记录阅读vmp分析博客中过程中vmp涉及到的大部分原理
VMP简单介绍
虚拟机保护特征
- 将由编译器生成的本机代码(Native Code)转换成字节码(Bytecode)
- 将控制权交由虚拟机,由虚拟机来控制执行
- 转换后的字节码非常难以阅读,增加了破解的复杂性
虚拟机其实就是一个字节码解释器,它循环的读取指令并执行,并且它
只有一个入口和一个出口(vm_exit)。大量的fake jcc(虚假跳转)和 垃圾指令使原来十分简单的代码 变得非常复杂

加入垃圾指令以及虚假跳转后的cfg

vmp进行代码保护的关键功能是**虚拟化 **和 **代码变异 **
其他小功能包括:
- 调试器检测
- 虚拟机检测
- 内存保护
- 资源保护
- 文件压缩
…

虚拟化
vm基本结构
在详细介绍vmp虚拟化保护之前,首先要介绍一下虚拟化保护所用到的几个结构体
dispatcher
在VMP1/2中会有一个分发器,所有Handler的地址都存在一个数组中,很容易就能把所有Handler找出来;但到了3,分发方式变成从字节码中解码出下一条指令的地址。
Handler
VMP是基于堆栈的虚拟机(Stack-Based VirtualMachine)
vmp通过dispatcher将程序流程的字节码分发到各个handler,模拟执行各种指令,因此分析vmp的关键逻辑就需要分析清楚走到的每个handler
汇编指令在转换到虚拟机的指令体系的过程中,被最大限度的化简和归类了,VMP中的
指令大体分以下几类:
- 算术运算和移位运算
- 堆栈操作
- 内存操作
- 系统相关(无法模拟指令)
- 逻辑运算
- jcc跳转
堆栈操作
在vmp初始化的过程中,会随机挑选一个寄存器当做虚拟机的堆栈,并维护一个结构体指向VM_Context保存虚拟机状态的寄存器
涉及到的伪指令包括vPushReg``vPushImm``vPopReg``vPopImm等
算术运算和移位运算
由于vmp是基于堆栈的虚拟机,因此算术运算也都是利用堆栈进行的
- vAdd
一般是 先出栈两个值 计算结果后保存到栈顶;往往计算完成后,之后的处理实际上是计算add_eflags然后再保存到栈顶
- vshl
一般是 先出栈两个值 次栈顶 << 栈顶 计算结果后保存到栈顶
逻辑运算指令
关键转换公式 : nor电路 把nor操作(只有not 和and) 记为P操作:
P(a,b) = ~a & ~b
not(a) = P(a,a) 1次P运算
and(a,b)= P(P(a,a),P(b,b)) 3次P运算
or(a,b) = P(P(a,b),P(a,b)) 2次P运算
xor(a,b)= P(P(P(a,a),P(b,b)),P(a,b)) 5次P运算
简单运用离散数学的知识就可以证明
Vmp中的逻辑运算只有一条指令:nor。这个指令在电路门中叫NOR门,它
由三条指令组成,即not not and,
与NAND门一样,用它可以模拟not
and xor or这四条逻辑运算指令
jcc
vmp固然很强,但是带来的运行开销实在太大了。把一个大型应用全部放在vmp运行必然是不现实的,因此绝大多数程序只会在验证等关键函数加上vmp,而程序的主体逻辑并不会加vmp,因此如果我们能找到vmp的jcc关键逻辑,并强行修改,我们就相当于直接破解了这个程序
同时,识别jcc指令后我们可以用模拟执行程序构建出整个程序的cfg,
https://www.52pojie.cn/thread-1696058-1-1.html
[分享]VMP学习笔记之万用门(七)-加壳脱壳-看雪-安全社区|安全招聘|kanxue.com
vmp实际上是通过eflags和cmp来模拟jcc指令
x86指令的cmp实际是执行的减法操作,只是不改变操作数的值,而是程序状态寄存器eflags的值。vmp模拟的减法指令如下:
x-y = ~(~x+y)
简单证明: -A=~A+1
~(~x+y)=~(-x+y-1)=-(-x+y-1)-1=x-y+1-1=x-yeflags的计算
eflags1 : (~x+y)
eflags2 : ~(~x+y)
eflags = (eflags1 & 0x815) + (elfags2 & ~0x815)
至于eflags1,eflags2我们可以并不关心eflags的reg图
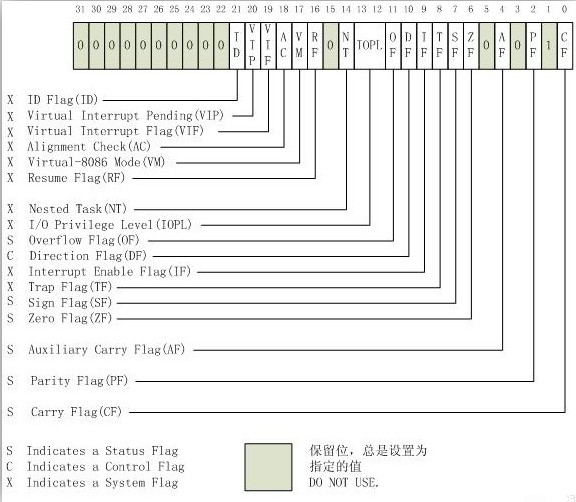
数字:0x815 0x246 0x206 0x216 0x40 会在vmp经常出现
0x815的二进制:100000010101
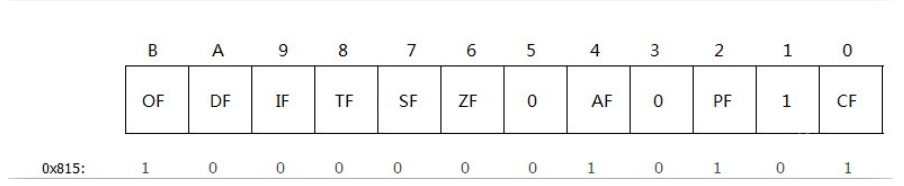
其实等价于OF AF PF CF的mask。
0x0040其实是ZF的mask
eflags = and( eflags1, 0x815) + and( eflags2, not(0x815))
例如在vmp我们可以类似找到ZF的计算过程
~zf = and(0x40,not(eflags)) = 0
zf=p(not(0x40),eflags)
Jge和Jl指令分析
Jge指令分析
y = (~(eflags10_0 ^ eflags12_68) & (~0xffffffbf)) >> 6判断SF标志位是否等于OF标志位,如果等于则输出为1,否则为0。SF==OF刚好是jge指令的跳转条件,这里~0xffffffbf
= 0x40是取zf标志位的值
令dword_ss[0xffffcf14] = 0xffffffff + y,y等于0或1
则vmbytecode读取指针vm_ip = (dword_ss[0xffffcf14] & 0x43db9e) + (~dword_ss[0xffffcf14] & 0x43dc22) + dword_ss[0xffffcfcc]0x43dc22为满足跳转条件时的读取地址,否则为0x43db9e。这里加一个dword_ss[0xffffcfcc]是为了重定位,如果程序加载的是默认基址的话dword_ss[0xffffcfcc]为0。同理,vmp访问全局变量前也是要重定位处理。需要注意的是模拟执行的过程中出现的一些常量并不是固定的。比如0xffffffbf、0x815、0x80、0x800等,有时候会对这些常量取反。
JL:
jl指令和jge指令的区别在于上面的异或运算结果有没有取反,其它都差不多。
Jne和Je指令分析
jne指令和jge指令模拟执行的区别在于上图下面的异或运算被替换成了eflags的还原运算,直接获取ZF标志位进行判断,其它都差不多。而jne指令与je指令的区别在于eflags的还原运算后有没有取反。
vmp模拟执行分支指令的一些特征如下:
1、eflags寄存器的值参与了运算,正常编写程序几乎不会用到eflags寄存器。
2、模拟分支指令的过程中会用到一些常量,比如0xffffffbf、0x815、0x80、0x800等。
3、vm_ip的两个跳转地址也参与了运算。
根据以上几个特征以及一些模拟运算的特征,可以判断vmp是否在模拟分支指令的执行。模拟过程中的常量比如0x40、0x800等可以确定可能使用了哪些分支指令,一般是两个相反跳转条件的分支指令。再根据eflags还原后的结果或者异或运算后的结果有没有取反来确定是哪一个分支指令。最后根据用于修改vm_ip的两个目的地址中,有兄弟节点是取反运算的则为满足跳转条件的地址,比如je指令的DAG图里的0x40add8就是满足跳转条件的目的地址。
寄存器轮转
VMP将所有寄存器都存放在了堆栈的结构中(VM_CONTEXT), 结构中的每一项代表一个寄存器或者临时变量。
但在运行过程中,其中的项所映射的真实寄存器都是不固 定的,可以把它比作一个齿轮,每做完一个动作,部分项 的映射就互换了一下位置,或者执行完一段指令,齿轮就 按不固定的方向和度数转动一下,然后全部的项映射就改 变了。
VMP在生成字节码的过程中,维护了一份结构中每一项所映射的真实寄存器,但这只存在于编译过程,而在运行时 是没有明确的信息的。这直接导致了分析和识别的难度。
字节码加密和随机效验
VMP把解码算法分布到了Dispatch和每个 Handler中,只有在取指令和取数据时才会解密
,而每个解码的算法也都是不同的,并且它的 Seed每次解密都会变化的。
- 可以写出字节码的逆算法-代价较高
- 实战还是Hook更省事(需要解决代码hash检测)(vmp运行的过程中会随机对代码段进行检测,如果出错就无法运行
VMP注册版中有一条叫指令( calchash),就 是用来做检测的。VMP会在编译好的字节码中加 一些自己的指令,每次执行都会随机对一段代码 生成一个Hash结果,然后与另一个随机的数相加 ,结果必须为0,否则就会出错。如果要爆破或者修改VMP的代码,还需要处理这个过程。
伪指令总结
PUSH类:
VM_PUSHW 1000177F
VM_PUSHW_CONTEXT 10001957
VM_PUSHW_CONTEXTBH 100019A7
VM_PUSHW_CONTEXTBL 10001A61
VM_PUSHW_IMMW 10001B68
VM_PUSH_CONTEXT 10001AB3
VM_PUSH_CR0 1000185E
VM_PUSH_CR1 10001164
VM_PUSH_CR2 10001820
VM_PUSH_CR3 100012D9
VM_PUSH_CR4 10001776
VM_PUSH_CR5 10001A31
VM_PUSH_CR6 10001AF6
VM_PUSH_CR7 100012F4
VM_PUSH_CS 10001B44
VM_PUSH_DR0 100045CB
VM_PUSH_DR1 100012EB
VM_PUSH_DR2 10001180
VM_PUSH_DR3 10001090
VM_PUSH_DR4 10001087
VM_PUSH_DR5 10001019
VM_PUSH_DR6 100010F6
VM_PUSH_DR7 10001855
VM_PUSH_DS 1000123B
VM_PUSH_ES 1000122C
VM_PUSH_ESP 100017DE
VM_PUSH_FS 1000114D
VM_PUSH_GS 100045A7
VM_PUSH_IMM 10001A41
VM_PUSH_IMMB 10001099
VM_PUSH_IMMW 100019F7
VM_PUSH_SP 1000458F
VM_PUSH_SS 1000184B
POP类:
VM_POPW_CONTEXT 100012FD
VM_POPW_CONTEXTBH 10001867
VM_POPW_CONTEXTBL 10001BE1
VM_POP_CONTEXT 10001BBB
VM_POP_CR0 100012E2
VM_POP_CR1 100018E7
VM_POP_CR2 100012A8
VM_POP_CR3 10001032
VM_POP_CR4 100018DE
VM_POP_CR5 10001A9E
VM_POP_CR6 1000116D
VM_POP_CR7 10001A7B
VM_POP_CX 10001368
VM_POP_DR0 100017B7
VM_POP_DR1 1000119F
VM_POP_DR2 10001AED
VM_POP_DR3 10001BFB
VM_POP_DR4 10001BA7
VM_POP_DR5 10001945
VM_POP_DR6 1000113A
VM_POP_DR7 100011B0
VM_POP_DS 100018F0
VM_POP_ECX 100018B4
VM_POP_ES 100012CF
VM_POP_ESP 100011CB
VM_POP_FS 100011A8
VM_POP_GS 100045C1
VM_POP_SP 1000102B
MUL/ADD/DIV类:
VM_ADD 10001838
VM_ADDB 100010DD
VM_ADDB_F 10001AA7
VM_ADDW 10001BB0
VM_ADDW_F 100012B1
VM_ADD_F 100019C2
VM_DIV 1000190A
VM_DIVW 100010CB
VM_DIVW_QUOTIENT 10001123
VM_IDIV 100018A8
VM_IDIVW 1000121A
VM_IDIVW_QUOTIENT 10001B24
VM_IMULB_F 1000104A
VM_IMULW_F 1000124A
VM_IMUL_F 10001157
VM_MULB_F 1000196D
VM_MULW_F 1000197C
VM_MUL_F 100019EA
FLOAT类:
VM_F2XM1 10001898
VM_FABS 100011F9
VM_FADD 100018BA
VM_FADDQ 10001060
VM_FCHS 10001998
VM_FCOMP 10001AE5
VM_FCOMPQ 1000199F
VM_FCOS 1000136F
VM_FDECSTP 10001AFF
VM_FDIV 10001233
VM_FDIVQ 100017EF
VM_FILD 1000455C
VM_FILDQ 10001916
VM_FINCSTP 10001071
VM_FISTP 10004554
VM_FISTPQ 100012A0
VM_FISTPW 1000100A
VM_FISUB 10001200
VM_FISUBW 10001B52
VM_FLD 10001932
VM_FLD1 100010FF
VM_FLDCW 100017A8
VM_FLDLG2 100017B0
VM_FLDLN2 10001346
VM_FLDPI 10001A3A
VM_FLDQ 10001208
VM_FLDT 10001B15
VM_FLDZ 10001B1D
VM_FMUL 10001242
VM_FMULQ 10001A84
VM_FNCLEX 10001059
VM_FNINIT 100017CA
VM_FNSTCWW 100018F7
VM_FNSTSWW 10001A28
VM_FPATAN 10001829
VM_FPREM 1000453A
VM_FPREM1 100010EF
VM_FPTAN 10001B4B
VM_FRNDINT 100019DC
VM_FSIN 1000133F
VM_FSQRT 10001012
VM_FST 100010E7
VM_FSTP 10001830
VM_FSTPQ 1000457D
VM_FSTPT 10001890
VM_FSTQ 100018CF
VM_FSUB 10001B85
VM_FSUBQ 10001805
VM_FSUBR 10001197
VM_FSUBRQ 100011C3
VM_FTST 100018D7
VM_FYL2X 100019E3
MOV类(分为byte,Word,DW几种),将[esp+0]定义为参数A,[esp+sizeof(operand)]定义为参数B,
VM_MOVB_A_TO_B 10004571
VM_MOVB_B_TO_A 100011EF
VM_MOVB_B_TO_CSA 10001ACA
VM_MOVB_B_TO_ESA 100011E4
VM_MOVB_B_TO_FSA 100017E4
VM_MOVB_B_TO_GSA 1000193A
VM_MOVB_B_TO_SSA 1000135D
VM_MOVB_CSA_TO_B 1000191E
VM_MOVB_GSA_TO_B 100010C0
VM_MOVW_A_TO_B 10001887
VM_MOVW_A_TO_SS 100011B9
VM_MOVW_B_TO_A 10001B31
VM_MOVW_B_TO_CSA 10001176
VM_MOVW_B_TO_ESA 100017C0
VM_MOVW_B_TO_FSA 1000125C
VM_MOVW_B_TO_GSA 100045AF
VM_MOVW_B_TO_SSA 1000198E
VM_MOVW_CSA_TO_B 10001B3A
VM_MOVW_ESA_TO_B 10001143
VM_MOVW_FSA_TO_B 10001130
VM_MOVW_GSA_TO_B 10001841
VM_MOVW_SSA_TO_B 10004585
VM_MOVZXB_ESA_TO_B 10001B9A
VM_MOVZXB_FSA_TO_B 100018C2
VM_MOVZXB_SSA_TO_B 10001BD4
VM_MOV_A_TO_B 10004541
VM_MOV_B_TO_A 100045B9
VM_MOV_B_TO_CSA 10001068
VM_MOV_B_TO_ESA 10001078
VM_MOV_B_TO_FSA 1000194E
VM_MOV_B_TO_GSA 10001A95
VM_MOV_B_TO_SSA 10001929
VM_MOV_CSA_TO_B 10001A8C
VM_MOV_ESA_TO_B 1000179F
VM_MOV_FSA_TO_B 10001022
VM_MOV_GSA_TO_B 1000189F
VM_MOV_SSA_TO_B 1000111A
移位类
VM_SHL 10004549
VM_SHLB 10004564
VM_SHLB_F 100019CD
VM_SHLD_F 10001811
VM_SHLW 10004599
VM_SHLW_F 1000134D
VM_SHL_F 10001B8D
VM_SHR 100018FF
VM_SHRB 10001322
VM_SHRB_F 10001313
VM_SHRD_F 10001B06
VM_SHRW 10001B5A
VM_SHRW_F 10001AD5
VM_SHR_F 100017D1
变形类
VM_NA_B_ANDW 100017F7
VM_NA_B_ANDW_F 1000132F
VM_NA_NB_AND 10001189
VM_NA_NB_ANDW 100012BE
VM_NA_NB_ANDW_F 100011D1
VM_NA_NB_AND_F 10001A14
杂类
VM_RETF 1000180D
VM_RETN 10001A24
VM_WAIT 10001081
对抗思路
目前已经提出针对vmp的保护措施的对抗思路:
字节码反编译
传统的逆向思路:
要逆向一个vmp
首先要看穿vmp插入的大量垃圾指令,虚假跳转的汇编中寻找真实的指令,并且要顾虑寄存器轮转的问题
分析清楚几百个handler
然后根据handler把基于堆栈低级汇编写出来,再进一步优化成标准的汇编
遇到稍微复杂点的程序,工作量实在是太大了
我的评价是:人生苦短,远离vmp
寄存器识别
在虚拟机运行时,寄存器的作用发生了交替
要识别前面所代表的寄存器,要从以下几个方面进行分析:
-
初始化虚拟机时各项所映射的寄存器
-
根据汇编转换规则映射或者结束映射某项到某寄存器
-
退出虚拟机时通过弹出各项时确定各项最终映射的寄存器
从这三方面可以大体推理出各项所映射的寄存器
但仅仅是这样的话,只有在没有跳转指令的字节码中,成功率才最高。
因为还得考虑寄存器轮转
- 基本块内的寄存器轮转
- 基本块间的寄存器轮转
指令化简和优化
- 常数收缩

- 活跃变量分析

- 删除无关代码
VMP在生成的字节码中夹杂了一些自己的指令流,这些指令与原汇编代码没有任何关系,且对还原分析没有任何好处,只会起到干扰的 作用。需要根据特征制定一些规则来识别这些垃圾指令.
目前也有人提出了应用机器学习来进行自动化匹配的指令化简和优化的方法
转换汇编
- 文本表达转换为树形表达
- 收集转换规则
- 使用匹配规则迭代匹配汇编指令
- 编译优化
…
代码变异
特征是:插入大量junkcode
控制流的混淆(将一个函数块拆分然后跳来跳去)