https://zhuanlan.zhihu.com/p/261735714
[原创]STL容器逆向与实战(N1CTF2022 cppmaster wp)-CTF对抗-看雪-安全社区|安全招聘|kanxue.com
About
最近遇到suctf的mapmap2,发现我对stl逆向一无所知,今天深入了解一下
这篇文章主要是已有资料的一些总结,参考文章写的是真好orz
逆向stl往往需要三步走
- 识别 STL 容器类型
- 识别 STL 容器操作
- 提取 STL 容器中的数据
遇到的困难存在
- 缺少符号,无法判断 STL 容器类型
- STL 内部数据结构复杂,难以提取数据
- 优化使大量 stl 函数被 inline
比较有效的方法:解析 STL 容器内存数据,从内存数据角度判断容器类型,提取容器内容判断函数操作。
STL的分类
顺序容器
| 容器 | 简介说明 |
|---|---|
| vector | 可变大小数组。相当于数组,可动态构建,支持随机访问,无头插和尾插,仅支持inset插入,除尾部外的元素删除比较麻烦。但使用最为广泛 |
| deque | 双端队列。支持头插、删,尾插、删,随机访问较vector容器来说慢,但对于首尾的数据操作比较方便 |
| list | 双向循环链表。使用起来很高效,对于任意位置的插入和删除都很快,在操作过后,以后指针、迭代器、引用都不会失效 |
| forward_list | 单向链表。只支持单向访问,在链表的任何位置进行插入/删除操作都非常快 |
| array | 固定数组。vector的底层即为array数组,它保存了一个以严格顺序排列的特定数量的元素 |
关联式容器
有序关联容器
| 容器 | 简介说明 |
|---|---|
| set/mutliset | 集合/多重集合。对于set,在使用insert插入元素时,已插入过的元素不可重复插入,这正好符合了集合的互异性,在插入完成显示后,会默认按照升序进行排序,对于multiset ,可插入多个重复的元素 |
| map/mutlimap | 映射/多重映射。二者均为二元关联容器(在构造时需要写两个参数类型,前者对key值,后者对应value值),因为有两个参数,因此在插入元素的时候需要配合对组pair进行插入,具体见深入详解 |
无序关联容器
| 容器 | 简介说明 |
|---|---|
| unorderedset/unordered_mutliset | 集合/多重集合。对于set,在使用insert插入元素时,已插入过的元素不可重复插入,这正好符合了集合的互异性,在插入完成显示后,会默认按照升序进行排序,对于multiset ,可插入多个重复的元素 |
| unordered_map/unordered_mutlimap | 映射/多重映射。二者均为二元关联容器(在构造时需要写两个参数类型,前者对key值,后者对应value值),因为有两个参数,因此在插入元素的时候需要配合对组pair进行插入,具体见深入详解 |
容器适配器
| 容器 | 简介说明 |
|---|---|
| stack | 堆栈。其原理是先进后出(FILO),其底层容器可以是任何标准的容器适配器,默认为deque双端队列 |
| queue | 队列。其原理是先进先出(FIFO),只有队头和队尾可以被访问,故不可有遍历行为,默认也为deque双端队列 |
| pirority_queue | 优先队列。它的第一个元素总是它所包含的元素中优先级最高的,就像数据结构里的堆,会默认形成大堆,还可以使用仿函数来控制生成大根堆还是生成小根堆,若没定义,默认使用vector容器 |
STL符号逆向
- ida flirt 找到对应版本的sig文件,可以恢复大部分符号
- 跑一下lumen 能恢复一些符号
- 结合容器类型,动调猜测大概属于什么operation
- 静态结合源码分析
STL数据逆向
由于msvc,gcc,clang中的stl实现,以及各个版本的cpp实现都不太相同,所以我们很难确定内存模型是一定不变的,一定情况下要结合对应版本的源码分析
https://github.com/gcc-mirror/gcc
https://github.com/microsoft/STL
https://github.com/llvm/llvm-project/tree/69ead949d08ff0bb8cbbf4f7143aaa6687830f6b/libcxx/include
但是绝大部分情况下,内存模型是差不多的,我们以clang的为例进行分析
dump数据结构的内存模型
以下stl数据结构定义是简化版定义
clang/gnu
看雪的那篇文章已经给出了
msvs
cl编译器存在未公开的参数
/d1reportSingleClassLayoutXXX 显示指定XXX类的内存布局
/d1reportAllClassLayou 显示所有类的内存布局
cl /d1reportSingleClassLayoutB test.cpp
class B size(8):
+---
0 | {vfptr}
| +--- (base class A)
4 | | a
| +---
+---
B::$vftable@:
| &B_meta
| 0
0 | &B::doX
B::doX this adjustor: 0 把llvm的stl放到windows解析应该也行
std::string
string的结构比较简单。主要由一个指针ptr和字符串长度string_length构成。除此之外还会存在一个联合体,当字符串的长度小于8时会直接存储与这个缓冲区中,此时ptr指针将指向这个local_buf,大于这个local_buf将会在堆上另外分配内存,此时这个union转而用于存储分配堆的大小。
struct basic_string
{
char *begin_; // actual string data
size_t size_; // actual size
union{
size_t capacity_; // used if larger than 15 bytes
char sso_buffer[16];// used if smaller than 16 bytes};
};
小字符串不用在堆上分配

dump脚本
def read_dbg_cppstr_64(objectAddr):
# a easy function for read std:string
# 首地址就是begin指针
strPtr = idc.get_bytes(objectAddr,8)
result = ''
i = 0
while True:
onebyte = idc.get_bytes(strPtr + i,1)
if onebyte == 0:
break
else:
result = chr(onebyte)
i += 1
return resultstd::stringsteam
struct stringsteam{
void * vtable1;// std::basic stringstream
int64 pad;
void * vtable2;//std::basic stringstream
void * vtable3;// std::stringbuf
char * _M_in_beg; // 输入流开始
char * _M in_cur;
char * _M in_end;
char * _M_out_beg;// 输出流开始
char * _M_out_cur;// 输出流开始
char * _M_out_end;// 输出流开始
};std::vector
- 固定长度 24 字节,3 个 dq
- 第一个指针字段指向数组起始地址
- 第二个指针字段指向数组最后元素地址
- 第三个指针字段指向最大内存地址
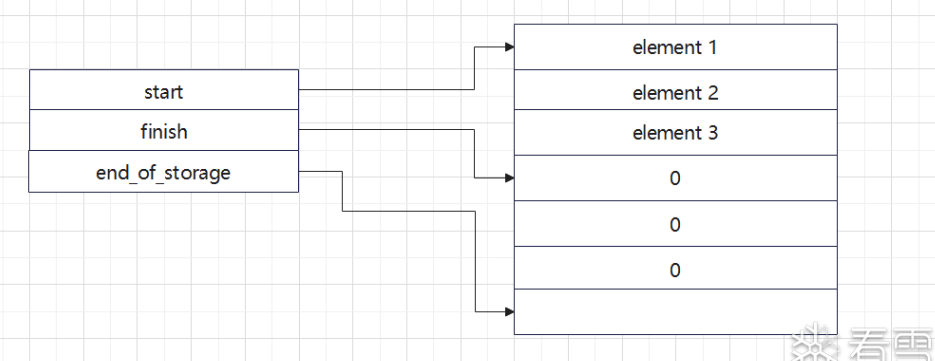
struct vector
{
void * start;
void * end;
void * max;
};dump脚本
def vetor_dump(addr):
ELEMENT_SIZE = 8
data_addr = []
data=[]
vetor_base = idc.read_dbg_qword(addr + 0x0)
vetor_end = idc.read_dbg_qword(addr + 0x8)
for i in range(vetor_base,vetor_end,ELEMENT_SIZE):
data_addr.append(i)
data.append(idc.get_bytes(i,ELEMENT_SIZE))
return data_addr,datastd::list
- 双向循环链表存储
- 头结构 + 节点结构
- 遍历长度可以用 size 字段确定
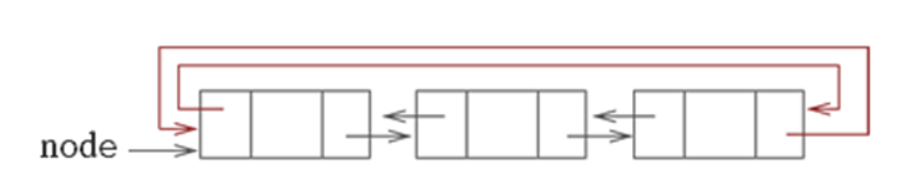
struct List_node
{
List_node* next;
List_node* prev;
//data区域
};
struct List_node_header
{
List_node* next;
List_node* prev;
size_t SIZE;
};dump脚本
def dump_stl_list(p_list_addr):
data_addr = []
data=[] #data要具体判断
list_size = idc.read_dbg_qword(p_list_addr+0x10)
cur_node = p_list_addr
for i in range(list_size):
cur_node = idc.read_dbg_qword(cur_node + 0x0)
data_addr.append(cur_node + 0x10)std::deque/stack
deque是queue,stack,deque等线性容器的底层实现
主要分为三个部分,
第一个用于描述map的,其中包含map大小和map的指针,
第二个则是指向deque中起始元素的Deque_iterator,
第三个则是指向了deque中结束元素的Deque_iterator。
struct stl_deque_iterator{
void * cur;
void * first;
void * last;
void * node;
};
struct stl_deque{
void * map;
size_t map_size;
stl_deque_iterator start;
stl_deque_iterator finish;
};
deque对元素的保存采取了分块保存的机制。deque采用一块连续的内存保存了一系列的指针。其中map即指向这一块连续的内存,换句话说map是一个指针,指向一个指针数组。而这个指针数组中的指针指向的则是一篇连续的,用于实际保存数据的内存区域,我们称为data array(每个元素的大小取决于deque中的模板类型),具体的内存示意图可以如下图所示。
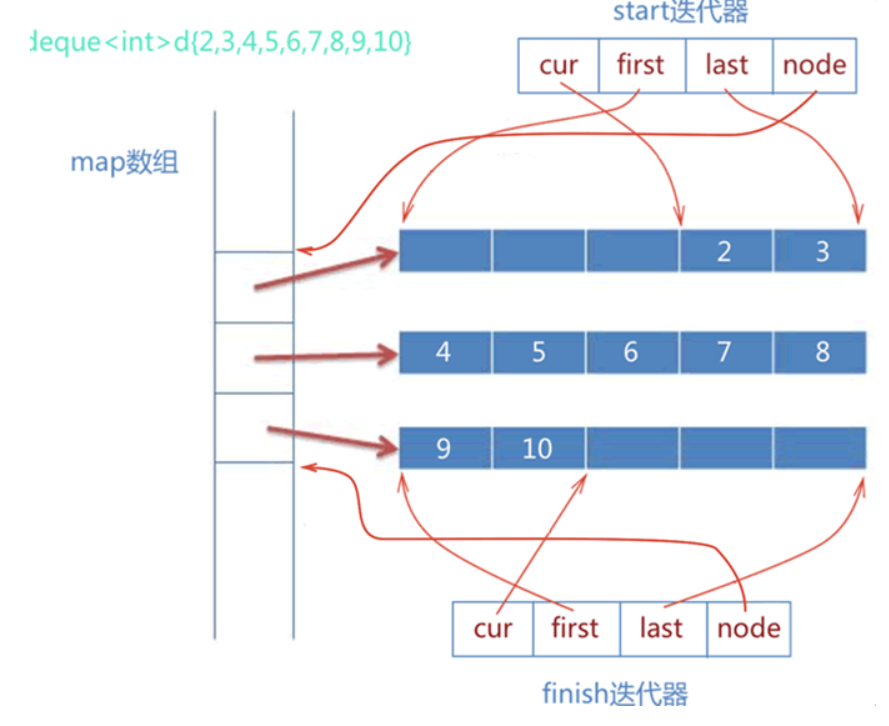
- stl_deque.start.node 确定first map 项位置
- stl_deque.start.last - stl_deque.start.first 确定缓冲区大小
- stl_deque.finish.node 确定last map 项位置
- 对于每一个 map 项:
- start 项,解析 cur, last 区间
- finish 项,解析 start, cur 区间
- 其余项,解析 start, last 区间
dump脚本
'''
struct stl_deque_iterator{
void * cur;
void * first;
void * last;
void * node;
};
struct stl_deque{
void * map;
size_t map_size;
stl_deque_iterator start;
stl_deque_iterator finish;
};
'''
deque_iter = namedtuple('deque_iter',['cur','first','last','node'])
def parse_iter(addr):
# 解析队列迭代器
cur = idc.read_dbg_qword(addr + 0x0)
first = idc.read_dbg_qword(addr + 0x8)
last = idc.read_dbg_qword(addr + 0x10)
node = idc.read_dbg_qword(addr + 0x18)
return deque_iter(cur,first,last,node)
def dump_deque(addr):
ELEMENT_SIZE = 4 # std::deque<xx> xx 的类型大小来指定
data_addr = []
start_iter = parse_iter(addr + 0x10)
finish_iter = parse_iter(addr + 0x30)
buf_size = start_iter.last - start_iter.first
map_size = start_iter.node
map_finish = finish_iter.node
# 解析第一个缓存数据
for i in range(start_iter.cur,start_iter.last,ELEMENT_SIZE):
data_addr.append(i)
# 解析中间缓存数据
for i in range(map_start + 8,map_finish - 8,8):
buf_start = idc.read_dbg_qword(b)
for i in range(buf_start,buf_start + buf_size, ELEMENT_SIZE):
data_addr.append(i)
# 解析最后一个缓存数据
for i in range(finish_iter.first,finish_iter.cur,ELEMENT_SIZE):
data_addr.append(i)
return data_addrstd::unordered_map/set(hashtable)
- 底层采用 HashTable 实现
- 头结构 + Bucket 数组 + 节点结构
- 所有节点结构用单链表串联(****dump 只需要遍历单链表)
- 头结构的第三个字段为单链表头
- 适用std::unsorted_map/ std::unsorted_set / …
简化结构体定义
struct bucket{
bucket * next; //最后一个node为NULL
valtype val;
size_t hash;
};
struct hashmap{
bucket * buckets;
size_t buckets_count;
bucket * first;
size_t elements_count;
};- 当bucket为空时,该bucket指针为null
- 每个哈希容器有一个哨兵节点(_M_before_begin),作为使用迭代器遍历容器的起点。
- 每一个bucket链表的最后一个结点,同时又是某一个bucket的哨兵节点。
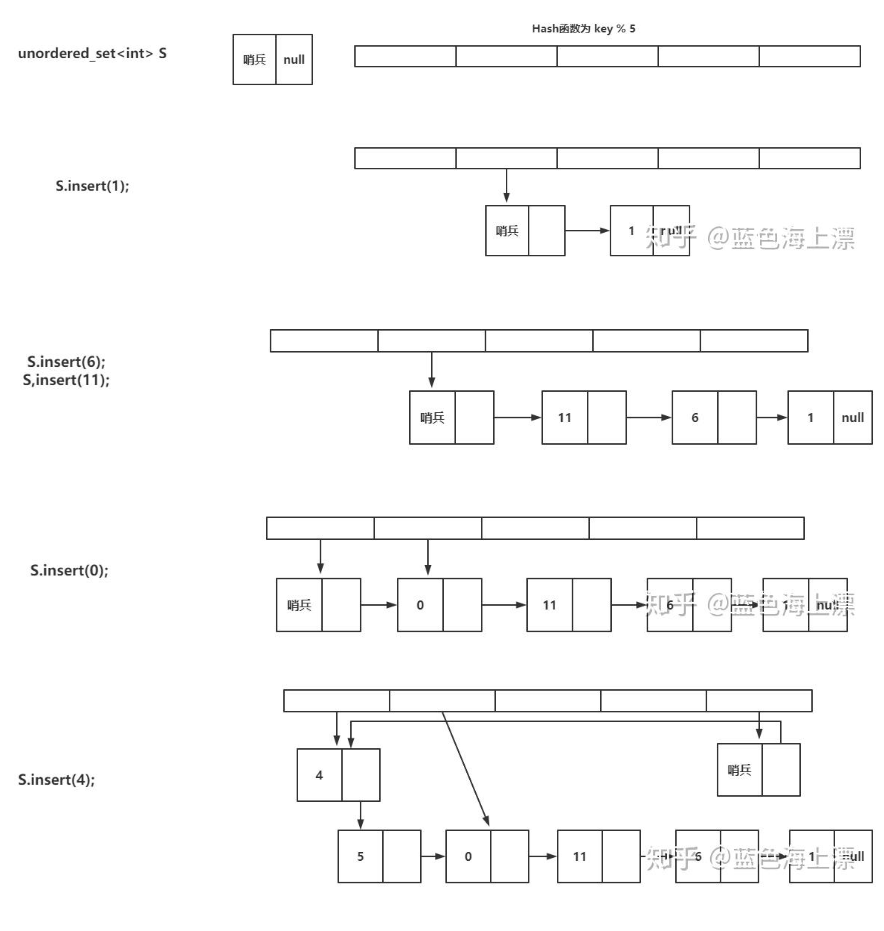
因此遍历hashtable由两种方法,一种是遍历bucket,只要遍历其中一个列表就能获得所有元素
另一种是直接利用哨兵节点,直接进行遍历
def dump_stl_hashmap1(addr):
# dump stl hashmap gnu c++ x64
data_addr = []
bucket_addr = idc.read_dbg_qword(addr + 0x10)
node_addr = bucket_addr
while node_addr != 0:
data_addr.append(node_addr + 0x8)
node_addr = idc.read_dbg_qword(node_addr)
return data_addrdef dump_hashtable_map(addr):
addrs = set()
hash_table = ida_bytes.get_qword(addr)
table_num = ida_bytes.get_qword(addr + 8)
for i in range(table_num):
link_list = ida_bytes.get_qword(hash_table + 8 * i)
if link_list == 0:
continue
ptr = ida_bytes.get_qword(link_list)
while ptr != 0:
assert ptr != idaapi.BADADDR
addrs.add(ptr)
ptr = ida_bytes.get_qword(ptr)
result = {}
for a in addrs:
result[ida_bytes.get_qword(a + 8)] = a + 16
return resultstd::map/set(rbtree)
- 底层采用 Rb-Tree 实现(红黑二叉树)
- 头结构 + 节点结构
- 用二叉树遍历可提取数据
- 适用 std::map / std::set / std::multimap / std::multiset
struct std::map{
void * allocator;
_Rb_tree_color _M_color;
node * root;
node * leftmost;//ignore
node * rightmost;//ignore
size_t node_count;
};
struct node{
_Rb_tree_color color;
node* parent;
node* left;
node* right;
TypeKey key;
TypeValue value;
};rb_tree分为两个部分,一个适用于比较的key_compare,另一个则是header。重点分析header,header中存在一个node,和node_count。node即这个红黑树的起始节点,而node_count则代表这颗红黑树拥有多少的节点。node中描述了当前节点的颜色,父亲节点,左儿子和右儿子节点。
当红黑树中不存在节点时,header中node的parent是0,而left和right则指向node自身。当插入了结点之后,这个parent则会指向树的根节点,而left和right则指向红黑树的最左边的节点和最右边的节点。
同时需要分清楚rb_tree变量本身和树本身。rb_tree变量中的node是不携带具体数据元素的,而树本身的节点在其node_base结构体结束后的内存区域则是数据元素。
def parse_gnu_map_header(address):
root = idc.read_dbg_qword(address + 0x10)
return root
def parse_gnu_map_node(address):
left = idc.read_dbg_qword(address + 0x10)
right = idc.read_dbg_dword(address + 0x18)
data = address + 0x20
return left, right, data
def parse_gnu_map_travel(address):
# address <—— std::map struct address
result = []
worklist = [parse_gnu_map_header(address)]
while len(worklist) > 0:
addr = worklist.pop()
(left, right, data) = parse_gnu_map_node(addr)
if left > 0: worklist.append(left)
if right > 0: worklist.append(right)
result.append(data)
return resultdef dump_rbtree_node(addr):
return {
'color' : ida_bytes.get_qword(addr),
'parent' : ida_bytes.get_qword(addr + 8),
'left' : ida_bytes.get_qword(addr + 16),
'right' : ida_bytes.get_qword(addr + 24),
}
def dump_rbtree_map(addr):
key = ida_bytes.get_qword(addr)
node_addr = addr + 8
node_num = ida_bytes.get_qword(addr + 40)
result = {}
def visit(node):
if node == idaapi.BADADDR:
return
info = dump_rbtree_node(node)
assert info['color'] == 1 or info['color'] == 0
value_key = ida_bytes.get_qword(node + 32)
data_addr = node + 40
result[value_key] = data_addr
if info['left'] != 0:
visit(info['left'])
if info['right'] != 0:
visit(info['right'])
d = dump_rbtree_node(node_addr)
visit(d['parent'])
assert len(result.keys()) == node_num
return resultmap和set的实现皆是基于rb_tree,而唯一不同之处在于set直接在node中存储数据,而map在node中存储的是键值对,是一个pair,而pair<a,b>在内存中的表示则是直接a后存放b。
otherthings
几个关键区分点
- 可以发现unordered_map的代码明显存在一个取mod的操作,而map存在std::rebalanced的操作。这是是区分map和unordered_map的关键
…等后续记录
n1ctf2022-cppmaster
没做,感觉wp不错,抄一下以后学习
- 获取容器的嵌套关系
import ida_bytes
import ida_funcs
import ida_xref
import idaapi
step_funcs = {}
funclist = Functions()
rebalance_func = None
for f in funclist:
name = ida_funcs.get_func_name(f)
if 'step' in name:
step_funcs[name] = f
elif 'rebalance' in name:
rebalance_func = f
assert rebalance_func != None
step_type = {}
for name, addr in step_funcs.items():
code = str(idaapi.decompile(addr))
if 'rebalance' in code:
step_type[name] = 'map'
elif '%' in code:
step_type[name] = 'hash_map'
else:
step_type[name] = 'deque'
for i in range(28):
print('\'' + step_type['step' + str(i + 1)] + '\'' + ', ', end = '')- 解析容器数据
import ida_bytes
import idaapi
size_table = {
'map' : 48,
'deque' : 80,
'string' : 32,
'hash_map' : 16,
}
def dump_rbtree_node(addr):
return {
'color' : ida_bytes.get_qword(addr),
'parent' : ida_bytes.get_qword(addr + 8),
'left' : ida_bytes.get_qword(addr + 16),
'right' : ida_bytes.get_qword(addr + 24),
}
def dump_rbtree_map(addr):
key = ida_bytes.get_qword(addr)
node_addr = addr + 8
node_num = ida_bytes.get_qword(addr + 40)
result = {}
def visit(node):
if node == idaapi.BADADDR:
return
info = dump_rbtree_node(node)
assert info['color'] == 1 or info['color'] == 0
value_key = ida_bytes.get_qword(node + 32)
data_addr = node + 40
result[value_key] = data_addr
if info['left'] != 0:
visit(info['left'])
if info['right'] != 0:
visit(info['right'])
d = dump_rbtree_node(node_addr)
visit(d['parent'])
assert len(result.keys()) == node_num
return result
def dump_deque_iterator(addr):
return {
'cur' : ida_bytes.get_qword(addr),
'first' : ida_bytes.get_qword(addr + 8),
'last' : ida_bytes.get_qword(addr + 16),
'map' : ida_bytes.get_qword(addr + 24),
}
def dump_deque(addr, delta):
deque_map = ida_bytes.get_qword(addr)
map_size = ida_bytes.get_qword(addr + 8)
assert map_size == 8
start = dump_deque_iterator(addr + 16)
finish = dump_deque_iterator(addr + 16 + 32)
assert start['last'] == finish['last'] and start['first'] == finish['first'] and start['map'] == finish['map']
assert (finish['cur'] - start['cur']) % delta == 0
ptr = start['cur']
index = 0
result = {}
while ptr != finish['cur']:
result[index] = ptr
index += 1
ptr += delta
return result
def dump_string(addr):
data = ida_bytes.get_qword(addr)
length = ida_bytes.get_qword(addr + 8)
return ida_bytes.get_bytes(data, length).decode()
def dump_hashtable_map(addr):
addrs = set()
hash_table = ida_bytes.get_qword(addr)
table_num = ida_bytes.get_qword(addr + 8)
for i in range(table_num):
link_list = ida_bytes.get_qword(hash_table + 8 * i)
if link_list == 0:
continue
ptr = ida_bytes.get_qword(link_list)
while ptr != 0:
assert ptr != idaapi.BADADDR
addrs.add(ptr)
ptr = ida_bytes.get_qword(ptr)
result = {}
for a in addrs:
result[ida_bytes.get_qword(a + 8)] = a + 16
return result
type_list = ['deque', 'map', 'hash_map', 'deque', 'map', 'map', 'hash_map', 'hash_map', 'map', 'map', 'hash_map', 'map', 'map', 'deque', 'deque', 'map', 'map', 'map', 'map', 'map', 'map', 'map', 'map', 'map', 'map', 'map', 'deque', 'deque', 'string']
def dump_dfs(depth, addr):
stl_type = type_list[depth]
tmp = {}
if stl_type == 'map':
tmp = dump_rbtree_map(addr)
elif stl_type == 'hash_map':
tmp = dump_hashtable_map(addr)
elif stl_type == 'deque':
next_type = type_list[depth + 1]
tmp = dump_deque(addr, size_table[next_type])
elif stl_type == 'string':
return dump_string(addr)
else:
assert False
node = {}
for k, v in tmp.items():
node[k] = dump_dfs(depth + 1, v)
return node
result = dump_dfs(0, 0x7FFEA5D3A460)
import json
with open('json_data.txt','w+') as f:
json.dump(result, f)
#dump_rbtree_map(0x55F47B277658)最后main函数通过对比字符串,来判断我们输入的一系列数字是否能够访问到对应的字符串,从而判断数字是否正确。
最后根据dump出的dict从而写出dfs查找出对应的数字序列,从而获得flag。
target = '8850a16d-e427-446e-b4df-5f45376e20e4'
path = []
def dfs(depth, node):
global path
if type(node) == dict:
for k, v in node.items():
path.append(k)
dfs(depth + 1, v)
path.pop()
else:
if node == target:
print(path)
import json
f = open('json_data.txt','r')
data = json.load(f)
f.close()
dfs(0, data)