函数。这一步骤确保了虚函数表中存储的地址是正确的。
- 运行时:
- 虚函数调用:当通过基类指针或引用来调用虚函数时,实际执行的代码如下:
- 首先,程序通过对象的VPtr找到其对应的虚函数表。
- 然后,根据函数调用在代码中的偏移量(即虚函数在VTable中的位置),从虚函数表中取出实际要调用的函数地址。
- 最后,通过这个地址跳转到并执行实际的虚函数代码。
- 虚函数调用:当通过基类指针或引用来调用虚函数时,实际执行的代码如下:
总结来说,虚函数的地址是在编译时由编译器确定并填充到虚函数表中,而具体调用哪个虚函数则是在运行时通过对象的VPtr和虚函数表来动态决定的。这种机制实现了C++中的多态性,即允许派生类对象通过基类指针或引用来表现出不同的行为。
ostream输出流
#include <iostream>
int main()
{
std::cout<<"Hello,world!\n";
}运算重载符“<<”的作用是“重载”其他类型的数据,主要用于对象之间的运算。
$SG37112 DB 'Hello, world!', 0aH, 00H
_main PROC
push OFFSET $SG37112
push OFFSET ?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A ; std::cout
call ??$?6U?$char_traits@D@std@@@std@@YAAAV?$basic_ostream@DU? ↙
↘ $char_traits@D@std@@@0@AAV10@PBD@Z ; std::operator<<<std::char_traits<char> >
add esp, 8
xor eax, eax
ret 0
_main ENDPstd::cout << "Hello, " << "world!\n";
相当于f(f(std::cout, "Hello, "), "world!");
引用
C++ 中指针和引用的区别 | 编程指北 (csguide.cn)
引用可以看做是一个常量指针
void f2 (int x, int y, int & sum, int & product)
{
sum=x+y;
product=x*y;
};_x$ = 8 ; size = 4
_y$ = 12 ; size = 4
_sum$ = 16 ; size = 4
_product$ = 20 ; size = 4
?f2@@YAXHHAAH0@Z PROC ; f2
mov ecx, DWORD PTR _y$[esp-4]
mov eax, DWORD PTR _x$[esp-4]
lea edx, DWORD PTR [eax+ecx];edx:sum=x+y
imul eax, ecx;eax:x*y
mov ecx, DWORD PTR _product$[esp-4];ecx=ptr(product)
push esi
mov esi, DWORD PTR _sum$[esp];esi=ptr(sum)
mov DWORD PTR [esi], edx;sum=x+y
mov DWORD PTR [ecx], eax;product=x*y
pop esi
ret 0
?f2@@YAXHHAAH0@Z ENDP ; f2*stl(standard template library)
std::string(字符串)
std::string定义为以下几个组件:缓冲区指针、字符串缓冲区、当前字符串的长度(便于函数操作;请参阅[Yur13]的2.2.1节)以及当前缓冲区的容量。在缓冲区里,字符串通常用0作字符串结束符,以兼容常规的C语言ASCIIZ字符串格式。
在C++的标准数据结构中,字符串不是类对象。它把字符串定义为模版型数据。这是为了兼容各个类型的字符元素。现在,它至少支持char(标准字符串)以及wchar_t
std::string是以8位字符char为基本类型的类,而std::wstring则是以16/32位宽字符wchar_t为基本类型的
msvs
- 当字符串长度在16字符以内时,msvs将字符串数据直接存储在缓冲区,不再使用
指针+缓冲区的复杂结构 - 在
32位系统里,字符串最少会占用24个字节 - 在
64至少占用(16+8+8)32个字节
后面的看不太懂
等看完了C++Primer学完再看
Chap52 数组与负数索引
-
array[-1]实际上表示数组array起始地址之前的存储空间 -
x86平台的小端字节序。
Chap53 16位windows程序
虽然16位的Windows程序已经近乎绝迹,但是有关复古程序以及研究加密狗的研究,往往会涉及这部分知识。
-
16位应用程序的代码结构与
MSDOS的程序十分类似’,这种类型的可执行文件采用了一种名为“New Executable (NE)”的可执行程序格式。’ -
基于Pascal语言的调用约定要求:参数从左至右入栈(与cdecl相反)。
-
16位应用程序的指针是一对数据:函数首先传递的是数据段的地址,然后再传递段内的指针地址。
-
当16位系统(MSDOS和Win16)传递long型32位“长”数据时(这种平台上的int型数据是16位数据),它会将32位数据拆成2个16位数据、成对传递。
-
在返回函数值的时候,32位的返回值通过DX:AX寄存器对回传。
-
“near”指针的寻址空间是当前数据段(DS)内的所有地址。
-
“far”指针的寻址空间不限于当前数据段,它可以是其他DS段的内存地址。由于需要指定基(段)地址,所以2个16位数据才能表示1个far型指针。
Chap54* Java
先略
Part.5 在代码中发现有趣的内容
Chap55编译器产生的文件特征
Microsoft Visual C++
msvcp*.dll含有C相关函数,因此导入这些DLL文件的可执行程序很可能是C程序。
命名规则
msvs名字通常都是以“?”开始的。
gcc
gcc命名通常以符号“_Z”开始。
GCC在Cygwin环境下编译的应用程序,通常会导入cygwin1.dll文件。
GCC在mingw环境下编译的应用程序,可能会导入msvcrt.dll文件。
intel fortran
由Intel Fortran编译的应用程序,可能会导入以下3个文件:
① Libifcoremd.dll。
② Libifportmd.dll。
③ Libiomp5.dll(支持OpenMP)。
库文件libifcoremd.dll定义了很多以字符串“for_”开头的函数。它就是FORTRAN的代表性前缀。
watcom和openwatcom
由Watcom编译出来的程序,其符号名称通常以“W”字母开头。
以W?methodn__v为例:大写字母W开头代表它是Watcom编译出来的程序,方法的名称为method,类的名称为class,没有参数且无返回值的void方法会命名为:
W?method$_class$n__vborland
@TApplication@IdleAction$qv
@TApplication@ProcessMDIAccels$qp6tagMSG
@TModule@$bctr$qpcpvt1
@TModule@$bdtr$qv
@TModule@ValidWindow$qp14TWindowsObject
@TrueColorTo8BitN$qpviiiiiit1iiiiii
@TrueColorTo16BitN$qpviiiiiit1iiiiii
@DIB24BitTo8BitBitmap$qpviiiiiit1iiiii
@TrueBitmap@$bctr$qpcl
@TrueBitmap@$bctr$qpvl
@TrueBitmap@$bctr$qiilll- 符号名称必定以字符“@”开头
- 后面几个字母分别代表:类名称、方法名称以及方法的参数类型。
- VCL的全称是Borland Visual Component Libraries,意思是Borland的可视化组件库。它们保存在bpl文件中,而不是保存在dll文件中。比如说文件vcl50.dll和rtl60.dll。
delphi
数据段(DATA)的头四个字节通常是以下三个组合中的一个任意一个:00 00 00 00、32 13 8B C0或者FF FF FF FF。在处理被压缩或者被加密的Dephi可执行文件时,这组常数就会具有指标性意义。
其他的dll
- Vcomp*.dll。微软用来实现OpenMP的文件。
Chap56Win32环境与外部通信
-
在了解函数的输入输出的情况下,可以推理出函数的具体功能,这是一种有效的分析方法
-
关注文件和注册表层面的行为,可以使用
Process Monitor -
查看网络层面的通信数据,可以使用
WireShark -
进一步分析行为级数据,就要深入程序内部挖掘指令层面的信息
-
首先调查该程序调用的操作系统API和标准库函数
-
如果目标程序由可执行文件和多个DLL文件构成
那么由这些DLL文件所提供的,可调用的函数名称就可以提供很大帮助
-
如果只关心调用
MessageBox()显示特定文字的指令 -
可以在程序的数据段检索文字字符,然后交叉引用,到达关键代码段
-
-
分析电脑游戏时,如果可以确定特定关卡里出现的低人总数是随机数,我们可以查找
rand()以及类似的随机数生成函数,然后交叉引用找到使用随机数的指令 -
电脑游戏以外,如果使用了
rand()可能是 加密算法
常用WindowsAPI
-
注册表的操作可以通过库文件advspi32.dll的如下功能实现:RegEnumKeyEx、RegEnumValue、RegGetValue、RegOpenKeyEx和RegQueryValueEx。
-
对类似ini的文本文件可以通过库文件user32.dll的如下函数实现:GetPrivateProfileString。
-
对话窗的操作通过库文件user32.dll的如下函数实现:MessageBoxEx、SetDlgItemText及GetDlgItemText。
-
对资源的操作(可以参考本书的68.2.8节)通过库文件user32.dll的函数LoadMenu实现。
-
对TCP/IP网络的操作是通过库文件ws2_32.dll的如下函数实现:WSARecv和WSASend。
-
对文件的操作是通过库文件kernel32.dll的如下函数实现相应的操作:CreateFile、ReadFile、ReadFileEx、WriteFile及WriteFileEx等。
-
访问Internet是通过库文件wininet.dll的WinHttpOpen等函数来实现相关功能的。
-
检查一个可执行文件是否含有数字签名则是通过库文件wintrust.dll的函数WinVerifyTrust等来实现的。
-
如果是动态链接的话,标准的MSVC库文件msvcr*.dll是通过以下函数实现相关操作的:assert、itoa、ltoa、open、printf、read、strcmp、atol、atoi、fopen、fread、fwrite、memcmp、rand、strlen、strstr以及strchr。
Chap57字符串
UTF-16LE
很多Windows系统下的win32函数有-A和-W后缀。前面这种函数用于处理常规字符串,而后面这种带有-w的函数则是UTF-16LE字符串的专用函数(w代表wide)。
Chap58 assert()
一般来讲,assert()宏在可执行文件中保留了源代码的文件名、行数以及执行条件。
最有价值的信息是assert()宏的执行条件。我们可以通过它们来推断出变量名或者结构体的字段名称。另外一个有用的信息是文件名,通过它我们可以推断出源代码是采用什么语言编写的。同时我们还可能通过文件名来识别出其是否采用了知名的开放源代码库。
.text:107D4B29 mov dx, [ecx+42h]
.text:107D4B2D cmp edx, 1
.text:107D4B30 jz short loc_107D4B4A
.text:107D4B32 push 1ECh
.text:107D4B37 push offset aWrite_c ; "write.c"
.text:107D4B3C push offset aTdTd_planarcon ; "td->td_planarconfig == PLANARCONFIG_CON"...
.text:107D4B41 call ds:_assert
...
.text:107D52CA mov edx, [ebp-4]
.text:107D52CD and edx, 3
.text:107D52D0 test edx, edx
.text:107D52D2 jz short loc_107D52E9
.text:107D52D4 push 58h
.text:107D52D6 push offset aDumpmode_c ; "dumpmode.c"
.text:107D52DB push offset aN30 ; "(n & 3) == 0"
.text:107D52E0 call ds:_assert
...
.text:107D6759 mov cx, [eax+6]
.text:107D675D cmp ecx, 0Ch
.text:107D6760 jle short loc_107D677A
.text:107D6762 push 2D8h
.text:107D6767 push offset aLzw_c ; "lzw.c"
.text:107D676C push offset aSpLzw_nbitsBit ; "sp->lzw_nbits <= BITS_MAX"
.text:107D6771 call ds:_assert最简单的分析方法就是用google来搜索条件和文件名。搜索结果显示这与开源的库文件有关。比如说,搜索字符串“sp->lzw_nbits <= BITS_MAX”,我们就它与压缩算法LZW的开源代码相关。
Chap59 常数
从二进制层面来看,更为常用的整数则是0xAAAAAAAA(1010101010101010)和0x55555555 (0101010101010101)这类特征明显的常量。以常数0x55AA为例:引导扇区、主引导扇区MBR以及IBM兼容扩展卡的ROM(只读存储单元)等关键数据都会使用这个常量。
一些算法,特别是某些加密算法,常常使用某些特殊的常数,如果我们使用调试工具IDA就能很容易发现这一点。
以MD5算法为例,其内部变量初始值分别是:
var int h0 := 0x67452301
var int h1 := 0xEFCDAB89
var int h2 := 0x98BADCFE
var int h3 := 0x10325476另外的例子则是CRC16/32的算法,其预置的常数表经常如下所示。
/** CRC table for the CRC-16. The poly is 0x8005 (x^16 + x^15 + x^2 + 1) */
u16 const crc16_table[256] = {
0x0000, 0xC0C1, 0xC181, 0x0140, 0xC301, 0x03C0, 0x0280, 0xC241,
0xC601, 0x06C0, 0x0780, 0xC741, 0x0500, 0xC5C1, 0xC481, 0x0440,
0xCC01, 0x0CC0, 0x0D80, 0xCD41, 0x0F00, 0xCFC1, 0xCE81, 0x0E40,-
很多文件在文件头使用特定的魔数来表示其文件格式,这些
magicNumber可以是一个或者多个字节的组合 -
标准的MIDI文件则必须以“MThd”这4个字符开头。
-
当然,数据比较函数同样可以用来验证文件头中的魔数。常用的函数有:比较内存块的memcmp()函数,或者CMPSB一类的比较指令(可以参考本书附录A.6.3)
一旦发现某个程序开始检测其他文件的魔数标识,我们就可以确信它已经加载了某种类型的目标文件。不止如此,我们还可以解读出文件操作的缓冲区以及它使用缓冲区的方式方法等信息。 -
网络协议同样使用了魔术。比如,DHCP协议的网络数据就会用到魔数0x63538263—这个魔数叫做magic cookie。所有符合DHCP协议的数据包都必须使用这个魔数。
我们以Windows 7操作系统(64位操作系统)中的文件dhcpcore.dll文件为例,我们可以在这个文件中搜索这个魔数。结果发现了2次,出现在两个函数中,其名称分别是DhcpExtractOptionsForValidation()和and DhcpExtractFullOptions()。
在单个文件里搜索常数时,可以使用IDA的搜索功能。其快捷键是ALT-B或ALT-I。
Chap60检索关键指令
如果一个程序使用了为数不多的FPU(Float Point Unit,浮点运算单元)指令,那么我们可以采用人工排查的方式把它们逐一筛选出来。
首先要用IDA加载Office 2010里的excel.exe(本章以版本号为14.0.4756.1000的excel为例),然后生成完整的指令清单并将其保存为后缀名为.lst的文本文件。接下来,我们就可以用终端指令检索指令清单中的全部FDIV指令(Floationg Point Divide,浮点数除法)。严格说来,使用grep不能检索出全部的浮点数除法运算指令。如果除数是常量,那么编译器就不太可能分配FDIV指令。当然这种特例不在我们的研究范围之内。
cat EXCEL.lst | grep fdiv | grep -v dbl_ > EXCEL.fdiv然后,我们在Excel里输入计算公式“=(1/3)”,并检查每个指令的运行结果。
在调试器(或tracer)里逐一排查除法运算指令以后,我们幸运地发现在第14个FDIV指令就是我们要找的指令:
Chap61可疑代码模型
-
XOR op,op或XOR EAX,EAX 通常用来将某个寄存器清零
当两个操作数不同才当做异或。往往在加密算法中比较常见
-
手写汇编
当前的编译器都不会分配循环指令LOOP和位移循环指令RCL。
手写的汇编程序很少会具备完整的函数开头和函数结尾。
通常来说,人工手写的程序没有固定的参数传递方法。
Chap62 魔数字与程序调试
向工程的主要目标理解程序处理数据的具体方法
手工跟踪一个值往往是一项非常劳神费力的事情。为了完成这个任务,一个最简单的方法是使用自己的特有魔数,虽然这个办法不是百分之百可靠。
魔数要尽量“打眼”(容易观察到)。在观测32位数据时,我们可以将魔数设置为0x0BADF00D(BADFOOD)
接着,我们可以利用tracer的代码覆盖率模式(code coverage/cc模式)跟踪程序,再利用grep或者直接搜索文本文件(跟踪结果的文本文件),我们就能够很容易地发现这些值的调用点及处理方法。
也许0xdeadbeef 不错
Chap63 Otherthing
-
逆向工程人员应当尽可能地以编程人员的角度来分析问题。要理解他们的观点、并且时常扪心自问:如果自己是编程人员的话,自己会如何设计程序。
-
在分析C++的class时,本书51.1.5节中讲到的RTTI数据可能就是分析的重点。
-
在十六进制的编辑器里,16位/32位/64位数据数组的特征十分明显。本节以一个很简单的MIPS程序为例。前文介绍过:每个MIPS指令都是整齐的32位(即4字节)指令。当然ARM模式或者ARM64模式的程序也有这个特点。因此,在形式上这些程序的指令都构成了某种32位数组。
-
内存“快照”的对比技术可以凸显出内存中变化的数据
可以直接使用
CheatEngine -
在安装一个程序以后,我们就能比对安装前后Windows的注册表。这是一个非常流行的方法,可以用来确认特定程序使用了哪些注册表键值。这也许就是“Windows注册表清理”程序颇为流行的原因。
Part.6 操作系统相关
Chap64.参数的传递方法
cdecl
-
C/C++最常使用的参数传递方法
-
参数从右往左传递
push arg3 push arg2 push arg1 call function add esp.12;
stdcall
与cdecl规范类似
不过被调用方函数在返回之前会指向ret x来还原参数栈
不需要在使用函数后add esp,x
这里的x=参数个数*指针大小
push arg3
push arg2
push arg1
call function
function:
...do something...
ret 12此类约定在Win32的标准库文件中十分常见。然而因为Win64系统遵循调用约定的是Win64规范,所以Win64的库文件里不会出现stdcall的标志性操作指令。
如果printf()函数当真采取了stdcall规范、根据格式化字符串统计变参的数量并且在函数尾声恢复栈指针,那么这种局面就十分危险了:万一程序员打错了几个字母,程序就会崩溃。由此可知,对于那些带有可变参数的函数而言,cdecl规范要比stdcall规范更好一些。
fastcall
这个调用约定优先使用寄存器传递参数,无法通过寄存器传递的参数则通过栈传递给被调用方函数。因为fastcall约定在内存栈方面的访问压力比较小,所以在早期的CPU平台上遵循fastcall规范的程序会比遵循stdcall和cdecl规范的程序性能更高。但是在现在的、更为复杂的CPU平台上,fastcall规范的性能优势就不那么明显了。
不管是MSVC还是GCC都使用ECX和EDX传递第一个和第二个参数,用栈传递其余的参数。此外,应由被调用方函数调整栈指针、把参数栈恢复到调用之前的初始状态(这一点与stdcall类似)。
push arg3
mov edx, arg2
mov ecx, arg1
call function
function:
.. do something ..
ret 4thiscall
这是一种方便C++类成员调用this指针而特别设定的调用规范。
MSVC使用ECX寄存器传递this指针。
而GCC则把this指针作为被调用方函数的第一个参数传递。在汇编层面,这个指针显而易见:所有的类函数都比源代码多出来一个参数。
64位下的x86
64位环境下的参数传递方法在某种程度上与fastcall函数比较类似:头四个参数由寄存器RCX、RDX、R8和R9传递,而其余的参数都通过栈来传递。调用方函数必须预留32个字节或者4个64位的存储空间,以便被调用方函数保存头四个参数。小型函数可以仅凭寄存器就获取所有参数,而大型函数就可能需要保存这些传递参数的寄存器,把它们腾挪出来供后续指令调用。
调用方函数负责调整栈指针到其初始状态。
此外,Windows x86-64系统的DLL文件也采用了这种调用规范。也就是说,虽然Win32系统API遵循的是stdcall规范,但是Win64系统遵循的是Win64规范、不再使用stdcall规范。
64位下Linux
64位Linux程序传递参数的方法和64位Windows程序的传递方法几乎相同。区别在于,64位Linux程序使用6个寄存器(RDI、RSI、RDX、RCX、R8、R9)传递前几项参数,而64位Windows则只利用4个寄存器传递参数。另外,64位Linux程序没有上面提到的“零散空间”这种概念。如果被调用方函数的寄存器数量紧张,它就可以用栈存储外来参数,把相关寄存器腾出来使用。
操作EAX寄存器的时候,它只把数据写到了RAX寄存器的低32位(即EAX)而没有直接操作整个64位RAX寄存器。这是因为:在操作寄存器的低32位的时候,该寄存器的高32位会被自动清零。
单双精度型返回值
除了Win64规范以外的所有的调用规范都规定:当返回值为单/双精度浮点型数据时,被调用方函数应当通过FPU寄存器ST(0)传递返回值。而Win64规范规定:被调用方函数应当**通过XMM0寄存器的低32位(float)或低64位寄存器(double)**返回单/双精度浮点型数据。
修改参数
如果被调用方函数修改了外来参数的值,将会发生什么情况?答案十分简单:外来参数都是通过栈传递的,因此被调用方函数修改的是栈里的数据。在被调用方函数退出以后,调用方函数不会再访问自己传递给别人的参数。
指针型函数参数
变量a的地址通过栈传递给了一个函数,然后这个地址又被传递给了另外一个函数。第一个函数修改了变量a的值,而后printf()函数获取到了这个修改后的变量值。
Chap65 线程本地存储TLS
线程本地存储(Thread Local Storage,TLS)是一种在线程内部共享数据的数据交换区域。每个线程都可以在这个区域保存它们要在内部共享的数据。一个比较知名的例子是C语言的全局变量errno。对于errno这类的全局变量来说,如果多线程进程的某一个线程对其进行了修改,那么这个变量就会影响到其他所有的线程。这显然和实际需求相悖,因此全局变量errno必须保存在TLS中。
#include <iostream>
#include <thread>
thread_local int tmp=3;
int main()
{
std::cout << tmp << std::endl;
};在分析可执行文件的PE头之后就会发现,变量tmp被分配到TLS专用的数据保存区域了
TLS回调
随机数发生器只有在正确初始化之后才会生成真实意义上的随机数,而不是1234这样的固定值。在这种情况下,可以采用TLS回调。
它只是构造一个在进程/线程启动前就被系统调用的回调函数(tls_callback())
Chap66系统调用
所有在操作系统中运行的进程可以分成两类:一类进程对具有硬件的全部访问权限,运行于内核空间(kernel space);另一类进程不能直接访问硬件地址,运行于用户空间(user space)。
由操作系统提供的系统调用(syscall)构成了ring0和ring 3之间的访问机制。可以说,系统调用就是操作系统为应用程序提供的应用编程接口API。
计算机病毒以及shellcode大多都会利用系统调用。这是因为系统库函数的寻址过程十分麻烦,而直接调用系统调用却相对简单。虽然系统调用的访问过程并不麻烦,但是由于系统调用本身属于底层API,因此直接使用系统调用的程序也不好写。另外需要注意的是:系统调用的总数由操作系统和系统版本两个因素共同决定的。
linux
Linux程序通常通过80号中断/INT 80调用系统调用。在调用系统调用时,程序应当通过EAX寄存器指定被调用函数的编号,再使用其他寄存器声明系统调用的参数。
section .text
global _start
_start:
mov edx,len ; buffer len
mov ecx,msg ; buffer
mov ebx,1 ; file descriptor. 1 is for stdout
mov eax,4 ; syscall number. 4 is for sys_write
int 0x80
mov eax,1 ; syscall number. 4 is for sys_exit
int 0x80
section .data
msg db 'Hello, world!',0xa
len equ $ - msgLinux系统调用表(x86_64) - 一川official - 博客园 (cnblogs.com)
windows
Windows程序可通过0x2e号中断/int 0x2e、或x86专用指令SYSENTER访问系统调用。
这里使用的中断数是0x2e,或者采用x86下的特殊指令SYSENTER。
深入浅出:64 位 Windows 中汇编系统调用的奥秘 - ByteZoneX社区
j00ru/windows-syscalls: Windows System Call Tables (NT/2000/XP/2003/Vista/7/8/10/11) (github.com)
Chap67 Linux
位置无关的代码
在分析Linux共享库文件(扩展名是so)时,我们经常会遇到具有下述特征的指令代码:
.text:0012D5E3 __x86_get_pc_thunk_bx proc near ; CODE XREF: sub_17350+3
.text:0012D5E3 ; sub_173CC+4 ...
.text:0012D5E3 mov ebx, [esp+0]
.text:0012D5E6 retn
.text:0012D5E6 __x86_get_pc_thunk_bx endp
...
.text:000576C0 sub_576C0 proc near ; CODE XREF: tmpfile+73
...
.text:000576C0 push ebp
.text:000576C1 mov ecx, large gs:0
.text:000576C8 push edi
.text:000576C9 push esi
.text:000576CA push ebx
.text:000576CB call __x86_get_pc_thunk_bx
.text:000576D0 add ebx, 157930h
.text:000576D6 sub esp, 9Ch
...
.text:000579F0 lea eax, (a__gen_tempname - 1AF000h)[ebx] ; "__gen_tempname"
.text:000579F6 mov [esp+0ACh+var_A0], eax
.text:000579FA lea eax, (a__SysdepsPosix - 1AF000h)[ebx] ; "../sysdeps/posix/tempname.c"
.text:00057A00 mov [esp+0ACh+var_A8], eax
.text:00057A04 lea eax, (aInvalidKindIn_ - 1AF000h)[ebx] ; "! \"invalid ↙
↘ KIND in __gen_tempname\""
.text:00057A0A mov [esp+0ACh+var_A4], 14Ah
.text:00057A12 mov [esp+0ACh+var_AC], eax
.text:00057A15 call __assert_fail所有字符串指针都被一些常数修正过,并且相关函数都在开始的几条指令里重新调整EBX中的值。
这类指令称作“位置无关的代码PIC(Position Independent Code)”
因为进程或对象会被操作系统的链接器加载到任意内存地址,所以代码里的指令无法直接确定(hardcoded)绝对内存地址。
Windows的DLL加载机制不是PIC机制。如果Windows加载器要把DLL加载到另外一个基地址,它就会内存中对DLL进行“修补”处理(重定位技术),从而可以正确地处理所有符号地址。这就意味着多个Windows进程无法在不同进程内存块的不同地址共享一份DLL,因为每个被加载在内存里的实例只能访问自己的地址空间。
LD_PRELOAD
Linux程序可以加载其他动态库之前、甚至在加载系统库(例如libc.so.6)之前加载自己的动态库。
借助这项功能,我们能够编写自定义的函数“替换”系统库中的同名函数。进一步说,劫持time()、read()、write()等系统函数并非难事。
chap68 WindowsNT
CRT
到原始入口OEP(Original Entry Point)总是指向其他的一段代码。这些代码会在启动程序之前进行一些维护和准备工作。这就是所谓的启动代码/startup-code即CRT代码(C RunTime)。
main()函数通过外来数组获取启动参数及系统的环境变量。然而,实际传递给程序的不是数组而是参数字符串。CRT代码会根据空格对字符串进行切割。另外,CRT代码还会通过envp数组向main()函数传递系统的环境变量。在Win32的GUI程序里,主函数变为了WinMain(),并且拥有自己的参数传递规格
int CALLBACK WinMain(
_In_ HINSTANCE hInstance,
_In_ HINSTANCE hPrevInstance,
_In_ LPSTR lpCmdLine,
_In_ int nCmdShow
);堆的初始化操作是由CRT代码完成的。若在没有CRT代码的情况下调用内存分配函数malloc(),就会引发异常退出,并将看到下述错误代码:
在C++程序中,CRT代码还要在启动主函数main()之前初始化全部全局对象。
PE
PE(Portable Executable)格式,是微软Windows环境可移植可执行文件(如exe、dll、vxd、sys和vdm等)的标准文件格式。
与其他格式的PE文件不同的是,exe和sys文件通常只有导入表而没有导出表。
和其他的PE文件一样,DLL文件也有一个原始代码入口点OEP(就是DllMain()函数的地址)。但是DLL的这个函数通常来讲什么也不会做。
sys文件通常来说是一个系统驱动程序。说到驱动程序,Windows操作系统需要在PE文件里保存其校验和,以验证该文件的正确性(Hiew就可以验证这个校验和)。
术语
- 模块Module:它是指一个单独的exe或者dll文件。
- 进程Process:加载到内存中并正在运行的程序,通常由一个exe文件和多个dll文件组成。
- 进程内存Process memory:每个进程都有完全属于自己的,进程间独立的,不被干扰的内存空间。 通常是模块、堆、栈等数据构成。
- 虚拟地址VA(Virtual Address):程序访问存储器所使用的逻辑地址。
- 基地址Base Address:进程内存中加载模块的首地址。
- 相对虚拟地址RVA(Relative Virtual Address):虚拟地址VA与基地址Base Address的差就是相对虚拟地址RVA。在PE文件表中的很多地址都是相对虚拟地址RVA。
- 导入地址表IAT(Import Address Table):导入符号的地址数组。PE头里的IMAGE_DIRECTORY_ ENTRY_IAT指向第一个导入地址表IAT的开始位置。值得说明的是,反编译工具IDA可能会给IAT虚构一个伪段–.idata段,即使IAT是其他地址的一部分。
- 导入符号名称表INT(Import Name Table):存储着所需符号名称的数组。
基地址
在开发各自的DLL动态链接库文件时,多数开发团队都有意让其他人直接调用自己的动态链接库。
因此,**当同一个进程的两个DLL库具有相同的基地址时,只会有一个DLL被真正加载到基地址上。而另外一个DLL则会分配到进程内存的某段空闲空间里。**在调用后者时,每个虚拟地址都会被重新校对。
通常来说,MSVC编译成的可执行程序的基地址都是0x400000,而代码段则从0x401000开始。由此可知,这种程序代码段的相对虚拟地址RVA的首地址都是0x1000。而MSVC通常把DLL的基地址设定为0x10000000。
操纵系统可能会把模块加载到不同的基地址中,还可能是因为程序自身的要求。当程序“点名”启用地址空间分布的随机化(Address Space Layout Randomization,ASLR)技术的时候,操作系统会把其各个模块加载到随机的基地址上。
子系统
PE文件有一个子系统字段。这个字段的值通常是下列之一:
- NATIVE(系统驱动程序)。
- console控制台程序。
- GUI(非控制台程序,也就是最常见的图文界面程序)。
段
所有的可执行文件都可分解为若干段(sections)。段是代码和数据、以及常量和其他数据的组织形式。
- 带有IMAGE_SCN_CNT_CODE或IMAGE_SCN_MEM_EXECUTE标识的段,封装的是可执行代码。
- 数据段的标识为IMAGE_SCN_CNT_INITIALIZED_DATA、IMAGE_SCN_MEM_READ或IMAGE_ SCN_MEM_WRITE标记。
- 未初始化的数据的空段的标识为IMAGE_SCN_CNT_UNINITIALIZED_DATA、IMAGE_SCN_ MEM_READ或IMAGE_SCN_MEM_WRITE。
- 常数数据段(其中的数据不可被重新赋值)的标识是IMAGE_SCN_CNT_ INITIALIZED_ DATA以及IMAGE_SCN_MEM_READ,但是不包括标识IMAGE_SCN_MEM_WRITE。如果进程试图往这个数据段写入数据,那么整个进程就会崩溃。
PE可执行文件的每个段都可以拥有一个段名称。然而,名称不是段的重要特征。通常来说,代码段的段名称是.text,数据段的段名称是.data,常数段的段名称.rdata(只读数据)。其他类型的常见段名称还有:
- .idata:导入段。IDA可能会给这个段分配一个伪名称;详情请参考本书68.2.1节。
- .edata:导出段。这个段十分罕见。
- .pdata:这个段存储的是用于异常处理的函数表项。它包含了Windors NT For MIPS、IA64以及x64所需的全部异常处理信息。详情请参考本书的68.3.3节。
- .reloc:(加载)重定向段。
- .bss:未初始化的数据段(BSS)。
- .tls:线程本地存储段(TLS)。
- .rsrc:资源。
- .CRT:在早期版本的MSVC编译出的可执行文件里,可能出现这个这个段。
经过加密或者压缩处理之后,PE文件section段的段名称通常会被替换或混淆。
部分编译器(例如MinGW)和链接器可以在生成的可执行文件中加入带有调试符号、或者其他的调试信息的独立段。然而新近版本的MSVC不再支持这项功能。为了便于专业人员分析和调试应用程序,MSVC推出了全称为“程序数据库”的PDB文件格式。
PE格式的section段的数据结构大体如下:
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;感觉讲的不怎么行
跳了
TLS
这个段里存储了TLS数据(第65章)的初始化数据(如果需要的话)。当启动一个新的线程时,TLS的数据就是通过本段的数据来初始化的。
除此之外,PE文件规范还约定了“TLS!”的初始化规范,即TLS callbacks/TLS回调函数。如果程序声明了TLS回调函数,那么TLS回调函数会先于OEP执行。
SEH
每个运行的进程都有一条SEH句柄链,线程信息块(Thread Information Block,TIB)有SHE的最后一个句柄。当出现异外时(比如出现了被零除、地址访问不正确或者程序主动调用RaiseException()函数等情况),操作系统会在线程信息块TIB里寻找SEH的最后一个句柄。并且把出现异常情况时与CPU有关的所有状态(包括寄存器的值等数据)传递给那个SEH句柄。此时异常处理函数开始判断自己能否应对这种异常情况。如果答案是肯定的,那么异常处理函数就会着手接管。如果异常处理函数无法处理这种情况,它就会通知操作系统无法处理它,此后操作系统会逐一尝试异常处理链中的其他处理程序,直到找到能够应对这种情况的异常处理程序为止。