基础
从C进阶C++的时候,我不会的语法知识点的记录(摘录自菜鸟教程)
后续会随着看C++ Primer慢慢完善
左右值
C++ 中的左值(Lvalues)和右值(Rvalues)
C++ 中有两种类型的表达式:
- **左值(lvalue):**指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
- **右值(rvalue):**术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。
Const 关键字
您可以使用 const 前缀声明指定类型的常量,如下所示:
const type variable = value;C++ 中的类型限定符
类型限定符提供了变量的额外信息,用于在定义变量或函数时改变它们的默认行为的关键字。
| 限定符 | 含义 |
|---|---|
| const | const 定义常量,表示该变量的值不能被修改。 |
| volatile | 修饰符 volatile 告诉该变量的值可能会被程序以外的因素改变,如硬件或其他线程。。 |
| restrict | 由 restrict 修饰的指针是唯一一种访问它所指向的对象的方式。只有 C99 增加了新的类型限定符 restrict。 |
| mutable | 表示类中的成员变量可以在 const 成员函数中被修改。 |
| static | 用于定义静态变量,表示该变量的作用域仅限于当前文件或当前函数内,不会被其他文件或函数访问。 |
| register | 用于定义寄存器变量,表示该变量被频繁使用,可以存储在CPU的寄存器中,以提高程序的运行效率。 |
const 实例
const int NUM = 10; // 定义常量 NUM,其值不可修改
const int* ptr = # // 定义指向常量的指针,指针所指的值不可修改
int const* ptr2 = # // 和上面一行等价volatile 实例
volatile int num = 20; // 定义变量 num,其值可能会在未知的时间被改变mutable 实例
class Example {
public:
int get_value() const {
return value_; // const 关键字表示该成员函数不会修改对象中的数据成员
}
void set_value(int value) const {
value_ = value; // mutable 关键字允许在 const 成员函数中修改成员变量
}
private:
mutable int value_;
};static 实例
void example_function() {
static int count = 0; // static 关键字使变量 count 存储在程序生命周期内都存在
count++;
}register 实例
void example_function(register int num) {
// register 关键字建议编译器将变量 num 存储在寄存器中
// 以提高程序执行速度
// 但是实际上是否会存储在寄存器中由编译器决定
}C++ 存储类
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C++ 程序中可用的存储类:
- auto:这是默认的存储类说明符,通常可以省略不写。auto 指定的变量具有自动存储期,即它们的生命周期仅限于定义它们的块(block)。auto 变量通常在栈上分配。
- register:用于建议编译器将变量存储在CPU寄存器中以提高访问速度。在 C++11 及以后的版本中,register 已经是一个废弃的特性,不再具有实际作用。
- static:用于定义具有静态存储期的变量或函数,它们的生命周期贯穿整个程序的运行期。在函数内部,static变量的值在函数调用之间保持不变。在文件内部或全局作用域,static变量具有内部链接,只能在定义它们的文件中访问。
- extern:用于声明具有外部链接的变量或函数,它们可以在多个文件之间共享。默认情况下,全局变量和函数具有 extern 存储类。在一个文件中使用extern声明另一个文件中定义的全局变量或函数,可以实现跨文件共享。
- mutable (C++11):用于修饰类中的成员变量,允许在const成员函数中修改这些变量的值。通常用于缓存或计数器等需要在const上下文中修改的数据。
- thread_local (C++11):用于定义具有线程局部存储期的变量,每个线程都有自己的独立副本。线程局部变量的生命周期与线程的生命周期相同。
从 C++ 17 开始,auto 关键字不再是 C++ 存储类说明符,且 register 关键字被弃用。
中的存储类说明符为程序员提供了控制变量和函数生命周期及可见性的手段。
合理使用存储类说明符可以提高程序的可维护性和性能。
从 C++11 开始,register 已经失去了原有的作用,而 mutable 和 thread_local 则是新引入的特性,用于解决特定的编程问题。
#include <iostream>
// 全局变量,具有外部链接,默认存储类为extern
int globalVar;
void function() {
// 局部变量,具有自动存储期,默认存储类为auto
auto int localVar = 10;
// 静态变量,具有静态存储期,生命周期贯穿整个程序
static int staticVar = 20;
const int constVar = 30; // const变量默认具有static存储期
// 尝试修改const变量,编译错误
// constVar = 40;
// mutable成员变量,可以在const成员函数中修改
class MyClass {
public:
mutable int mutableVar;
void constMemberFunc() const {
mutableVar = 50; // 允许修改mutable成员变量
}
};
// 线程局部变量,每个线程有自己的独立副本
thread_local int threadVar = 60;
}
int main() {
extern int externalVar; // 声明具有外部链接的变量
function();
return 0;
}auto 存储类
自 C++ 11 以来,auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断该变量的类型、声明函数时函数返回值的占位符。
C98 标准中 auto 关键字用于自动变量的声明,但由于使用极少且多余,在 C17 中已删除这一用法。
根据初始化表达式自动推断被声明的变量的类型,如:
auto f=3.14; //double auto s(“hello”); //const char* auto z = new auto(9); // int* auto x1 = 5, x2 = 5.0, x3=‘r’;//错误,必须是初始化为同一类型
register 存储类
register 是一种存储类(storage class),用于声明变量,并提示编译器将这些变量存储在寄存器中,以便快速访问。
使用 register 关键字可以提高程序的执行速度,因为它减少了对内存的访问次数。
然而,需要注意的是,register 存储类只是一种提示,编译器可以忽略它,因为现代的编译器通常会自动优化代码,选择合适的存储位置。
语法格式:
register data_type variable_name;register是存储类的关键字,用于提示编译器将变量存储在寄存器中。data_type是变量的数据类型,可以是任何合法的 C++ 数据类型。variable_name是变量的名称。
void loop()
{
register int i;
for (i = 0; i < 1000; ++i)
{ // 循环体
}
}register 存储类用于提示编译器将变量存储在寄存器中,以便提高访问速度。然而,由于现代编译器的自动优化能力,使用 register 关键字并不是必需的,而且在实践中很少使用。
在 C11 标准中,register 关键字不再是一个存储类说明符,而是一个废弃的特性。这意味着在 C11 及以后的版本中,使用 register 关键字将不会对程序产生任何影响。
在 C++ 中,可以使用引用或指针来提高访问速度,尤其是在处理大型数据结构时。
static 存储类
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
在 C++ 中,当 static 用在类数据成员上时,会导致仅有一个该成员的副本被类的所有对象共享。
#include <iostream>
// 函数声明
void func(void);
tatic int count = 10; /* 全局变量 */
int main() {
while(count--)
{ func(); }
return 0;
}
// 函数定义
void func( void ) {
static int i = 5;
// 局部静态变量
i++;
std::cout << "变量 i 为 " << i ;
std::cout << " , 变量 count 为 " << count << std::endl; }当上面的代码被编译和执行时,它会产生下列结果:
变量 i 为 6 , 变量 count 为 9
变量 i 为 7 , 变量 count 为 8
变量 i 为 8 , 变量 count 为 7
变量 i 为 9 , 变量 count 为 6
变量 i 为 10 , 变量 count 为 5
变量 i 为 11 , 变量 count 为 4
变量 i 为 12 , 变量 count 为 3
变量 i 为 13 , 变量 count 为 2
变量 i 为 14 , 变量 count 为 1
变量 i 为 15 , 变量 count 为 0extern 存储类
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 ‘extern’ 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
当您有多个文件且定义了一个可以在其他文件中使用的全局变量或函数时,可以在其他文件中使用 extern 来得到已定义的变量或函数的引用。可以这么理解,extern 是用来在另一个文件中声明一个全局变量或函数。
extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候,如下所示:
#include <iostream>
int count ;
extern void write_extern();
int main() {
count = 5;
rite_extern();
}#include <iostream>
extern int count;
void write_extern(void) {
std::cout << "Count is " << count << std::endl;
}在这里,第二个文件中的 extern 关键字用于声明已经在第一个文件 main.cpp 中定义的 count。现在 ,编译这两个文件,如下所示:
$ g++ main.cpp support.cpp -o write这会产生 write 可执行程序,尝试执行 write,它会产生下列结果:
$ ./write
Count is 5mutable 存储类
mutable 说明符仅适用于类的对象,这将在本教程的最后进行讲解。它允许对象的成员替代常量。也就是说,mutable 成员可以通过 const 成员函数修改。
thread_local 存储类
使用 thread_local 说明符声明的变量仅可在它在其上创建的线程上访问。 变量在创建线程时创建,并在销毁线程时销毁。 每个线程都有其自己的变量副本。
thread_local 说明符可以与 static 或 extern 合并。
可以将 thread_local 仅应用于数据声明和定义,thread_local 不能用于函数声明或定义。
以下演示了可以被声明为 thread_local 的变量:
thread_local int x;
// 命名空间下的全局变量
class X {
static thread_local std::string s;
// 类的static成员变量 }
; static thread_local std::string X::s;
// X::s 是需要定义的
void foo()
{
thread_local std::vector<int> v;
// 本地变量
}typedef 关键字
下面是一种更简单的定义结构的方式,您可以为创建的类型取一个"别名"。例如:
typedef struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
}Books;现在,您可以直接使用 Books 来定义 Books 类型的变量,而不需要使用 struct 关键字。下面是实例:
Books Book1, Book2;您可以使用 typedef 关键字来定义非结构类型,如下所示:
typedef long int *pint32;
pint32 x, y, z;x, y 和 z 都是指向长整型 long int 的指针。
容器
C++ vector 容器
C++ 中的 vector 是一种序列容器,它允许你在运行时动态地插入和删除元素。
vector 是基于数组的数据结构,但它可以自动管理内存,这意味着你不需要手动分配和释放内存。
与 C++ 数组相比,vector 具有更多的灵活性和功能,使其成为 C++ 中常用的数据结构之一。
vector 是 C++ 标准模板库(STL)的一部分,提供了灵活的接口和高效的操作。
基本特性:
- 动态大小:
vector的大小可以根据需要自动增长和缩小。 - 连续存储:
vector中的元素在内存中是连续存储的,这使得访问元素非常快速。 - 可迭代:
vector可以被迭代,你可以使用循环(如for循环)来访问它的元素。 - 元素类型:
vector可以存储任何类型的元素,包括内置类型、对象、指针等。
使用场景:
- 当你需要一个可以动态增长和缩小的数组时。
- 当你需要频繁地在序列的末尾添加或移除元素时。
- 当你需要一个可以高效随机访问元素的容器时。
要使用 vector,首先需要包含``
#include <vector>创建 Vector
创建一个 vector 可以像创建其他变量一样简单:
std::vector<int> myVector; // 创建一个存储整数的空 vector这将创建一个空的整数向量,也可以在创建时指定初始大小和初始值:
std::vector<int> myVector(5); // 创建一个包含 5 个整数的 vector,每个值都为默认值(0)
std::vector<int> myVector(5, 10); // 创建一个包含 5 个整数的 vector,每个值都为 10或:
std::vector<int> vec; // 默认初始化一个空的 vector
std::vector<int> vec2 = {1, 2, 3, 4}; // 初始化一个包含元素的 vector添加元素
可以使用 push_back 方法向 vector 中添加元素:
myVector.push_back(7); // 将整数 7 添加到 vector 的末尾访问元素
可以使用下标操作符 [] 或 at() 方法访问 vector 中的元素:
int x = myVector[0]; // 获取第一个元素
int y = myVector.at(1); // 获取第二个元素获取大小
可以使用 size() 方法获取 vector 中元素的数量:
int size = myVector.size(); // 获取 vector 中的元素数量迭代访问
可以使用迭代器遍历 vector 中的元素:
for (auto it = myVector.begin(); it != myVector.end(); ++it) {
std::cout << *it << " ";
}或者使用范围循环:
for (int element : myVector) {
std::cout << element << " ";
}删除元素
可以使用 erase() 方法删除 vector 中的元素:
myVector.erase(myVector.begin() + 2); // 删除第三个元素清空 Vector
可以使用 clear() 方法清空 vector 中的所有元素:
myVector.clear(); // 清空 vector实例
以下是一个完整的使用实例,包括创建 vector、添加元素、访问元素以及输出结果的代码:
#include <iostream>
#include <vector>
int main() {
// 创建一个空的整数向量
std::vector<int> myVector;
// 添加元素到向量中
myVector.push_back(3);
myVector.push_back(7);
myVector.push_back(11);
myVector.push_back(5);
// 访问向量中的元素并输出
std::cout << "Elements in the vector: ";
for (int element : myVector) {
std::cout << element << " ";
}
std::cout << std::endl;
// 访问向量中的第一个元素并输出
std::cout << "First element: " << myVector[0] << std::endl;
// 访问向量中的第二个元素并输出
std::cout << "Second element: " << myVector.at(1) << std::endl;
// 获取向量的大小并输出
std::cout << "Size of the vector: " << myVector.size() << std::endl;
// 删除向量中的第三个元素
myVector.erase(myVector.begin() + 2);
// 输出删除元素后的向量
std::cout << "Elements in the vector after erasing: ";
for (int element : myVector) {
std::cout << element << " ";
}
std::cout << std::endl;
// 清空向量并输出
myVector.clear();
std::cout << "Size of the vector after clearing: " << myVector.size() << std::endl;
return 0;
}以上代码创建了一个整数向量,向其中添加了几个元素,然后输出了向量的内容、元素的访问、向量的大小等信息,接着删除了向量中的第三个元素,并输出删除元素后的向量。最后清空了向量,并输出清空后的向量大小。
输出结果为:
Elements in the vector: 3 7 11 5
First element: 3
Second element: 7
Size of the vector: 4
Elements in the vector after erasing: 3 7 5
Size of the vector after clearing: 0面向对象
类和对象
| 概念 | 描述 |
|---|---|
| 类成员函数 | 类的成员函数是指那些把定义和原型写在类定义内部的函数,就像类定义中的其他变量一样。 |
| 类访问修饰符 | 类成员可以被定义为 public、private 或 protected。默认情况下是定义为 private。 |
| 构造函数 & 析构函数 | 类的构造函数是一种特殊的函数,在创建一个新的对象时调用。类的析构函数也是一种特殊的函数,在删除所创建的对象时调用。 |
| C++ 拷贝构造函数 | 拷贝构造函数,是一种特殊的构造函数,它在创建对象时,是使用同一类中之前创建的对象来初始化新创建的对象。 |
| C++ 友元函数 | 友元函数可以访问类的 private 和 protected 成员。 |
| C++ 内联函数 | 通过内联函数,编译器试图在调用函数的地方扩展函数体中的代码。 |
| C++ 中的 this 指针 | 每个对象都有一个特殊的指针 this,它指向对象本身。 |
| C++ 中指向类的指针 | 指向类的指针方式如同指向结构的指针。实际上,类可以看成是一个带有函数的结构。 |
| C++ 类的静态成员 | 类的数据成员和函数成员都可以被声明为静态的。 |
继承
继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。这样做,也达到了重用代码功能和提高执行效率的效果。
当创建一个类时,您不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。
继承代表了 is a 关系。例如,哺乳动物是动物,狗是哺乳动物,因此,狗是动物
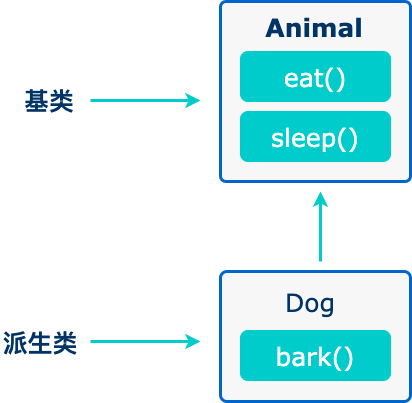
// 基类
class Animal {
// eat() 函数
// sleep() 函数
};
//派生类
class Dog : public Animal {
// bark() 函数
};基类&派生类
一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表来指定基类。类派生列表以一个或多个基类命名,形式如下:
class derived-class: access-specifier base-class其中,访问修饰符 access-specifier 是 public、protected 或 private 其中的一个,base-class 是之前定义过的某个类的名称。如果未使用访问修饰符 access-specifier,则默认为 private。
访问控制和继承
派生类可以访问基类中所有的非私有成员。因此基类成员如果不想被派生类的成员函数访问,则应在基类中声明为 private。
我们可以根据访问权限总结出不同的访问类型,如下所示:
| 访问 | public | protected | private |
|---|---|---|---|
| 同一个类 | yes | yes | yes |
| 派生类 | yes | yes | no |
| 外部的类 | yes | no | no |
一个派生类继承了所有的基类方法,但下列情况除外:
- 基类的构造函数、析构函数和拷贝构造函数。
- 基类的重载运算符。
- 基类的友元函数。
继承类型
当一个类派生自基类,该基类可以被继承为 public、protected 或 private 几种类型。继承类型是通过上面讲解的访问修饰符 access-specifier 来指定的。
我们几乎不使用 protected 或 private 继承,通常使用 public 继承。当使用不同类型的继承时,遵循以下几个规则:
- 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基类的公有和保护成员来访问。
- 保护继承(protected): 当一个类派生自保护基类时,基类的公有和保护成员将成为派生类的保护成员。
- 私有继承(private):当一个类派生自私有基类时,基类的公有和保护成员将成为派生类的私有成员
多继承
多继承即一个子类可以有多个父类,它继承了多个父类的特性。
C++ 类可以从多个类继承成员,语法如下:
class <派生类名>:<继承方式1><基类名1>,<继承方式2><基类名2>,…
{
<派生类类体>
};其中,访问修饰符继承方式是 public、protected 或 private 其中的一个,用来修饰每个基类,各个基类之间用逗号分隔
重载
函数重载
在同一个作用域内,可以声明几个功能类似的同名函数,但是这些同名函数的形式参数(指参数的个数、类型或者顺序)必须不同。您不能仅通过返回类型的不同来重载函数。
#include <iostream>
using namespace std;
class printData
{
public:
void print(int i){
cout << "整数为:"<<i<<endl;
}
void print(double f){
cout << "浮点数为: "<<f<<endl;
}
}运算符重置
您可以重定义或重载大部分 C++ 内置的运算符。这样,您就能使用自定义类型的运算符。
重载的运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。与其他函数一样,重载运算符有一个返回类型和一个参数列表。
Box operator+(const Box&);声明加法运算符用于把两个 Box 对象相加,返回最终的 Box 对象。大多数的重载运算符可被定义为普通的非成员函数或者被定义为类成员函数。如果我们定义上面的函数为类的非成员函数,那么我们需要为每次操作传递两个参数,如下所示:
Box operator+(const Box&, const Box&);可/不可重载运算符
下面是可重载的运算符列表:
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
|---|---|
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于),<=(小于等于),>=(大于等于) |
| 逻辑运算符 | ||(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),–(自减) |
| 位运算符 | | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, |=, ^=, <<=, >>= |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号),[](下标) |
下面是不可重载的运算符列表:
- .:成员访问运算符
- .*, ->*:成员指针访问运算符
- :::域运算符
- sizeof:长度运算符
- ?::条件运算符
- #: 预处理符号
多态
多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。
C++ 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。
虚函数
虚函数 是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。
我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定。
纯虚函数
您可能想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是您在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数。
我们可以把基类中的虚函数 area() 改写如下:
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{ width = a;
height = b;
} // pure virtual function
virtual int area() = 0;
};
= 0 告诉编译器,函数没有主体,上面的虚函数是纯虚函数。
数据抽象
数据封装(Data Encapsulation)是面向对象编程(OOP)的一个基本概念,它通过将数据和操作数据的函数封装在一个类中来实现。这种封装确保了数据的私有性和完整性,防止了外部代码对其直接访问和修改。
所有的 C++ 程序都有以下两个基本要素:
- **程序语句(代码):**这是程序中执行动作的部分,它们被称为函数。
- **程序数据:**数据是程序的信息,会受到程序函数的影响。
封装是面向对象编程中的把数据和操作数据的函数绑定在一起的一个概念,这样能避免受到外界的干扰和误用,从而确保了安全。数据封装引申出了另一个重要的 OOP 概念,即数据隐藏。
数据封装是一种把数据和操作数据的函数捆绑在一起的机制,数据抽象是一种仅向用户暴露接口而把具体的实现细节隐藏起来的机制。
C++ 通过创建类来支持封装和数据隐藏(public、protected、private)。我们已经知道,类包含私有成员(private)、保护成员(protected)和公有成员(public)成员。默认情况下,在类中定义的所有项目都是私有的。例如:
把一个类定义为另一个类的友元类,会暴露实现细节,从而降低了封装性。理想的做法是尽可能地对外隐藏每个类的实现细节。
访问修饰符:
- private: 私有成员只能在类的内部访问,不能被类的外部代码直接访问。
- public: 公有成员可以被类的外部代码直接访问。
- protected: 受保护成员可以被类和其派生类访问。
类的封装(抽象)
设计策略
面向对象的系统可能会使用一个抽象基类为所有的外部应用程序提供一个适当的、通用的、标准化的接口。然后,派生类通过继承抽象基类,就把所有类似的操作都继承下来。
外部应用程序提供的功能(即公有函数)在抽象基类中是以纯虚函数的形式存在的。这些纯虚函数在相应的派生类中被实现。
这个架构也使得新的应用程序可以很容易地被添加到系统中,即使是在系统被定义之后依然可以如此。