https://github.com/obfuscator-llvm/obfuscator/wiki
https://oacia.dev/ollvm-study/
[原创]Android APP漏洞之战(14)——Ollvm混淆与反混淆-Android安全-看雪-安全社区|安全招聘|kanxue.com
Deobfuscation: recovering an OLLVM-protected program
关于LLVM
具体什么是LLVM可参见官方wiki
https://zh.wikipedia.org/wiki/LLVM
环境搭建
下载源码
git clone -b llvm-4.0 --depth=1 [https://github.com/obfuscator-llvm/obfuscator.git](https://github.com/obfuscator-llvm/obfuscator.git)
安装ollvm docker
sudo docker pull nickdiego/ollvm-build
编译ollvm
~~git clone --depth=1 https://github.com/nickdiego/docker-ollvm.git~~
git clone --depth=1 [https://github.com/oacia/docker-ollvm.git](https://github.com/oacia/docker-ollvm.git)
原作者写的编译脚本跑不通,用oacia大佬修改后的脚本跑
编译成功后,创建软链接方便调用
sudo ln ./obfuscator/build_release/bin/* /usr/bin/
写了一个test文件报错
In file included from test.c:1:
/usr/include/stdio.h:34:10: fatal error: 'stddef.h' file not found
#include <stddef.h>
^~~~~~~~~~
1 error generated.sudo cp -r -i /home/npc/Desktop/Tools/Re/ollvm/obfuscator/build_release/lib/clang/4.0.1/include/. /usr/include/
遇到重名文件备份后再覆盖即可成功
- bcf # 虚假控制流
- bcf_prob # 虚假控制流混淆概率 1~100, 默认70
- bcf_loop # 虚假控制流重复次数, 无限制, 默认2
- fla # 控制流平坦化
- sub # 指令替换(add/and/sub/or/xor)
- sub_loop # 指令替换次数, 无限制, 默认1
- sobf # 字符串混淆(仅窄字符,只能在命令行中启用,不支持annotation)
- split # 基本块分割
- split_num # 将原基本块分割数量, 无限制, 默认3
- ibr # 间接分支
- icall # 间接调用 (call 寄存器)
- igv # 间接全局变量
- fncmd # 启用函数名控制混淆功能,annotation已经修好不建议再用这个 ( function_fla_bcf_(); )-mllvm -fla -mllvm -bcf -mllvm -bcf_prob=80 -mllvm -bcf_loop=3 -mllvm -sobf -mllvm -icall -mllvm -ibr -mllvm -igv -mllvm -sub -mllvm -sub_loop=3 -mllvm -split -mllvm -split_num=5混淆效果
#include <stdio.h>
#include <string.h>
void rc4_init(unsigned char*s,unsigned char *key,unsigned long len)
{
int i=0,j=0;
unsigned char k[256]={0};
unsigned char tmp=0;
for(i=0;i<256;i++)
{
s[i]=i;
k[i]=key[i%len];
}
for(i=0;i<256;i++)
{
j=(j+s[i]+k[i])%256;
tmp=s[i];
s[i]=s[j];
s[j]=tmp;
}
}
void rc4_crypt(unsigned char *s,unsigned char *Data,unsigned long Len)
{
int i=0,j=0,t=0;
unsigned long k=0;
unsigned char tmp;
//实际上就是Data的每个字节与Sbox的一个伪随机位置进行字节异或,进行一次还改变S盒子
for(k=0;k<Len;k++)
{
//通过一定算法生成伪随机数,再打乱S-box
i=(i+1)%256;
j=(j+s[i])%256;
tmp=s[i];
s[i]=s[j]; //交换s[x]和s[y]
s[j]=tmp;
//再生成一个随机位置,对明文进行异或
t=(s[i]+s[j])%256;
Data[k]^=s[t];
}
}
int main()
{
unsigned char s[256]={0},s2[256]={0};
char key[256]={"HelloWorld"};
char pData[512]="HelloWorld";
unsigned long len=strlen(pData);
int i;
printf("pData=%s\n",pData);
printf("key=%s,length=%d\n\n",key,strlen(key));
rc4_init(s,(unsigned char*)key,len);
printf("完成对S[i]的初始化,如下:\n\n");
//输出S[i]
for(i=0;i<256;i++)
{
printf("%02X",s[i]);
if(i&&(i+1)%16==0)
{
putchar('\n');
}
}
printf("\n\n");
//用s2[i]暂时保存初始化过的s[i],用来解密
for(i=0;i<256;i++)
{
s2[i]=s[i];
}
printf("已经初始化,现在加密:\n\n");
rc4_crypt(s,(unsigned char*)pData,len);
printf("pData=%s\n\n",pData);
printf("已经加密,现在解密:\n\n");
rc4_crypt(s2,(unsigned char*)pData,len);
printf("pData=%s\n\n",pData);
}未加混淆
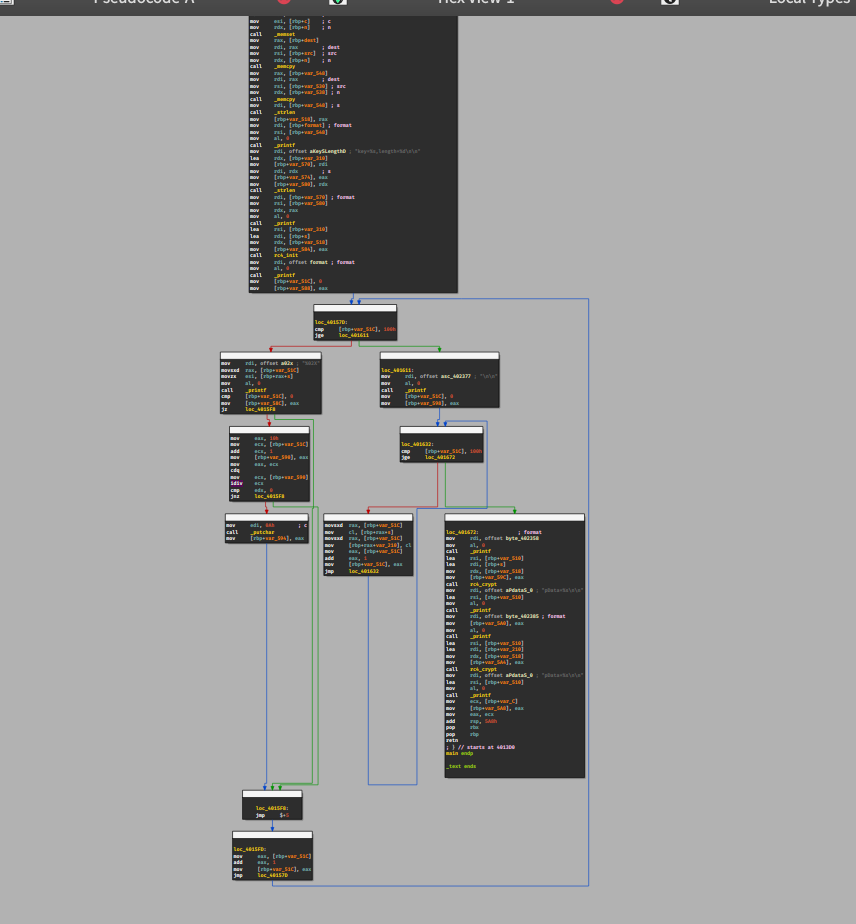
虚假控制流 BCF (Bogus Control Flow)
BCF介绍
首先编译一个看看效果
clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 test.c -o test-bcf
- -mllvm -bcf : 激活bcf混淆
- -mllvm -bcf_loop=3 : 混淆次数,这里一个函数会被混淆 3 次,默认为 1
- -mllvm -bcf_prob=40 : 每个基本块被混淆的概率,这里每个基本块被混淆的概率为 40%,默认为 30 %
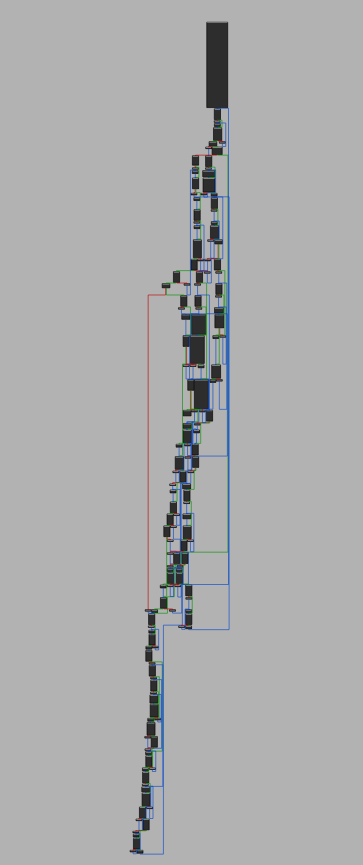
开启了bcf混淆后,控制流变得很复杂
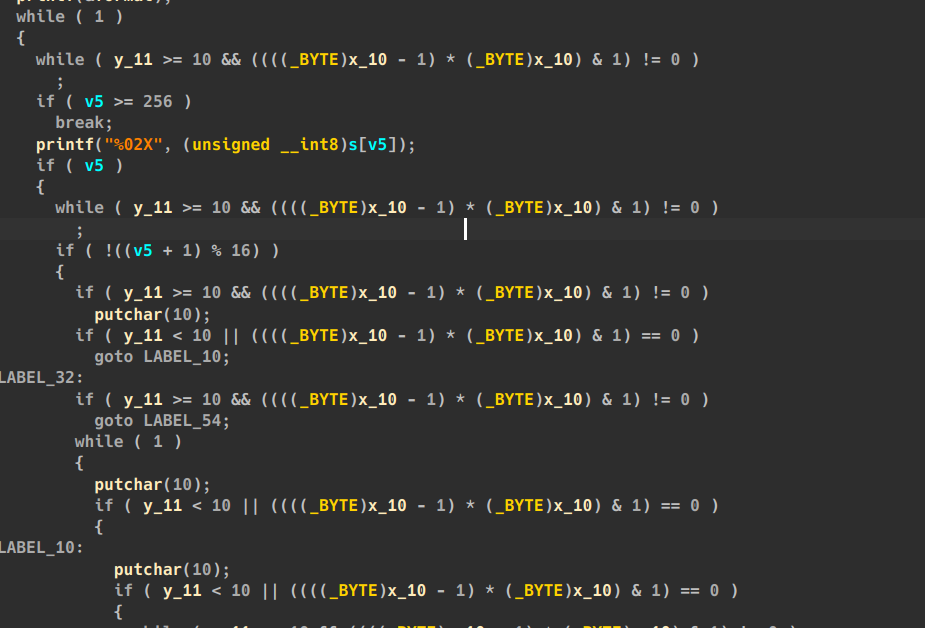
可以看到反编译结果出现了很多y_11 >= 10 && (((x_10 - 1) * x_10) & 1) !=0 之类的表达式,化简右边表达式为永假&&连接 这个表达式就是永假,因此在这个逻辑块内的代码就永远不会执行
根据官方wikihttps://github.com/obfuscator-llvm/obfuscator/wiki/Bogus-Control-Flow
BogusControlFlow方法:通过在当前基本块之前添加一个新的基本块来修改函数调用图。这个新基本块包含一个不透明谓词,然后根据条件跳转跳到原始基本块。原始的基本块也会被克隆,并用随即选取的无用指令填充(形成虚假块),以达到混淆控制流的方法
具体的源码分析可以看下面的博文
对抗思路
d810,hrtng一把梭
大爹们写的插件tql,插件一装直接F5就能把BCF混淆给秒了orz
由于主要是分析ollvm,所以简略地介绍一下d810。hrtng插件比较新,还没有分析过
d810的工作原理:简而言之就是通过修改ida pro的microcode在反编译时进行去混淆,通过直接操作microcode,利用z3以及自定义的去混淆规则进行匹配(IDA Microcode, 他是一种中间语言,从反汇编出来的汇编代码到F5生成C代码,中间要经过多次的Microcode转换。)
分两步走,第一步是指令替换,将部分复杂的表达式进行化简替换。第二步就是流程重组,找到所有的真实块重组出正确的流程。
https://github.com/gaasedelen/lucid 使用插件可以方便探索ida的microcode
模拟执行&符号执行
由于虚假块在程序中可能永远不会到达,因此我们可以利用模拟执行使用诸如angr,unicorn,unidbg等模拟&符号执行框架,记录所有真实块的地址。而不可到达的基本块我们就可以进行patch,将jcc形式的指令patch为jmp
动态调试
在一把索脚本还没出现的远古年代,最原始对抗bcf就是直接动态调试,下断点,patch掉不会执行的虚假块,并且patch修复好真实块
IDA去除BCF
IDA其实有DCE(Dead Code Elimination)功能,但是由于ollvm生成表达式里变量被定义为全局变量,且没有被赋值,因此ida不知道是否应该将其消除
如果我们固定这个变量,并且将变量所在的 segment 设为 只读 ,IDA 就可以自己算出来这个表达式的值是多少了,这样IDA就能自动优化掉DeadCode
使用oacia大佬的脚本
import ida_segment
import ida_bytes
seg = ida_segment.get_segm_by_name('.bss')
for ea in range(seg.start_ea, seg.end_ea,4):
ida_bytes.patch_bytes(ea, int(2).to_bytes(4,'little'))
'''
seg.perm: 由三位二进制数表示,例如一个segment为可读,不可写,不可执行,则seg.perm = 0b100
(seg.perm >> 2)&1: Read
(seg.perm >> 1)&1: Write
(seg.perm >> 0)&1: Execute
'''
seg.perm = 0b100另外可以使用ida python将不透明谓词给patch为已知的值

patch为 mov r8d,0 mov r9d,0 即可达到反混淆的目的
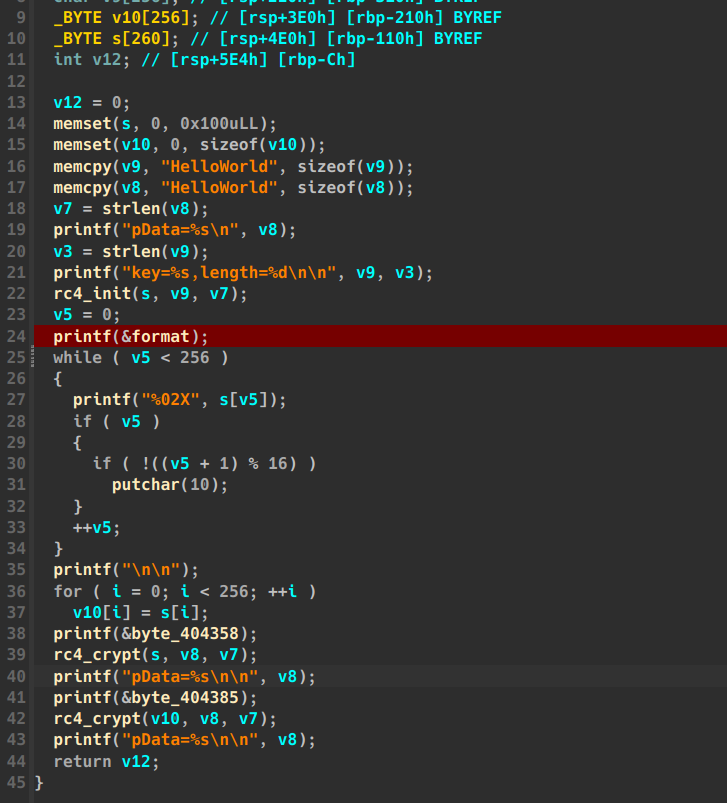
可见反编译效果如同源码
# 去除虚假控制流 idapython 脚本
import ida_xref
import ida_idaapi
from ida_bytes import get_bytes, patch_bytes
# 将 mov 寄存器,不透明谓词 修改为 mov 寄存器,0
def do_patch(ea):
if get_bytes(ea, 1) == b"\x8B": # mov eax-edi, dword
reg = (ord(get_bytes(ea + 1, 1)) & 0b00111000) >> 3
patch_bytes(ea, (0xB8 + reg).to_bytes(1,'little') + b'\x00\x00\x00\x00\x90\x90')
else:
print('error')
# 不透明谓词在.bss 段的范围
seg = ida_segment.get_segm_by_name('.bss')
start = seg.start_ea
end = seg.end_ea
for addr in range(start,end,4):
ref = ida_xref.get_first_dref_to(addr)
print(hex(addr).center(20,'-'))
# 获取所有交叉引用
while(ref != ida_idaapi.BADADDR):
do_patch(ref)
print('patch at ' + hex(ref))
ref = ida_xref.get_next_dref_to(addr, ref)
print('-' * 20)指令替换SUB(Instruction Substitution)
clang -mllvm -sub -mllvm -sub_loop=3 test.c -o test-sub
- mllvm -sub : 激活指令替换
- mllvm -sub_loop=3 : 混淆次数,这里一个函数会被混淆 3 次,默认为 1 次
SUB介绍
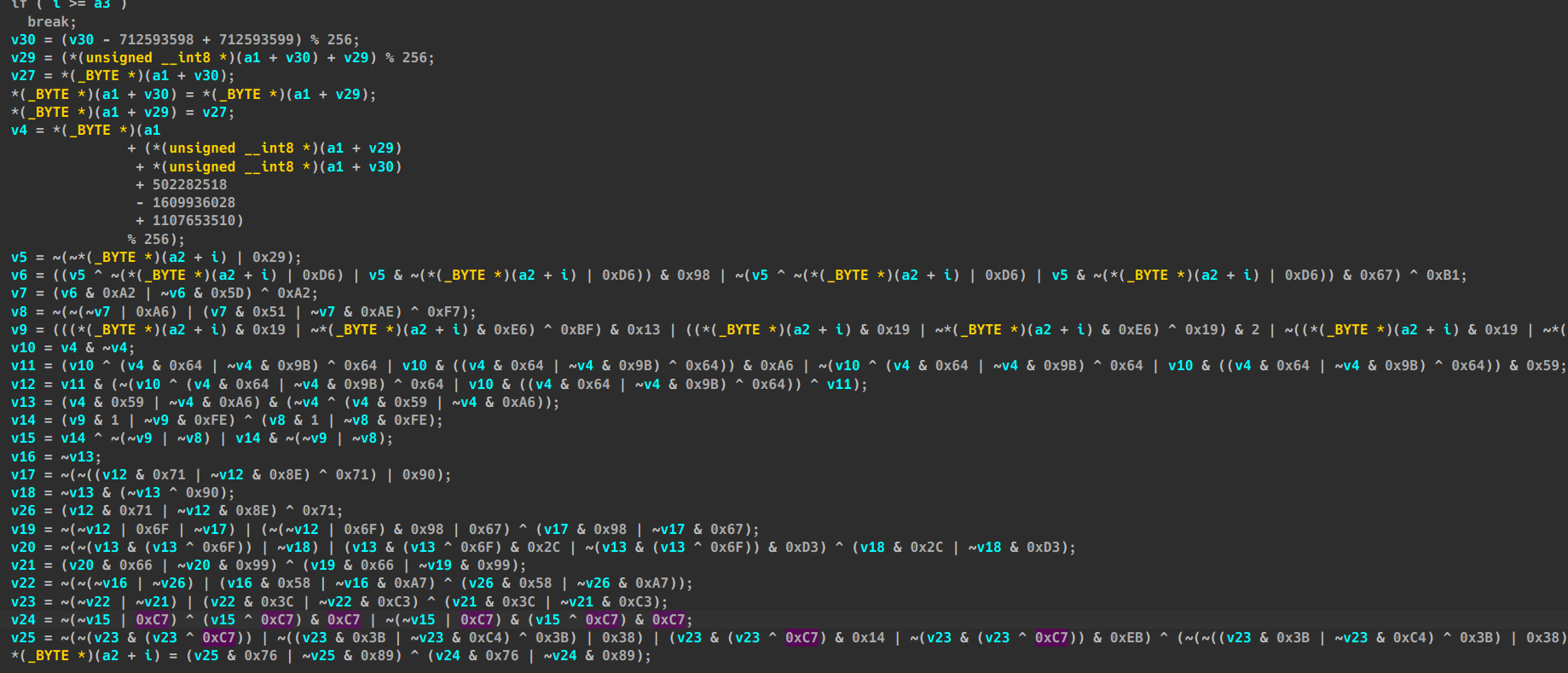
可见混淆效果多了依托表达式,化简为繁
指令替换:用功能等效但更复杂的指令序列来替换标准的二进制运算符(如加法、减法或布尔运算符)。当存在多个等效的指令序列时,随机选择其中一个。
https://github.com/obfuscator-llvm/obfuscator/wiki/Instructions-Substitution
根据官方wiki
可以知道:
加法可以替换为:
a = b - (-c)a = -(-b + (-c))r = rand (); a = b + r; a = a + c; a = a - rr = rand (); a = b - r; a = a + b; a = a + r
减法可以替换为:
a = b + (-c)r = rand (); a = b + r; a = a - c; a = a - rr = rand (); a = b - r; a = a - c; a = a + r
AND:
a = b & c => a = (b ^ ~c) & b
OR:
a = b | c => a = (b & c) | (b ^ c)a = a ^ b => a = (~a & b) | (a & ~b)
XOR:
a = a ^ b => a = (~a & b) | (a & ~b)
虽然这些变换很少很简单,但是loop了多次,进行多次全局指令替换混淆效果就很恐怖,代码就会很膨胀难以分析
对抗思路
这类指令膨胀,我们就仍然可以采用d810进行匹配化简,如果遇到d810无法反混淆的表达式,我们则可以采用专用的求解器来进行化简例如
https://github.com/DenuvoSoftwareSolutions/GAMBA
python3 src/simplify_general.py "expr"
然后化简后还可以自己给d810补充规则
例如我编写的例子中跑一遍d810后有部分表达式仍未完全化简
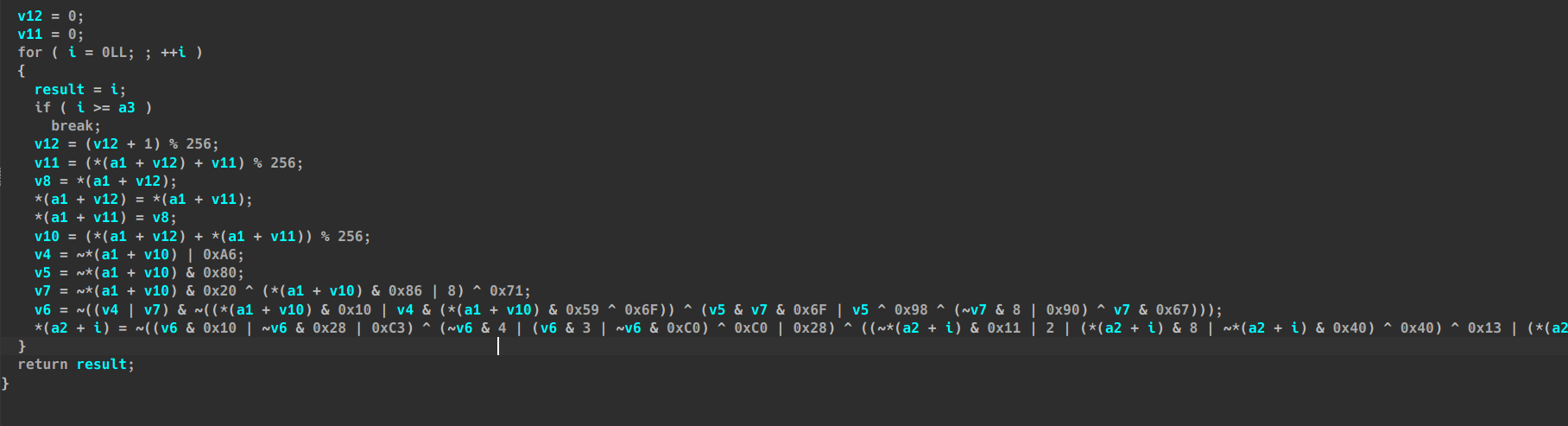
后面的表达式我们人工喂给mba可以发现化简到最后这就是一个简单的xor
实测HRT插件对sub的去混淆效果不如d810
控制流平坦化FLA(control flow flattening)
FLA介绍
clang -mllvm -fla -mllvm -split -mllvm -split_num=3 test.c -o test-fla
- mllvm -fla : 激活控制流平坦化
- mllvm -split : 激活基本块分割
- mllvm -split_num=3 : 指定基本块分割的数目
混淆后的cfg
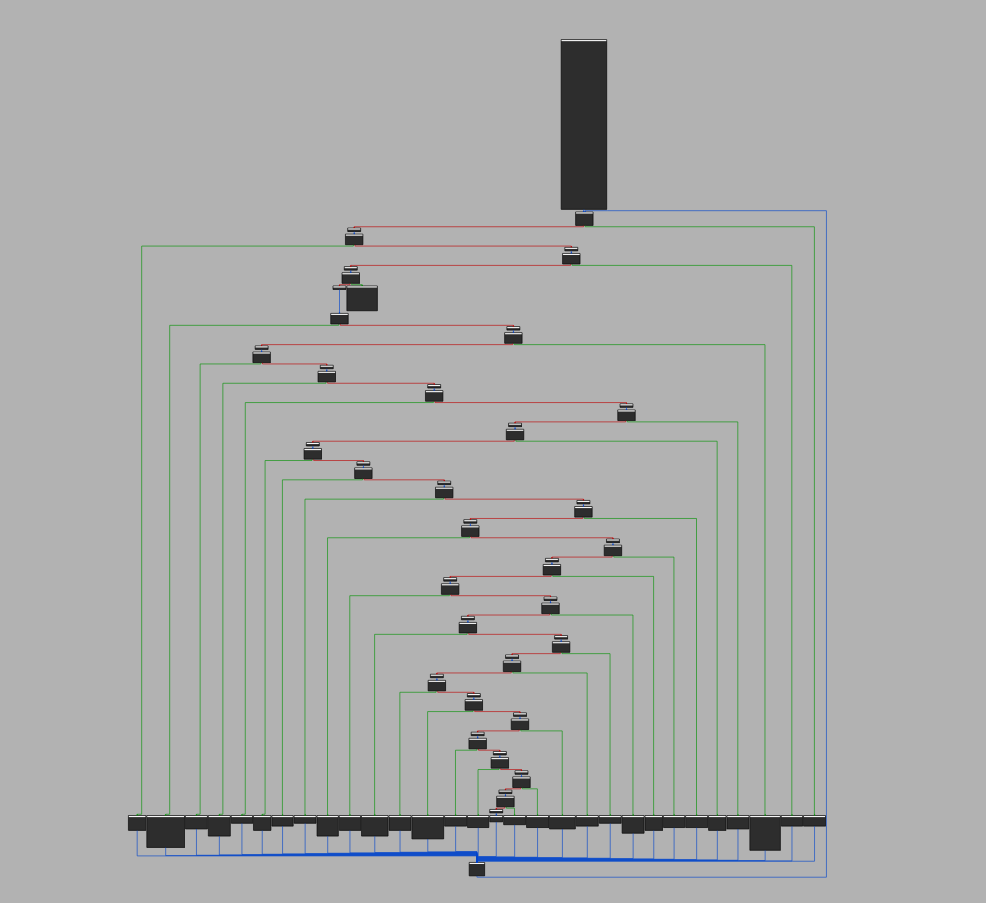
恐怖如斯
根据官方wiki https://github.com/obfuscator-llvm/obfuscator/wiki/Control-Flow-Flattening
所有基本块都被拆分并放入一个无限循环中,程序流程由 switch 和变量 b 控制
经过OLLVM,IR被完全展平
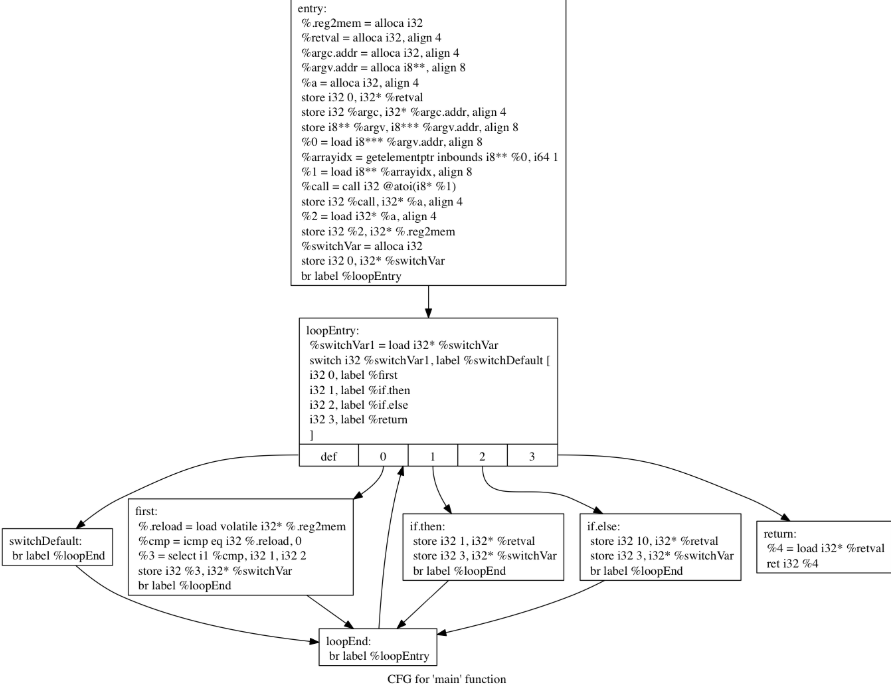
我们C语言版本的cfg
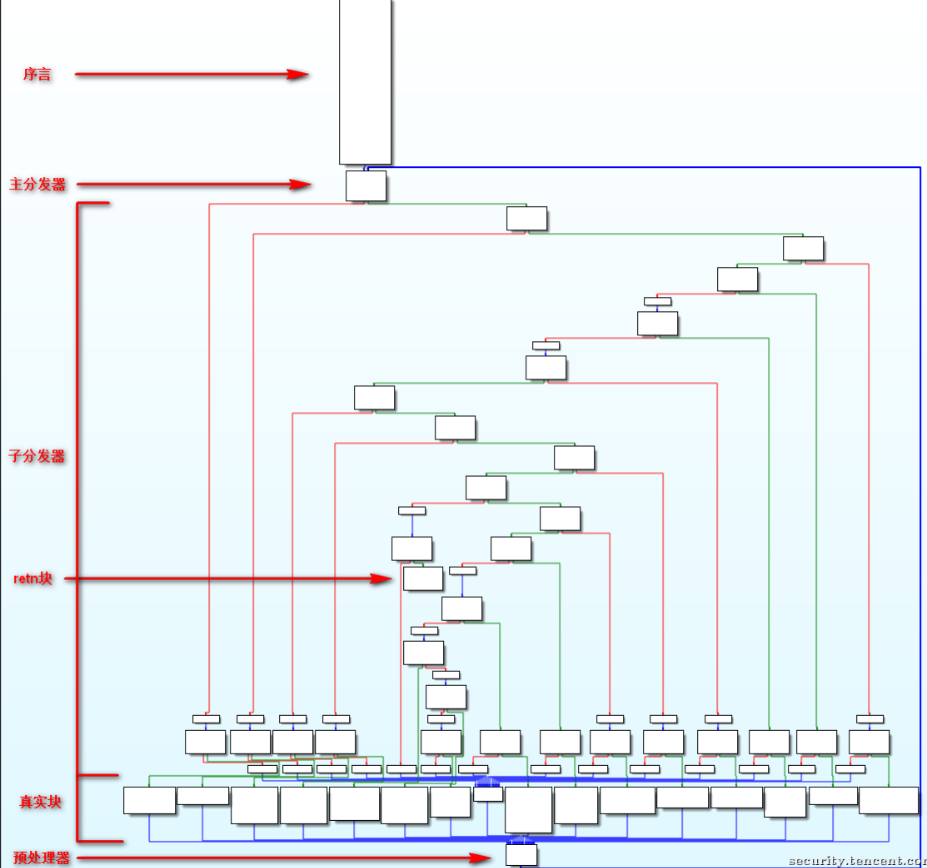
- 序言:函数的第一个执行的基本块
- 主 (子) 分发器:控制程序跳转到下一个待执行的基本块
- retn 块:函数出口
- 主分发器的前驱有两个,除了序言块外,另一个块就是预处理器
- 预处理器的前驱是真实块
- 除此之外的其他块是子分发器
对抗思路
FLA往往与BCF相结合,代码块里不仅仅有真实块也有虚假块
然后OLLVM的程序真实逻辑主要在序言,真实块和retn块
因此反混淆的思路就有两步
第一步,区分真实块与虚假块
第二步,确定真实块执行的顺序
d810,hrtng脚本一把索这里不赘述,重点分析如何人工去除控制流平坦化
- 首先需要找到真实块并且分析真实块调用顺序,比如利用dbg,IDApython下断点trace各个真实块;比如利用unicorn或者angr等模拟执行,符号执行框架分析出真实块;
- 得到真实块执行顺序后,我们可以将虚假块nop掉 并且将每个真实块的末尾用
jmp指令,连接起来,这样就能修复好fla了
对于标准ollvm混淆的fla:
- 区分基本块
这些基本块在CFG中具有很明显的特征,例如前继基本块为0的是序言块,后继基本块为0的是retn块,后继基本块为预处理器(预分发器)的为真实块,而预处理器的后继基本块为主分发器,而主分发器的前继基本块为序言块。因此,通过这些特征很容区分出这些基本块。
(不过如果是魔改混淆,则可能需要另找特征进行区分)
- 恢复相关块(包括序言块)之间的跳转关系
https://github.com/gal2xy/AngrDeobfuscator
https://gal2xy.github.io/2024/06/25/LLVM%20and%20OLLVM/ollvm%E5%8F%8D%E6%B7%B7%E6%B7%86/
- 符号执行:利用Angr从每个相关块(包括序言块)进行符号执行,当执行到其他相关块中时,则认为找到了当前相关块的后继相关块。当然,后继块数量可能 > 2,则就需要下断点,更改条件表达式变量的值,使其强制执行我们所需要的分支,,这样才能恢复得全面。
- 模拟执行:使用unicorn等模拟执行框架,nop掉未执行的代码,并记录所有基本块的执行顺序,然后写一个idapython脚本进行patch修复二进制的分支
实际上面的方法都殊途同归,核心就是要找到真实块,并且记录调用顺序
对本例中的fla尝试反混淆
代码参考oacia大佬的
- 区分真实块与虚假块
import idaapi
import idc
target_func = 0x401CD0#需要反控制流平坦化的函数的地址
Preprocessor_block = 0x402598#ollvm 中预处理器的地址,这个是通过观察 ida 中的 CFG 得到的,预处理器的前驱都是真实块
True_blocks = []#真实块列表
Fake_blocks = []#所有块的列表
f_block = idaapi.FlowChart(idaapi.get_func(target_func), flags=idaapi.FC_PREDS)
for block in f_block:
if block.start_ea==Preprocessor_block:#预处理器块的前驱都是真实块
#but 预处理器是虚假块
Fake_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
print("find ture block!")
tbs = block.preds()
for tb in tbs:
#print (hex (tb.start_ea),hex (idc.prev_head (tb.end_ea)))# 获取块的开始 / 结束地址
True_blocks.append((tb.start_ea,idc.prev_head(tb.end_ea)))
elif not [x for x in block.succs()]:#返回块没有后继
print(f"find ret block!{hex(block.start_ea)}")
True_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
# 序言块不作为虚假块处理
elif block.start_ea!=target_func:
#print(hex(block.start_ea),hex(idc.prev_head(block.end_ea)))
Fake_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
print('true block:')
print('tbs =',True_blocks)
print('fake block:')
print('fbs =',Fake_blocks)使用idapython脚本,找出所有的真实块的start_ea,区分用到了前文提出的3个规律
- 标准ollvm下 预处理器块的前驱都是真实块
- 标准ollvm下 返回块没有后继block
- 这里预处理器,主子分发器是作为虚假块处理的,而序言块和ret块是作为真实块处理的,因为我们是要将序言块与真实块patch连接在一起从而去除fla
- 使用 unicorn 来模拟执行得到真实块的调用关系(重点是要获取jcc的标志位确定是什么跳转)
# code for test-fla.elf
from unicorn import *
from unicorn.x86_const import *
from keystone import * # pip install keystone-engine
from capstone import * # pip install capstone
import networkx as nx #pip install networkx
#import matplotlib.pyplot as plt # pip install matplotlib
BASE = 0x400000
CODE = BASE + 0x0
CODE_SIZE = 0x100000
STACK = 0x7F00000000
STACK_SIZE = 0x100000
FS = 0x7FF0000000
FS_SIZE = 0x100000
ks = Ks(KS_ARCH_X86, KS_MODE_64) # 汇编引擎
uc = Uc(UC_ARCH_X86, UC_MODE_64) # 模拟执行引擎
cs = Cs(CS_ARCH_X86, CS_MODE_64) # 反汇编引擎
g=nx.Graph ()# 创建空的无向图
g=nx.DiGraph ()# 创建空的有向图
tbs = [(4203861, 4203927), (4202723, 4202723), (4202728, 4202800), (4202805, 4202914), (4202919, 4202988), (4202993, 4203003), (4203008, 4203027), (4203032, 4203059), (4203064, 4203089), (4203094, 4203113), (4203118, 4203145), (4203150, 4203202), (4203207, 4203232), (4203237, 4203256), (4203261, 4203302), (4203307, 4203332), (4203337, 4203362), (4203367, 4203393), (4203398, 4203408), (4203413, 4203423), (4203428, 4203447), (4203452, 4203474), (4203479, 4203512), (4203517, 4203537), (4203542, 4203570), (4203575, 4203600), (4203605, 4203653), (4203658, 4203677), (4203682, 4203701), (4203706, 4203728), (4203733, 4203856)]
tb_call = []
main_addr = 0x000000000401CD0
main_end = 0x00000000040259D #ret指令的地址
def hook_code(uc: unicorn.Uc, address, size, user_data):
# print(hex(address))
for i in cs.disasm(CODE_DATA[address - BASE:address - BASE + size], address):
print(hex(address),i.mnemonic, i.op_str)
if i.mnemonic == "call": # 因为只是针对单个函数的控制流,所以我们并不需要跳转到其他的函数里面
print(f"find call at {hex(address)}, jump...")
uc.reg_write(UC_X86_REG_RIP, address + size)
elif i.mnemonic == "ret":
print("find ret block, emu stop~")
uc.emu_stop()
print("block emu path↓↓↓↓")
count=0
# for tb, ZF in tb_call:
# print(f"{count}:{hex(tb[0])}",end=' ')
# count+=1
print(tb_call)
# for i in range(len(tb_call)-1):
# g.add_edge(tb_call[i],tb_call[i+1])
# Plot it
# nx.draw(g, with_labels=True)
# nx.write_gml(g,'./test-fla.gml')
for tb in tbs:
##print(address)
if address == tb[1]:
# print (uc.reg_read (UC_X86_REG_FLAGS))#ZF 标志位在第 6 位
ZF_flag = (uc.reg_read(UC_X86_REG_FLAGS) & 0b1000000) >> 6
#print("ZF=", ZF_flag)
tb_call.append((tb, ZF_flag))
break
def hook_mem_access(uc: unicorn.Uc, type, address, size, value, userdata):
pc = uc.reg_read(UC_X86_REG_RSP) # UC_ARM64_REG_PC
print('pc:%x type:%d addr:%x size:%x' % (pc, type, address, size))
# uc.emu_stop()
return True
def hook_intr(uc, intno, user_data):
print(f"Interrupt detected: intno={intno}")
# 可以在这里处理中断事件
return True # 返回 True 表示继续模拟
def inituc(uc):
uc.mem_map(CODE, CODE_SIZE, UC_PROT_ALL)
uc.mem_map(STACK, STACK_SIZE, UC_PROT_ALL)
uc.mem_write(CODE, CODE_DATA)
uc.reg_write(UC_X86_REG_RSP, STACK + 0x1000)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_access)
uc.hook_add(UC_HOOK_INTR, hook_intr)
with open('./test-fla', 'rb') as f:
CODE_DATA = f.read()
inituc(uc)
try:
uc.emu_start(main_addr, main_end)
except Exception as e:
print(e)我们只对一个函数中真实块的前后调用进行模拟执行,所以是不需要跳转到其他函数中的,遇到 call 指令直接将 pc 强制改成下一行汇编的地址,同时也要注意内存访问异常的情况直接通过 uc.hook_add(UC_HOOK_MEM_UNMAPPED|UC_HOOK_INTR, hook_mem_access) 进行忽略
这个脚本还是只能跑简单的情况,甚至遇到.bss变量的读取就会无法模拟 但是用在我们的例子上也够了
主要就是运用了分发器的fla只运用了jz指令来判断,因此我们获取了所有true block执行时的zf标志,就可以知道跳转关系
- 使用ida python patch真实块的跳转关系。完成真实块的串联去除fla
68894
先观察真实块的执行关系,可以发现标准ollvm的真实块调用实际上是连续的,并且每个真实块只执行了一次
我们之间patch掉块最后的
其实我们直接把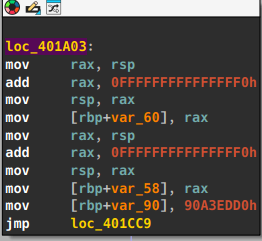 jmp的地址给patch掉下一个true block即可
jmp的地址给patch掉下一个true block即可
再利用我们前文分析的内容
- nop掉所有的fakeblock
import idaapi
import ida_bytes
import idc
from keystone import *
ks = Ks(KS_ARCH_X86, KS_MODE_64) # 汇编引擎
def jmp_patch(start, target, j_code="jmp"):
global debug
patch_byte, count = ks.asm(f"{j_code} {hex(target)}", addr=start)
patch_byte = bytes(patch_byte) + b'\x00' * (idc.get_item_size(start) - len(patch_byte))
print(hex(start), f"{j_code} {hex(target)}", patch_byte)
ida_bytes.patch_bytes(start, patch_byte)
def patch_nop(addr, endaddr):
#print(f"Patching from {addr} to {endaddr}")
while addr < endaddr:
ida_bytes.patch_byte(addr, 0x90)
addr += 1
def patch_nop_line(addr):
patch_nop(addr,addr+idc.get_item_size(addr))
preamble_block = 0x401D88 # 序言块的地址
internal_reg = '[rbp+var_560]'#中间变量的名称,遇到这个想都不用想直接 NOP
# 格式: ((块的起始地址,块的结束地址),ZF 标志位)
tb_path =[...]
tbs = [(4203861, 4203927), (4202723, 4202723), (4202728, 4202800), (4202805, 4202914), (4202919, 4202988), (4202993, 4203003), (4203008, 4203027), (4203032, 4203059), (4203064, 4203089), (4203094, 4203113), (4203118, 4203145), (4203150, 4203202), (4203207, 4203232), (4203237, 4203256), (4203261, 4203302), (4203307, 4203332), (4203337, 4203362), (4203367, 4203393), (4203398, 4203408), (4203413, 4203423), (4203428, 4203447), (4203452, 4203474), (4203479, 4203512), (4203517, 4203537), (4203542, 4203570), (4203575, 4203600), (4203605, 4203653), (4203658, 4203677), (4203682, 4203701), (4203706, 4203728), (4203733, 4203856)]
fbs = [(4201874, 4201900), (4201906, 4201906), (4201911, 4201928), (4201934, 4201934), (4201939, 4201956), (4201962, 4201962), (4201967, 4201984), (4201990, 4201990), (4201995, 4202012), (4202018, 4202018), (4202023, 4202040), (4202046, 4202046), (4202051, 4202068), (4202074, 4202074), (4202079, 4202096), (4202102, 4202102), (4202107, 4202124), (4202130, 4202130), (4202135, 4202152), (4202158, 4202158), (4202163, 4202180), (4202186, 4202186), (4202191, 4202208), (4202214, 4202214), (4202219, 4202236), (4202242, 4202242), (4202247, 4202264), (4202270, 4202270), (4202275, 4202292), (4202298, 4202298), (4202303, 4202320), (4202326, 4202326), (4202331, 4202348), (4202354, 4202354), (4202359, 4202376), (4202382, 4202382), (4202387, 4202404), (4202410, 4202410), (4202415, 4202432), (4202438, 4202438), (4202443, 4202460), (4202466, 4202466), (4202471, 4202488), (4202494, 4202494), (4202499, 4202516), (4202522, 4202522), (4202527, 4202544), (4202550, 4202550), (4202555, 4202572), (4202578, 4202578), (4202583, 4202600), (4202606, 4202606), (4202611, 4202628), (4202634, 4202634), (4202639, 4202656), (4202662, 4202662), (4202667, 4202684), (4202690, 4202690), (4202695, 4202712), (4202718, 4202718), (4202723, 4202723), (4202728, 4202800), (4202805, 4202914), (4202919, 4202988), (4202993, 4203003), (4203008, 4203027), (4203032, 4203059), (4203064, 4203089), (4203094, 4203113), (4203118, 4203145), (4203150, 4203202), (4203207, 4203232), (4203237, 4203256), (4203261, 4203302), (4203307, 4203332), (4203337, 4203362), (4203367, 4203393), (4203398, 4203408), (4203413, 4203423), (4203428, 4203447), (4203452, 4203474), (4203479, 4203512), (4203517, 4203537), (4203542, 4203570), (4203575, 4203600), (4203605, 4203653), (4203658, 4203677), (4203682, 4203701), (4203706, 4203728), (4203733, 4203856), (4203928, 4203928)]
block_info = {} #判断有没有 patch 结束
for i in range(len(tbs)):
block_info[tbs[i][0]] = {'finish': 0,'ret':0}
#nop 掉所有虚假块
for fb in fbs:
patch_nop(fb[1], fb[1] + idc.get_item_size(fb[1]))
for tb in tbs:
dont_patch = False
current_addr = tb[0]
while current_addr <= tb[1]:
# print(hex(current_addr),idc.GetDisasm(current_addr))
if "cmov" in idc.print_insn_mnem(current_addr):
#cmov 指令会影响分支跳转,所以这里直接 patch 掉
patch_nop_line(current_addr)
dont_patch = True
# print(hex(current_addr),hex(tb_path[i][0]))
elif internal_reg in idc.print_operand(current_addr, 0):
print('find internal_reg!')
patch_nop_line(current_addr)
elif 'ret' in idc.print_insn_mnem(current_addr):
block_info[tb[0]]['ret'] = 1
dont_patch = True
current_addr = idc.next_head(current_addr)
if not dont_patch:
patch_nop_line(tb[1])
block_info[tb[0]]['finish'] = 1
# 序言块 -> 第一个真实块 patch
jmp_patch(preamble_block, tb_path[0][0][0])
for i in range(len(tb_path) - 1):
# 不是返回块,也未完成 patch, 剩下的指令都是有分支跳转的.
if block_info[tb_path[i][0][0]]['finish'] == 0 and not block_info[tb_path[i][0][0]]['ret']:
ZF = tb_path[i][1]
#当要跳转的块和当前块不连续时,这个分支跳转才修复完成
if not idc.next_head(tb_path[i][0][1]) == tb_path[i + 1][0][0]:
block_info[tb_path[i][0][0]]['finish'] = 1
j_code = ('jnz', 'jz')
jmp_patch(tb_path[i][0][1], tb_path[i + 1][0][0], j_code[ZF])- nop掉cmov指令
这样就基本去除了fla混淆
可以发现反混淆的结果并不是完全准确的
因为oacia大佬的反混淆脚本还存在缺陷,在我编译的源代码里是存在循环的,生成的trueblock分支跳转时的 ZF 标志位并不完全一致
并不能简单的通过patch jz与jnz就串联到一起
更知名的去除ollvm的脚本如d810与基于unicorn的优化deflat脚本以后再进行学习
字符串混淆sobf
移植到llvm17的ollvm被加入了sobf
动态分析或者用unicorn hook参数或者用frida hook
间接跳转还原ibr
(模拟执行获取跳转地址)再根据条件判断将jmp指令进行替换即可手动还原